다운코드 편집기가 큰 소식을 가져왔습니다! 혁신적인 Transformer 가속 기술인 FlashAttention-3가 공식 출시되었습니다! 이 기술은 대규모 언어 모델(LLM)의 추론 속도와 비용을 혁신하여 전례 없는 효율성 향상을 달성할 것입니다. 속도는 1.5~2배 향상되고, 저정밀도(FP8) 연산은 높은 정확도를 유지하며, 장문 처리 능력이 대폭 강화되어 AI 응용에 새로운 가능성을 열어줄 것입니다! 이 획기적인 기술에 대해 자세히 살펴보겠습니다.
새로운 Transformer 가속 기술인 FlashAttention-3이 출시되었습니다! 이것은 단순한 업그레이드가 아니라 추론 속도가 급격히 향상되고 LLM(대형 언어 모델)의 비용이 급락할 것을 예고합니다!
먼저 FlashAttention-3에 대해 이야기해 보겠습니다. 이전 버전과 비교하면 이는 단순히 샷건 변경일 뿐입니다.
GPU 활용도가 크게 향상되었습니다. FlashAttention-3을 사용하여 대규모 언어 모델을 훈련하고 실행하면 속도가 1.5~2배 더 빨라집니다. 이 효율성은 놀랍습니다!
낮은 정밀도, 높은 성능: 정확도를 유지하면서 낮은 정밀도 숫자(FP8)로도 실행할 수 있다는 것은 무엇을 의미합니까? 성능 저하 없이 비용이 절감됩니다!
긴 텍스트를 처리하는 것은 식은 죽 먹기입니다. FlashAttention-3은 이전에는 상상할 수 없었던 긴 텍스트를 처리하는 AI 모델의 능력을 크게 향상시킵니다.
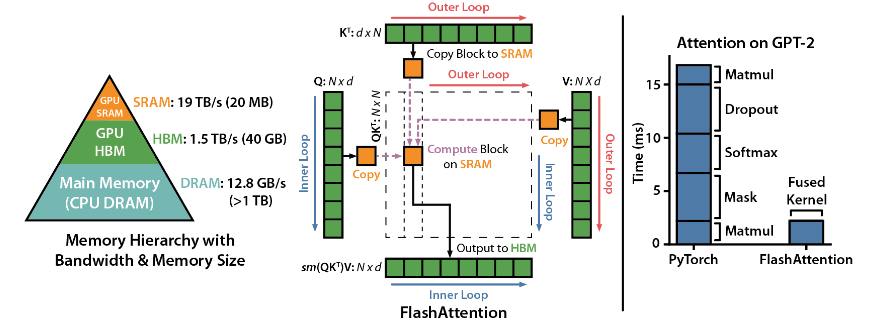
FlashAttention은 Dao-AILab에서 개발한 오픈 소스 라이브러리로, 두 개의 무거운 논문을 기반으로 하며 딥 러닝 모델에서 Attention 메커니즘의 최적화된 구현을 제공합니다. 이 라이브러리는 특히 대규모 데이터 세트와 긴 시퀀스를 처리하는 데 적합합니다. 메모리 소비와 시퀀스 길이 사이에는 선형 관계가 있어 기존의 2차 관계보다 훨씬 효율적입니다.
기술적인 하이라이트:
고급 기술 지원: 로컬 어텐션, 결정론적 역전파, ALiBi 등. 이러한 기술은 모델의 표현력과 유연성을 더 높은 수준으로 끌어올립니다.
Hopper GPU 최적화: FlashAttention-3는 Hopper GPU에 대한 지원을 특별히 최적화했으며 성능이 1.5포인트 이상 향상되었습니다.
설치 및 사용 용이성: CUDA11.6 및 PyTorch1.12 이상을 지원하며 Linux 시스템에서 pip 명령을 사용하여 쉽게 설치할 수 있습니다. Windows 사용자는 더 많은 테스트가 필요할 수 있지만 시도해 볼 가치가 있습니다.
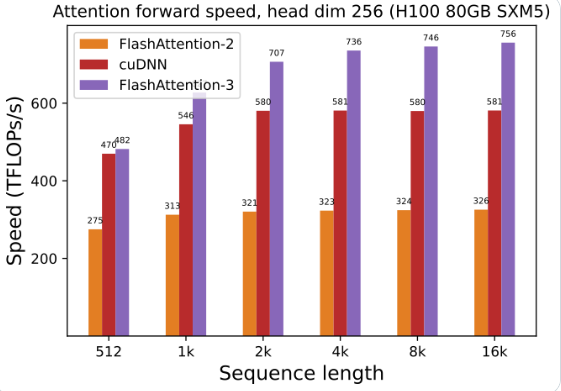
핵심 기능:
효율적인 성능: 최적화된 알고리즘은 특히 긴 시퀀스 데이터 처리의 경우 컴퓨팅 및 메모리 요구 사항을 크게 줄이고 성능 향상을 육안으로 확인할 수 있습니다.
메모리 최적화: 기존 방법에 비해 FlashAttention은 메모리를 덜 소비하며 선형 관계로 인해 메모리 사용량이 더 이상 문제가 되지 않습니다.
고급 기능: 다양한 고급 기술을 통합하면 모델 성능과 적용 범위가 크게 향상됩니다.
사용 편의성 및 호환성: 간단한 설치 및 사용 가이드와 다중 GPU 아키텍처 지원을 통해 FlashAttention-3를 다양한 프로젝트에 신속하게 통합할 수 있습니다.
프로젝트 주소: https://github.com/Dao-AILab/flash-attention
FlashAttention-3의 출현은 의심할 여지없이 대규모 언어 모델의 적용 및 개발을 가속화하고 인공 지능 분야에 새로운 혁신을 가져올 것입니다. 효율적인 성능과 사용 용이성은 개발자에게 이상적인 선택입니다. 서둘러서 경험해보세요!