Downcodes의 편집자가 큰 소식을 전해 드립니다! Cerebras Systems는 놀라운 속도와 극도로 경쟁력 있는 가격으로 AI 추론 분야의 게임 규칙을 완전히 바꿔 놓은 세계에서 가장 빠른 AI 추론 서비스인 Cerebras Inference를 출시했습니다. 다양한 AI 모델, 특히 대규모 언어 모델(LLM)을 처리하는 데 탁월한 성능을 발휘하며 10분의 1 또는 100분의 1의 저렴한 가격으로 기존 GPU 시스템보다 20배 빠릅니다. 이것이 AI 애플리케이션의 향후 개발에 어떤 영향을 미칠까요? 좀 더 자세히 살펴보겠습니다.
성능 AI 컴퓨팅 분야의 선구자인 Cerebras Systems는 AI 추론에 혁명을 일으킬 획기적인 솔루션을 도입했습니다. 2024년 8월 27일, 회사는 세계에서 가장 빠른 AI 추론 서비스인 Cerebras Inference의 출시를 발표했습니다. Cerebras Inference의 성능 지표는 기존 GPU 기반 시스템을 능가하며 매우 저렴한 비용으로 20배 빠른 속도를 제공하여 AI 컴퓨팅에 대한 새로운 벤치마크를 설정합니다.
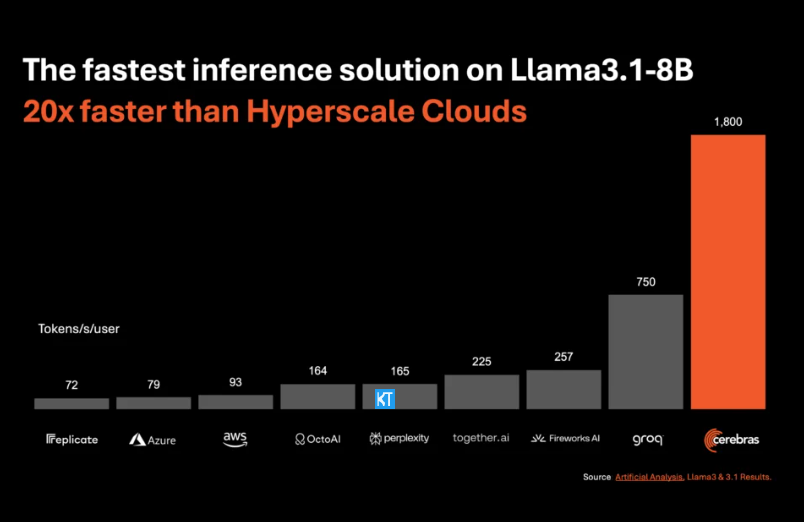
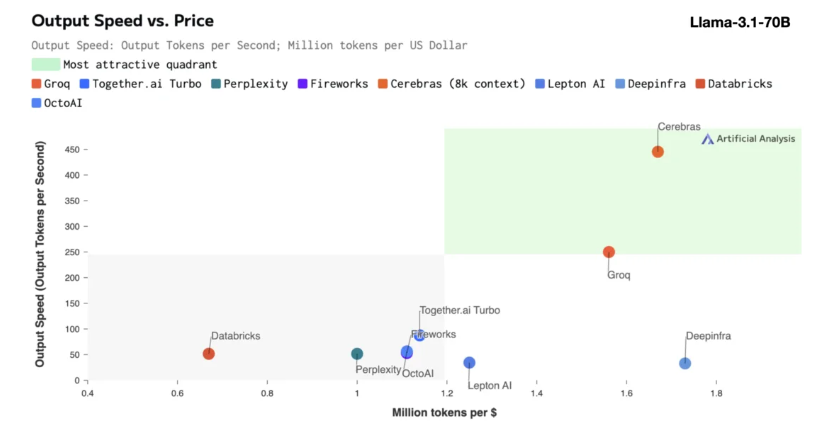
Cerebras 추론은 다양한 유형의 AI 모델, 특히 빠르게 발전하는 "대형 언어 모델"(LLM)을 처리하는 데 특히 적합합니다. 최신 Llama3.1 모델을 예로 들면, 8B 버전은 초당 1,800개의 토큰을 처리할 수 있는 반면, 70B 버전은 450개의 토큰을 처리할 수 있습니다. 이는 NVIDIA GPU 솔루션보다 20배 더 빠를 뿐만 아니라 가격도 더 경쟁력이 있습니다. Cerebras Inference의 가격은 백만 토큰당 10센트부터 시작하며, 70B 버전은 기존 GPU 제품과 비교하여 가격 대비 성능 비율이 100배 향상됩니다.
