Meta AI의 최신 프로젝트 Llama3가 큰 관심을 끌었습니다. Downcodes의 편집자가 해당 핵심 기술과 향후 개발 방향에 대해 심층적으로 설명합니다. Meta AI 연구원 Thomas Scialom은 최근 인터뷰를 통해 Llama3 개발 세부 사항을 공유하고 대규모 언어 모델 훈련에 존재하는 문제에 대한 고유한 통찰력을 제공했습니다. 그는 특히 Llama3 훈련에서 합성 데이터의 중요한 역할과 인간의 피드백을 효과적으로 사용하여 모델 성능을 향상시키는 방법을 강조했습니다. 이 기사에서는 Llama3의 훈련 방법, 응용 분야 및 향후 개발 계획을 자세히 설명하여 독자들에게 포괄적이고 심층적인 관점을 제시할 것입니다.
Meta AI의 연구원인 Thomas Scialom은 최근 인터뷰에서 최신 프로젝트인 Llama3에 대한 몇 가지 통찰력을 공유했습니다. 그는 웹에 있는 많은 양의 텍스트는 품질이 다양하다는 점을 직설적으로 지적하고, 이 데이터에 대한 교육은 자원 낭비라고 믿습니다. 따라서 Llama3의 훈련 과정은 사람이 작성한 답변에 의존하지 않고 전적으로 Llama2에서 생성된 합성 데이터를 기반으로 합니다.
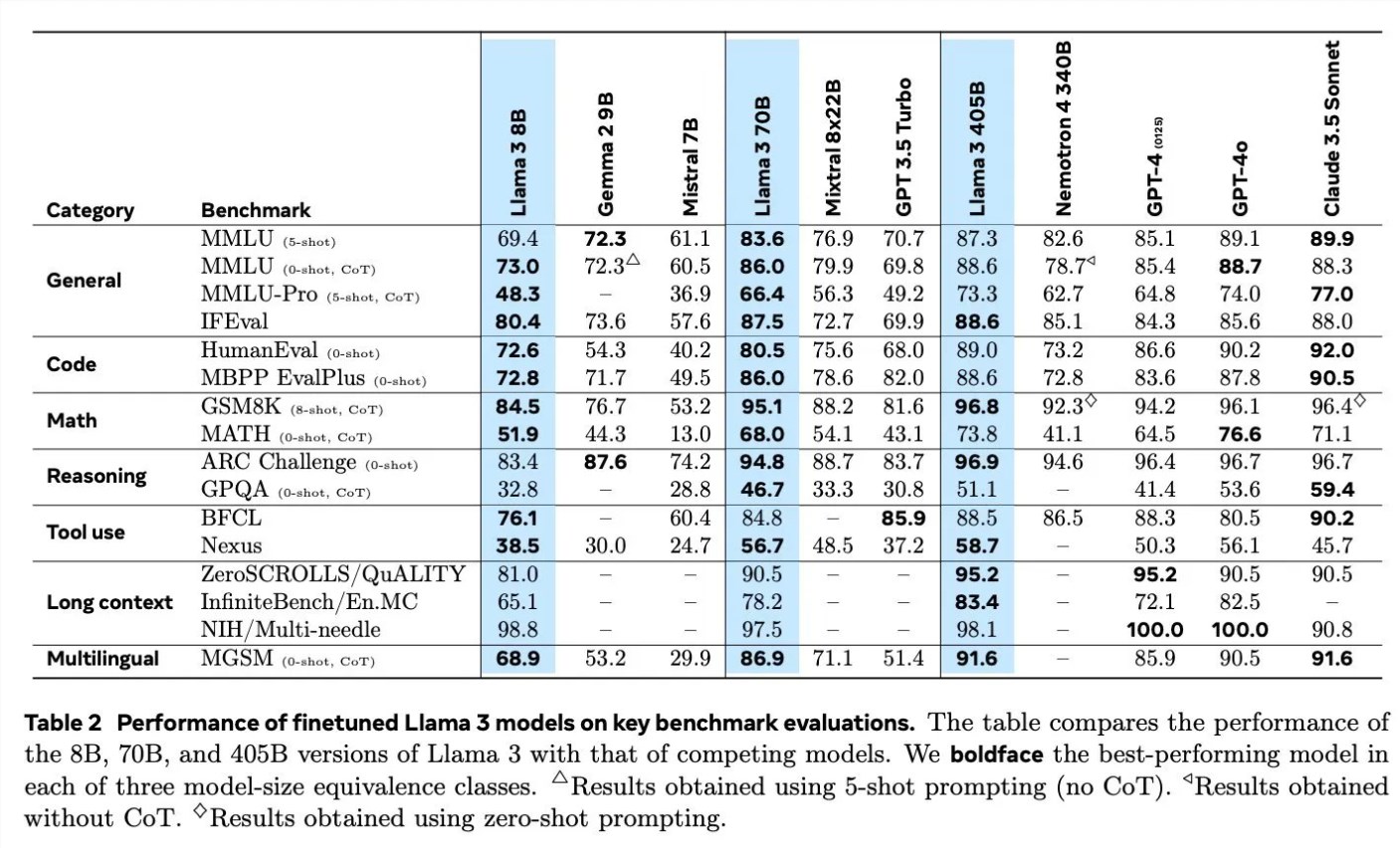
Scialom은 Llama3의 훈련 세부 사항을 논의할 때 다양한 분야에서 합성 데이터를 적용하는 방법을 자세히 설명했습니다. 예를 들어, 코드 생성 측면에서 그들은 코드 실행 피드백, 프로그래밍 언어 번역, 문서 역번역 등 세 가지 방법을 사용하여 합성 데이터를 생성했습니다. 수학적 추론 측면에서 그들은 데이터 생성에 대한 "단계별" 연구 접근 방식을 활용했습니다. 또한 Llama3는 다중 언어 처리에서 특히 중요한 고품질 인간 주석을 수집하기 위해 90% 다중 언어 토큰으로 계속 사전 학습됩니다.
