LLM(대형 언어 모델) 학습에서는 체크포인트 메커니즘이 매우 중요합니다. 학습 중단으로 인한 막대한 손실을 효과적으로 방지할 수 있기 때문입니다. 그러나 기존 체크포인트 시스템은 I/O 병목 현상이 발생하는 경우가 많아 비효율적입니다. 이를 위해 ByteDance와 홍콩 대학교의 과학자들은 LLM 교육의 효율성을 크게 향상시킬 수 있는 ByteCheckpoint라는 새로운 체크포인트 시스템을 제안했습니다.
데이터와 알고리즘이 지배하는 디지털 세상에서 인공지능 성장의 모든 단계는 핵심 요소인 체크포인트와 분리될 수 없습니다. 사람들의 마음을 이해하고 질문에 유창하게 대답할 수 있는 대규모 언어 모델을 훈련할 때 이 모델은 매우 똑똑하지만, 또한 많이 먹는 동물이며 이를 먹이기 위해 막대한 컴퓨팅 리소스가 필요하다고 상상해 보십시오. 훈련 과정에서 갑작스러운 정전이나 하드웨어 장애가 발생하면 손실이 엄청납니다. 이때 체크포인트는 마치 타임머신과도 같아 모든 것이 이전의 안전 상태로 돌아가서 끝나지 않은 작업을 계속할 수 있게 해준다.
그러나 타임머신 자체에도 세심한 설계가 필요했습니다. ByteDance와 홍콩 대학의 과학자들은 "ByteCheckpoint: LLM 개발을 위한 통합 체크포인트 시스템"이라는 논문에서 새로운 체크포인트 시스템인 ByteCheckpoint를 소개했습니다. 이는 단순한 백업 도구일 뿐만 아니라 대규모 언어 모델의 학습 효율성을 크게 향상시킬 수 있는 아티팩트이기도 합니다.
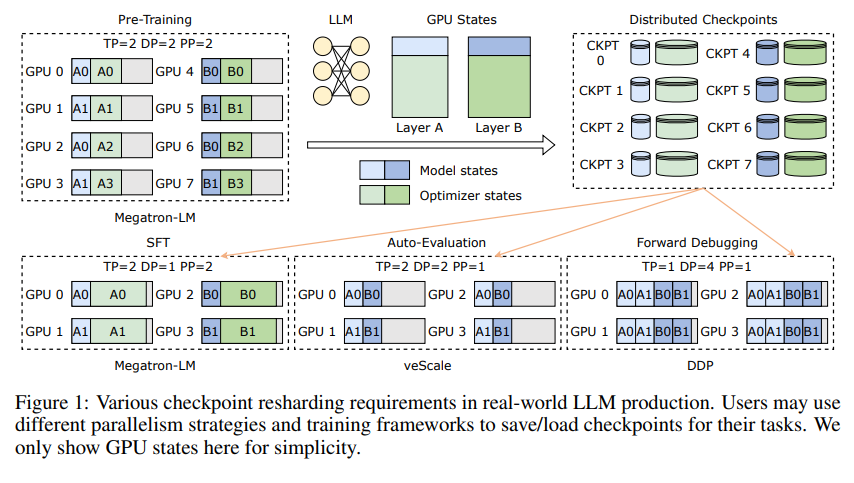
먼저, 대규모 언어 모델(LLM)이 직면한 과제를 이해해야 합니다. 이러한 모델이 큰 이유는 엄청난 양의 정보를 처리하고 기억해야 하기 때문이며, 이로 인해 높은 훈련 비용, 많은 리소스 소비, 취약한 내결함성 등의 문제가 발생합니다. 한번 오작동이 발생하면 장기간의 훈련이 만족스럽지 못할 수 있습니다.
체크포인트 시스템은 모델의 스냅샷과 같아서 훈련 과정에서 정기적으로 상태를 저장하므로, 문제가 발생하더라도 빠르게 최신 상태로 복원하여 손실을 줄일 수 있습니다. 하지만 기존 체크포인트 시스템은 대형 모델을 처리할 때 I/O(입력/출력) 병목 현상으로 인해 비효율성이 발생하는 경우가 많습니다.
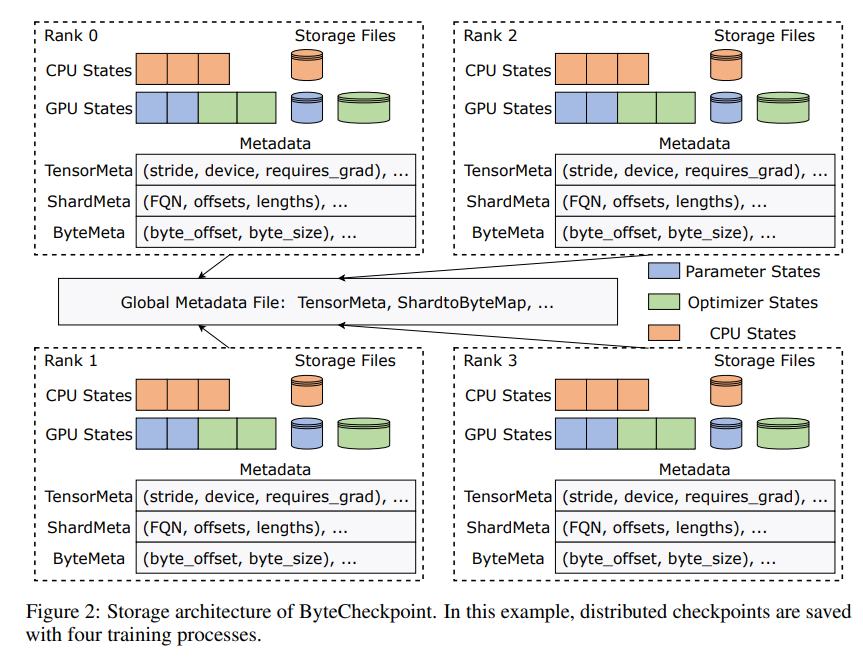
ByteCheckpoint의 혁신은 데이터와 메타데이터를 분리하고 다양한 병렬 구성 및 교육 프레임워크에서 체크포인트를 보다 유연하게 처리하는 새로운 스토리지 아키텍처의 채택에 있습니다. 더 좋은 점은 자동 온라인 체크포인트 리샤딩을 지원하므로 학습을 중단하지 않고도 다양한 하드웨어 환경에 맞게 체크포인트를 동적으로 조정할 수 있다는 것입니다.
