다운코드 편집자는 Google DeepMind: 전문가 혼합(MoE)의 획기적인 연구에 대해 알아보도록 안내합니다. 이 연구는 Transformer 아키텍처에서 혁신적인 진전을 이루었습니다. 그 핵심은 제품 핵심 기술을 사용하여 계산 비용과 매개변수 수의 균형을 유지함으로써 효율성을 유지하면서 모델 잠재력을 크게 향상시키는 매개변수 효율적인 전문가 검색 메커니즘에 있습니다. 이 연구는 극단적인 MoE 설정을 탐구할 뿐만 아니라 학습 지수 구조가 백만 명 이상의 전문가에게 효과적으로 전달될 수 있음을 처음으로 입증하여 AI 분야에 새로운 가능성을 제공합니다.
Google DeepMind가 제안한 백만 명의 전문가 Mixture 모델은 Transformer 아키텍처에서 혁신적인 조치를 취한 연구입니다.
백만 명의 마이크로 전문가로부터 희박한 검색을 수행할 수 있는 모델을 상상해 보십시오. 이것이 공상 과학 소설의 줄거리와 약간 비슷합니까? 그러나 이것이 바로 DeepMind의 최신 연구에서 보여주는 것입니다. 이 연구의 핵심은 제품 키 기술을 활용하여 계산 비용을 매개변수 수에서 분리함으로써 계산 효율성을 유지하면서 Transformer 아키텍처의 더 큰 잠재력을 발휘하는 매개변수 효율적인 전문가 검색 메커니즘입니다.
이 작업의 하이라이트는 극단적인 MoE 설정을 탐색할 뿐만 아니라 학습된 인덱스 구조를 백만 명 이상의 전문가에게 효율적으로 전달할 수 있음을 처음으로 입증했다는 것입니다. 이는 마치 대규모 군중 속에서 문제를 해결할 수 있는 몇 명의 전문가를 빠르게 찾는 것과 같으며, 이 모든 것은 제어 가능한 컴퓨팅 비용을 전제로 수행됩니다.
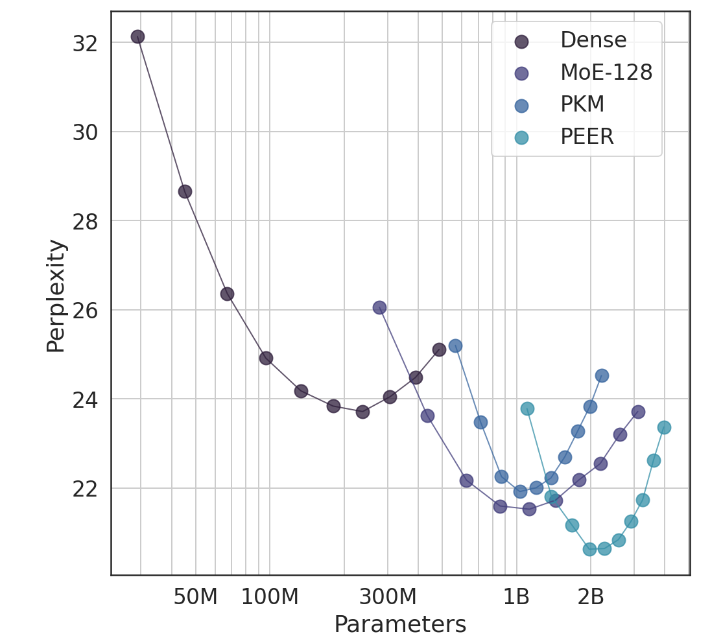
실험에서 PEER 아키텍처는 뛰어난 컴퓨팅 성능을 보여주었으며 밀도가 높은 FFW, 거친 MoE 및 PKM(제품 키 메모리) 레이어보다 더 효율적이었습니다. 이는 이론적 승리일 뿐만 아니라 실제 적용에 있어서도 큰 도약입니다. 실증적 결과를 통해 언어 모델링 작업에서 PEER의 우수한 성능을 확인할 수 있었으며, 전문가 수와 활성 전문가 수를 조정하여 절제 실험에서도 PEER의 성능을 확인할 수 있었습니다. 모델이 크게 개선되었습니다.
이 연구의 저자인 Xu He(Owen)는 Google DeepMind의 연구 과학자입니다. 그의 단독 탐구는 의심할 여지 없이 AI 분야에 새로운 계시를 가져왔습니다. 그가 보여준 것처럼 개인화되고 지능적인 방법을 통해 전환율을 크게 향상시키고 사용자를 유지할 수 있으며 이는 AIGC 분야에서 특히 중요합니다.
논문 주소: https://arxiv.org/abs/2407.04153
전체적으로 Google DeepMind의 100만 전문가 하이브리드 모델 연구는 대규모 언어 모델 구축을 위한 새로운 아이디어를 제공합니다. 효율적인 전문가 검색 메커니즘과 우수한 실험 결과는 향후 AI 모델 개발에 큰 잠재력을 나타냅니다. Downcodes의 편집자는 더욱 유사한 획기적인 연구 결과를 기대합니다!