긴 텍스트 처리도 Llama3의 초점이며, 긴 텍스트 질문 응답, 긴 문서 요약 및 코드 기반 추론을 처리하기 위해 합성 데이터를 사용합니다. 도구 사용 측면에서 Llama3은 단일, 중첩, 병렬 및 다중 라운드 함수 호출을 구현하기 위해 Brave 검색, Wolfram Alpha 및 Python 해석기에 대한 교육을 받았습니다.
Scialom은 또한 Llama3 훈련에서 인간 피드백을 통한 강화 학습(RLHF)의 중요성을 언급했습니다. 그들은 모델을 훈련하기 위해 인간의 선호도 데이터를 광범위하게 사용했으며, 처음부터 시작하는 것보다 인간이 선택을 하는 능력(예: 두 시 중 어느 것을 선호할지 선택하는 것)을 강조했습니다.
Meta는 6월에 Llama4의 훈련을 시작했으며 Scialom은 Llama4의 주요 초점이 지능형 에이전트에 맞춰질 것이라고 밝혔습니다. 또한 그는 더 많은 매개변수를 포함하고 가까운 시일 내에 출시될 예정인 다중 모드 버전의 Llama에 대해서도 언급했습니다.
Scialom의 인터뷰에서는 인공 지능 분야에서 Meta AI의 최신 진행 상황과 향후 개발 방향, 특히 합성 데이터와 인간 피드백을 사용하여 모델 성능을 향상시키는 방법을 보여줍니다.
Scialom의 인터뷰를 통해 Llama3의 데이터 활용 및 모델 훈련 혁신과 Meta AI의 대규모 언어 모델 분야에서의 지속적인 탐구에 대해 배웠습니다. Llama3의 성공적인 경험은 미래 인공지능 모델 개발에 귀중한 참고자료가 되며, 인공지능 기술이 보다 정확하고 효율적인 방향으로 발전할 것임을 시사합니다. 다운코드 편집자는 Llama4와 멀티모달 Llama의 출시를 기대하며, 인공지능 분야에서 Meta AI의 획기적인 발전에 계속해서 주목하고 있습니다.