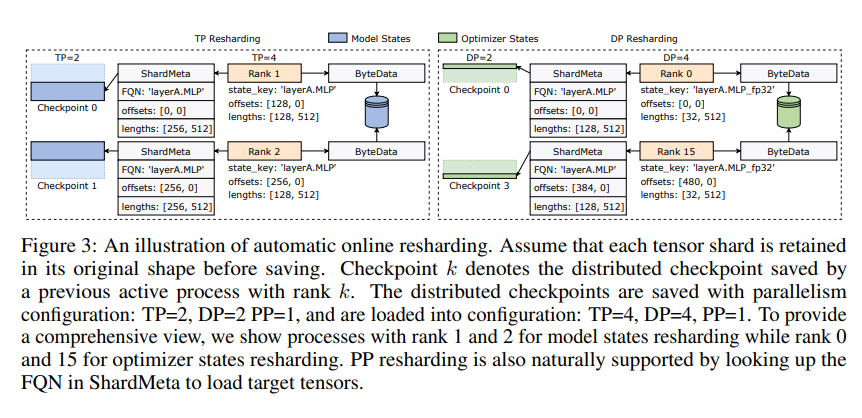
ByteCheckpoint는 또한 비동기식 텐서 병합이라는 핵심 기술을 도입합니다. 이를 통해 서로 다른 GPU에 고르지 않게 분산된 텐서를 효율적으로 처리할 수 있으므로 체크포인트가 다시 샤딩될 때 모델의 무결성과 일관성이 영향을 받지 않습니다.
체크포인트 저장 및 로드 속도를 향상시키기 위해 ByteCheckpoint는 정교한 저장/로드 파이프라인, 핑퐁 메모리 풀, 작업 부하 균형 저장 및 제로 중복 로드 등과 같은 일련의 I/O 성능 최적화 조치도 통합합니다. , 이는 훈련 과정 중 대기 시간을 크게 줄여줍니다.
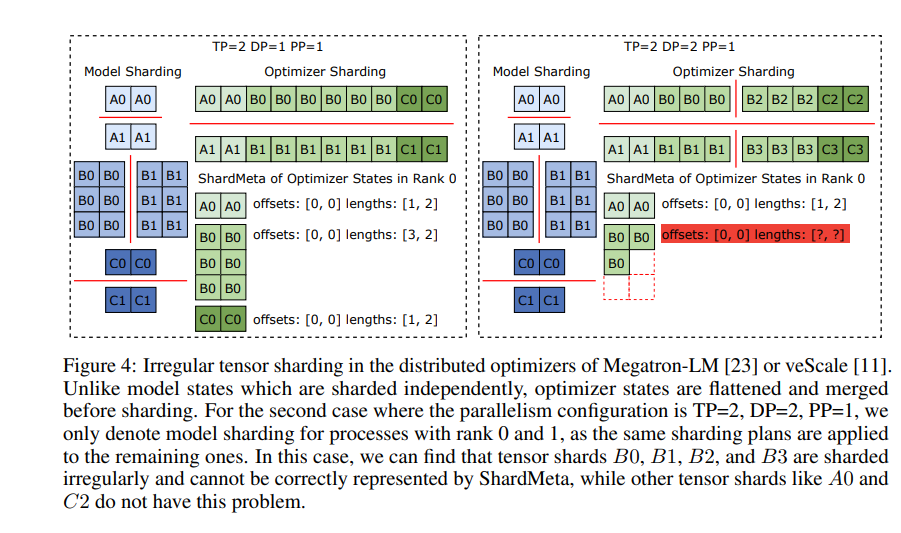
실험적 검증을 통해 기존 방법에 비해 ByteCheckpoint의 체크포인트 저장 및 로딩 속도가 각각 수십 배, 심지어 수백 배 증가하여 대규모 언어 모델의 학습 효율성이 크게 향상되었습니다.
ByteCheckpoint는 체크포인트 시스템일 뿐만 아니라 대규모 언어 모델의 훈련 과정에서 강력한 보조자이기도 합니다. 이는 보다 효율적이고 안정적인 AI 훈련의 핵심입니다.
논문 주소: https://arxiv.org/pdf/2407.20143
Downcodes의 편집자는 다음과 같이 요약합니다. ByteCheckpoint의 출현은 LLM 교육에서 낮은 체크포인트 효율성 문제를 해결하고 AI 개발을 위한 강력한 기술 지원을 제공한다는 점에 주목할 가치가 있습니다!