최근 Tencent Artificial Intelligence Laboratory는 비디오 콘텐츠를 의미상, 시간적으로 일관된 오디오로 효율적으로 변환하도록 설계된 VTA-LDM이라는 새로운 모델을 출시했습니다. 이 모델의 핵심 기술은 생성된 오디오 및 비디오 콘텐츠를 완벽하게 일치시키는 "암시적 정렬"에 있으며, 오디오 생성의 품질과 적용 시나리오를 크게 향상시킵니다. 다운코드 편집자는 VTA-LDM 모델의 혁신과 응용 전망에 대한 심층적인 이해를 제공합니다.
텍스트-비디오 생성 기술이 크게 발전함에 따라 비디오 입력에서 의미상, 시간적으로 일관된 오디오 콘텐츠를 생성하는 방법이 연구자들 사이에서 뜨거운 주제가 되었습니다. 최근 Tencent 인공 지능 연구소 연구팀은 효율적인 오디오 생성 솔루션 제공을 목표로 하는 "암시적으로 정렬된 비디오를 오디오 생성으로"(VTA-LDM)라는 새로운 모델을 출시했습니다.
프로젝트 입구: https://top.aibase.com/tool/vta-ldm
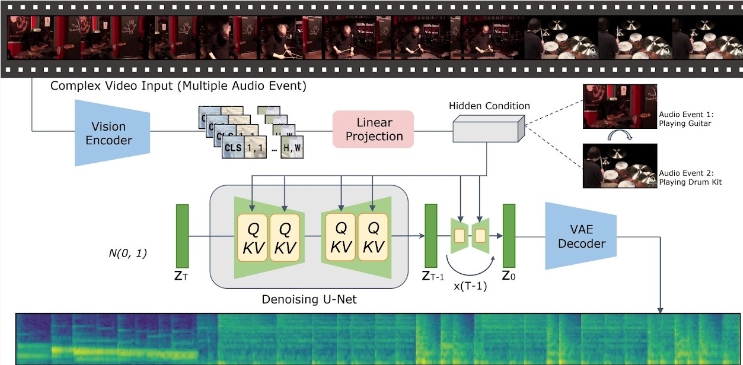
VTA-LDM 모델의 핵심 아이디어는 암시적 정렬 기술을 통해 생성된 오디오 및 비디오 콘텐츠를 의미적, 시간적으로 일치시키는 것입니다. 이 방법은 오디오 생성 품질을 향상시킬 뿐만 아니라 비디오 생성 기술의 적용 시나리오를 확장합니다. 연구팀은 생성된 오디오의 정확성과 일관성을 보장하기 위해 모델 설계에 대한 심층적인 탐색을 수행하고 다양한 기술적 수단을 결합했습니다.
이 연구는 시각적 인코더, 보조 임베딩 및 데이터 증대 기술이라는 세 가지 주요 측면에 중점을 둡니다. 연구팀은 먼저 기본 모델을 확립하고 이를 기반으로 수많은 절제 실험을 수행하여 다양한 시각적 인코더와 보조 임베딩이 생성 효과에 미치는 영향을 평가했습니다. 이러한 실험의 결과는 해당 모델이 생성 품질 및 비디오와 오디오의 동시 정렬 측면에서 우수한 성능을 발휘하여 현재 기술의 최전선에 도달했음을 보여줍니다.
추론 측면에서 사용자는 비디오 클립을 지정된 데이터 디렉터리에 넣고 제공된 추론 스크립트를 실행하여 해당 오디오 콘텐츠를 생성하기만 하면 됩니다. 연구팀은 또한 사용자가 생성된 오디오를 원본 비디오와 병합하여 애플리케이션의 편의성을 더욱 향상시킬 수 있는 도구 세트를 제공합니다.
VTA-LDM 모델은 현재 다양한 연구 요구 사항을 충족하기 위해 여러 가지 모델 버전을 제공합니다. 이러한 모델은 기본 모델과 다양한 고급 모델을 다루며 사용자에게 다양한 실험 및 응용 시나리오에 적응할 수 있는 유연한 선택을 제공하는 것을 목표로 합니다.
VTA-LDM 모델의 출시는 비디오-오디오 생성 분야에서 중요한 진전을 의미합니다. 연구원들은 이 모델을 사용하여 관련 기술 개발을 촉진하고 보다 풍부한 응용 가능성을 창출하기를 희망합니다.
## 하이라이트:
VTA-LDM 모델의 출현은 비디오 및 오디오 생성 분야에 새로운 혁신을 가져왔습니다. 효율적이고 편리한 작동 방법과 강력한 기능은 향후 더 넓은 응용 가능성을 예고합니다. 지속적인 기술 개발로 인해 VTA-LDM 모델은 더 많은 분야에서 중요한 역할을 할 것으로 믿어집니다.