Downcodes의 편집자는 흥미로운 AI 실험을 안내합니다. Reddit 사용자 @zefman은 다양한 언어 모델(LLM)이 실시간으로 체스를 둘 수 있는 플랫폼을 구축했습니다! 이 실험은 편안하고 흥미로운 방식으로 체스를 두는 각 LLM의 능력을 평가합니다. 결과는 예상치 못한 것입니다. 한 번 살펴보겠습니다.
최근 Reddit 사용자 @zefman은 사용자에게 이러한 모델의 성능을 평가할 수 있는 재미있고 쉬운 방법을 제공한다는 목표로 실시간으로 다양한 언어 모델(LLM)을 체스와 대결할 수 있는 플랫폼을 설정하는 흥미로운 실험을 수행했습니다.
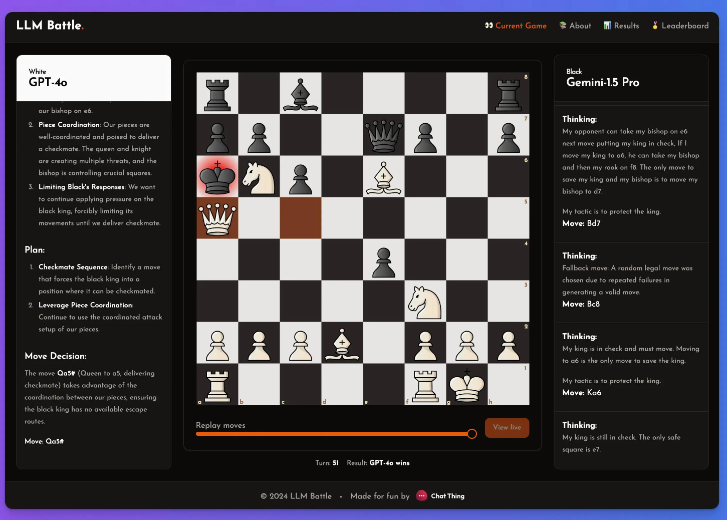
이 모델들이 체스를 잘 두지 않는다는 것은 비밀이 아니지만, 그럼에도 불구하고 그는 이 실험에서 몇 가지 주목할 만한 하이라이트가 있다고 느꼈습니다.
이 실험에서 @zefman은 여러 최신 모델에 특별한 관심을 기울였으며 그중 GPT-4o가 가장 뛰어난 성능을 발휘하여 의심할 여지 없이 가장 강력한 플레이어가 되었습니다. 동시에 @zefman은 Claude 및 Gemini와 같은 다른 모델과도 비교하여 성능 차이를 관찰한 결과 각 모델의 사고 및 추론 과정이 매우 흥미롭다는 사실을 발견했습니다. 이 플랫폼을 통해 누구나 각 단계의 의사결정 이면과 모델이 체스 게임을 분석하는 방법을 확인할 수 있습니다.
@zefman이 디자인한 체스 게임 표시 방법은 매우 간단합니다. 각 모델이 동일한 체스판 상태에 직면하면 현재 체스 게임 상태, FEN(체스 위치 표현) 및 이전 두 동작을 포함하여 동일한 프롬프트가 표시됩니다. 이 접근 방식을 사용하면 각 모델의 결정이 동일한 정보를 기반으로 하여 보다 공정한 비교가 가능해집니다.
각 모델은 ASCI, FEN의 보드 상태와 이전 두 가지 동작 및 생각으로 업데이트되는 동일한 프롬프트를 사용합니다. 예는 다음과 같습니다.
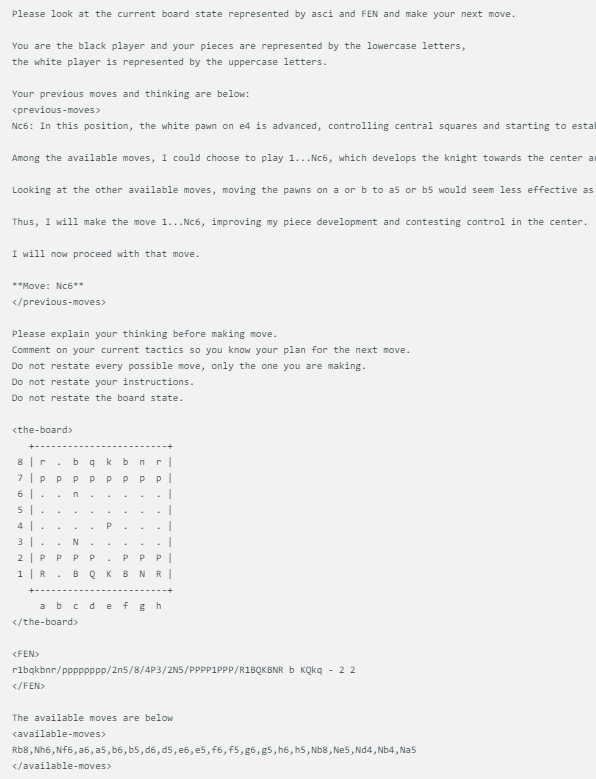
또한 @zefman은 경우에 따라, 특히 일부 약한 모델의 경우 잘못된 동작을 여러 번 선택할 수 있다는 점에도 주목했습니다. 이 문제를 해결하기 위해 그는 모델들에게 5번의 재선택 기회를 주었습니다. 그래도 유효한 수를 선택하지 못한 경우 무작위로 유효한 수를 선택하여 게임을 계속 진행했습니다.
그는 다음과 같이 결론을 내렸습니다. GTP-4o는 체스에서 Gemini1.5pro를 꺾고 여전히 가장 강력합니다.
이 실험을 통해 우리는 체스 분야의 다양한 LLM 간의 차이점을 볼 수 있었을 뿐만 아니라 @zefman의 독창적인 디자인과 실험 정신도 보았습니다. LLM의 잠재력과 한계에 대해 더 깊이 이해하는 데 도움이 될 더 유사한 실험이 앞으로도 더 많이 이루어지기를 기대합니다!