Cerebras Inference가 업계 최고의 정확도를 유지하면서 이 속도를 달성한다는 것은 인상적입니다. 다른 속도 우선 솔루션과 달리 Cerebras는 항상 16비트 도메인에서 추론을 수행하므로 성능 향상으로 인해 AI 모델 출력 품질이 저하되지 않습니다. Artificial Analytics의 CEO인 Micha Hill-Smith는 Cerebras가 Meta의 Llama3.1 모델에서 초당 1,800개 이상의 출력 토큰 속도를 달성하여 신기록을 세웠다고 말했습니다.
AI 추론은 AI 컴퓨팅에서 가장 빠르게 성장하는 부문으로, 전체 AI 하드웨어 시장의 약 40%를 차지합니다. Cerebras가 제공하는 것과 같은 고속 AI 추론은 마치 광대역 인터넷의 출현과 같아서 AI 애플리케이션의 새로운 기회를 열고 새로운 시대를 여는 것입니다. 개발자는 Cerebras Inference를 사용하여 지능형 에이전트 및 지능형 시스템과 같은 복잡한 실시간 성능이 필요한 차세대 AI 애플리케이션을 구축할 수 있습니다.
Cerebras Inference는 무료 계층, 개발자 계층 및 엔터프라이즈 계층이라는 세 가지 합리적인 가격의 서비스 계층을 제공합니다. 무료 등급은 넉넉한 사용 제한이 있는 API 액세스를 제공하므로 광범위한 사용자에게 이상적입니다. 개발자 계층은 유연한 서버리스 배포 옵션을 제공하는 반면, 엔터프라이즈 계층은 지속적인 워크로드가 있는 조직에 맞춤형 서비스와 지원을 제공합니다.
핵심 기술 측면에서 Cerebras Inference는 업계 최고의 Wafer Scale Engine3(WSE-3)에 의해 구동되는 CerebrasCS-3 시스템을 사용합니다. 이 AI 프로세서는 규모와 속도 면에서 비교할 수 없을 만큼 뛰어나며 NVIDIA H100보다 7,000배 더 많은 메모리 대역폭을 제공합니다.
Cerebras Systems는 AI 컴퓨팅 분야의 트렌드를 선도할 뿐만 아니라 의료, 에너지, 정부, 과학 컴퓨팅, 금융 서비스 등 다양한 산업 분야에서 중요한 역할을 하고 있습니다. Cerebras는 지속적으로 기술 혁신을 발전시켜 다양한 분야의 조직이 복잡한 AI 문제를 해결할 수 있도록 돕고 있습니다.
가장 밝은 부분:
Cerebras Systems의 서비스 속도는 20배 향상되고, 가격 경쟁력도 향상되었으며, AI 추론의 새로운 시대를 열었습니다.
다양한 AI 모델을 지원하며, 특히 LLM(대형 언어 모델)에서 좋은 성능을 발휘합니다.
개발자와 기업 사용자가 유연하게 선택할 수 있도록 세 가지 서비스 수준이 제공됩니다.
전체적으로 Cerebras Inference의 출현은 AI 추론 분야에서 중요한 이정표입니다. 뛰어난 성능과 경제성은 AI 애플리케이션의 광범위한 대중화와 혁신적인 개발을 촉진할 것이며 업계의 관심과 기대를 받을 만합니다! 다운코드 편집자는 계속해서 더 많은 최첨단 기술 정보를 제공할 것입니다.