Downcodes의 편집자는 VLM(시각 언어 모델)에 대한 진실을 여러분과 함께 공개할 것입니다! VLM이 인간처럼 이미지를 "이해"할 수 있다고 생각하시나요? 진실은 그렇게 간단하지 않습니다. 이 기사에서는 이미지 이해에 있어서 VLM의 한계를 깊이 탐구하고 일련의 실험 결과를 통해 VLM과 인간의 시각 능력 사이의 큰 격차를 보여줄 것입니다. VLM에 대한 이해를 뒤집을 준비가 되셨습니까?
AI 분야의 이 작은 전문가들은 텍스트를 읽을 수 있을 뿐만 아니라 그림도 "볼" 수 있습니다. 하지만 오늘은 그들이 우리 인간처럼 이미지를 실제로 '보고' 이해할 수 있는지 알아보기 위해 그들의 '속옷'을 살펴보겠습니다.
우선, VLM이 무엇인지에 대한 몇 가지 대중적인 과학을 알려 드리고자 합니다. 간단히 말해서 GPT-4o 및 Gemini-1.5Pro와 같은 대규모 언어 모델로 이미지 및 텍스트 처리 성능이 매우 뛰어나며 많은 시각적 이해 테스트에서도 높은 점수를 얻습니다. 하지만 이러한 높은 점수에 속지 마세요. 오늘은 그 점수가 정말 그렇게 멋진지 알아보겠습니다.
연구원들은 인간에게 매우 간단한 7가지 작업이 포함된 BlindTest라는 테스트 세트를 설계했습니다. 예를 들어 두 원이 겹치는지, 두 선이 교차하는지 확인하거나 올림픽 로고에 원이 몇 개 있는지 계산해 보세요. 이러한 작업을 유치원 아이들도 쉽게 처리할 수 있을 것 같나요? 하지만 이 VLM의 성능은 그다지 인상적이지 않습니다.
결과는 충격적입니다. BlindTest에서 소위 고급 모델의 평균 정확도는 56.20%에 불과하며 최고의 Sonnet-3.5는 73.77%의 정확도를 가지고 있습니다. 이것은 청화대, 북경대에 합격할 수 있다고 주장하지만 알고 보니 초등학교 수학 문제도 제대로 풀지 못하는 우등생과 같습니다.

왜 이런 일이 일어나는가? 연구원들은 VLM이 이미지를 처리할 때 근시와 같아서 세부 사항을 명확하게 볼 수 없기 때문일 수 있다고 분석했습니다. 이미지의 전반적인 흐름을 대략적으로 알 수는 있지만, 두 그래픽이 교차하는지, 겹치는지 등 정확한 공간 정보에 대해서는 혼란을 겪는다.
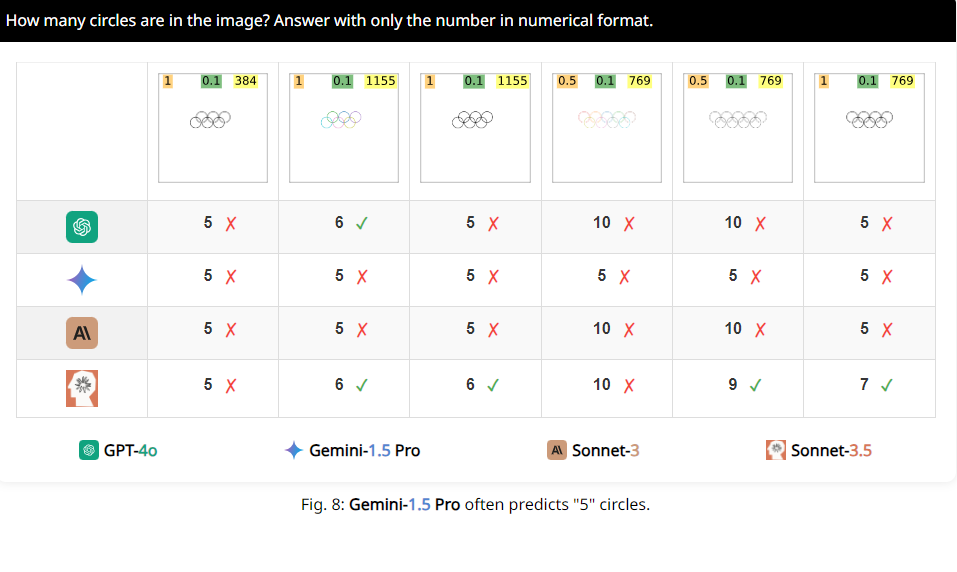
예를 들어, 연구원들은 VLM에 두 개의 원이 겹치는지 여부를 확인하도록 요청했고, 두 개의 원이 수박만큼 크더라도 이 모델은 여전히 질문에 100% 정확하게 대답할 수 없다는 것을 발견했습니다. 또한 올림픽 로고에 있는 원의 개수를 세어보라고 하면 그 성능을 설명하기가 어렵습니다.
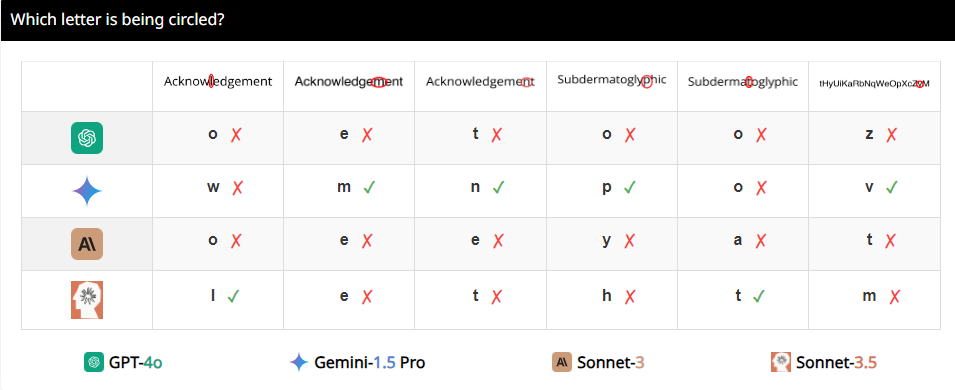
더 흥미롭게도 연구원들은 이러한 VLM이 계산할 때 숫자 5를 특별히 선호하는 것 같다는 사실도 발견했습니다. 예를 들어 올림픽 로고에 있는 원의 수가 5개를 초과하면 '5'라고 대답하는 경향이 있는데 이는 올림픽 로고에 원이 5개 있고 이 숫자에 특히 익숙하기 때문일 수 있습니다.
좋습니다. 이렇게 말했지만 여러분은 겉으로 보기에 키가 큰 VLM에 대해 새로운 이해를 갖고 계십니까? 사실 VLM은 인간의 수준에 도달하기에는 아직 시각적 이해에 많은 한계가 있습니다. 그러니 다음에 누군가 AI가 인간을 완전히 대체할 수 있다는 말을 들으면 웃을 수도 있습니다.
논문 주소: https://arxiv.org/pdf/2407.06581
프로젝트 페이지: https://vlmsareblind.github.io/
요약하자면, VLM은 이미지 인식 분야에서 상당한 발전을 이루었지만 정확한 공간 추론 능력에는 여전히 큰 단점이 있습니다. 이번 연구는 AI 기술에 대한 평가가 단지 높은 점수에만 의존할 수는 없으며, 맹목적인 낙관을 피하기 위해서는 AI 기술의 한계에 대한 깊은 이해가 필요하다는 점을 상기시킨다. 앞으로 VLM이 시각적 이해에 획기적인 발전을 이루기를 기대합니다!