메타컴퍼니의 대작 출시! 최대 1,280억 개의 매개변수 볼륨을 갖춘 최신 대형 언어 모델 Llama 3.1 405B를 오픈소스로 제공하며 성능은 여러 작업에서 GPT-4와 비슷합니다. 프로젝트 기획부터 최종 검토까지 1년간의 세심한 준비 끝에 Llama 3 시리즈 모델이 마침내 대중을 만났습니다. 이 오픈 소스에는 모델 자체뿐만 아니라 최적화된 사전 학습 데이터 처리, 사후 학습 데이터 품질 보증 및 효율적인 정량화 기술이 포함되어 있어 컴퓨팅 요구 사항을 줄이고 개발자가 더 쉽게 사용할 수 있습니다. 다운코드 편집자는 Llama 3.1 405B의 개선 사항과 주요 특징을 자세히 설명합니다.
어젯밤 Meta는 최신 대형 언어 모델 Llama3.1 405B의 오픈 소스를 발표했습니다. 이 큰 소식은 프로젝트 계획부터 최종 검토까지 1년간의 세심한 준비 끝에 Llama3 시리즈 모델이 마침내 대중을 만났다는 것을 의미합니다.
Llama3.1405B는 1,280억 개의 매개변수를 갖춘 다국어 도구 사용 모델입니다. 8K의 컨텍스트 길이로 사전 학습한 후 모델은 128K의 컨텍스트 길이로 추가 학습됩니다. Meta에 따르면 이 모델의 여러 작업 성능은 업계 최고의 GPT-4와 비슷합니다.
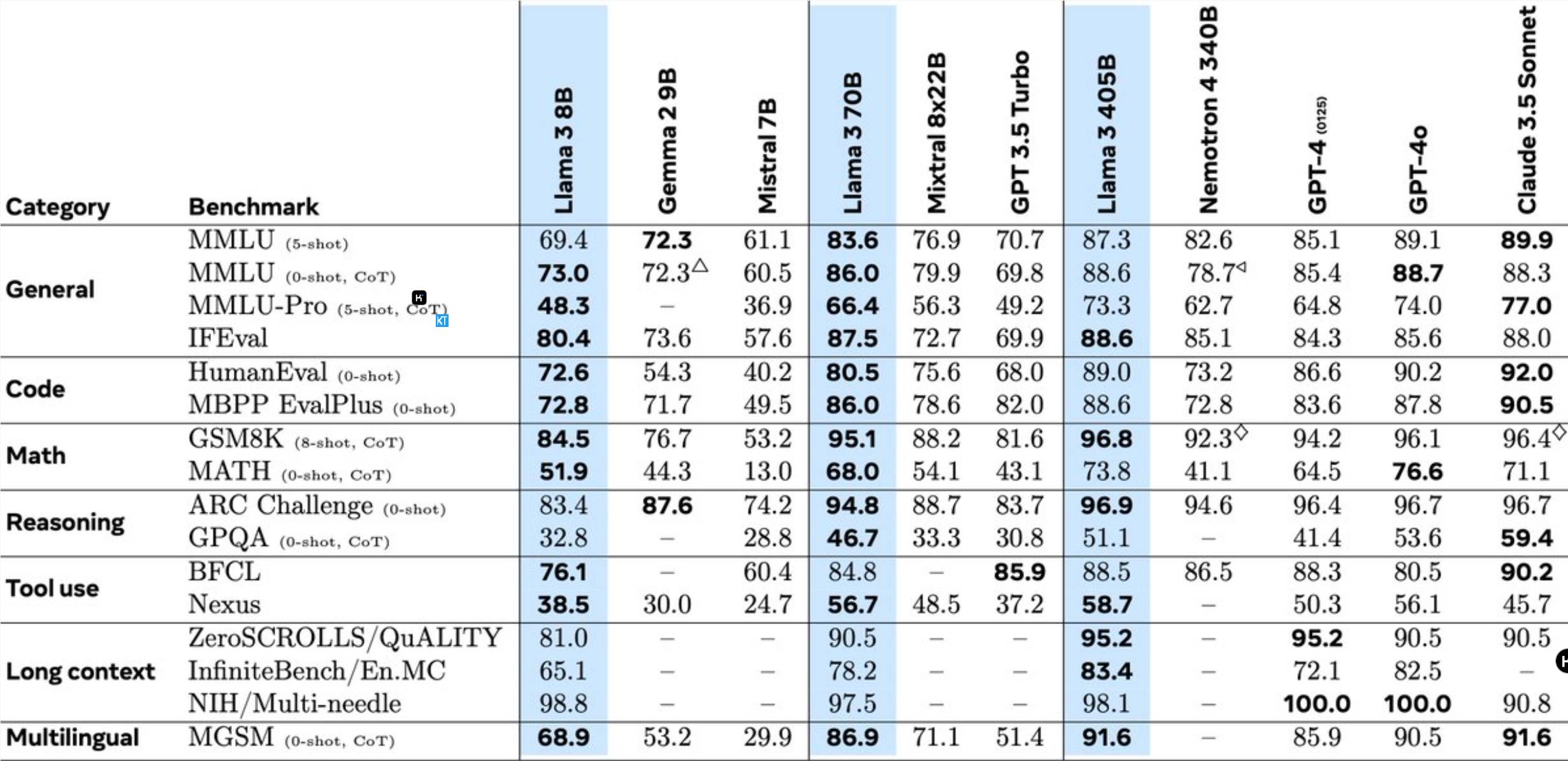
이전 Llama 모델과 비교하여 Meta는 여러 측면에서 최적화되었습니다.
405B 모델의 사전 훈련은 15.6조 개의 토큰과 3.8x10^25 부동 소수점 연산을 포함하는 엄청난 도전입니다. 이를 위해 Meta는 전체 학습 아키텍처를 최적화하고 16,000개 이상의 H100 GPU를 사용했습니다.
405B 모델의 대량 생산 추론을 지원하기 위해 Meta는 이를 16비트(BF16)에서 8비트(FP8)로 양자화하여 컴퓨팅 요구 사항을 크게 줄이고 단일 서버 노드에서 모델을 실행할 수 있도록 했습니다.
또한 Meta는 70B 및 8B 모델의 학습 후 품질을 향상시키기 위해 405B 모델을 사용합니다. 학습 후 단계에서 팀은 SFT(감독 미세 조정), 거부 샘플링, 직접 선호도 최적화를 포함한 여러 라운드의 정렬 프로세스를 통해 채팅 모델을 개선했습니다. 대부분의 SFT 샘플은 합성 데이터를 사용하여 생성된다는 점은 주목할 가치가 있습니다.
Llama3는 또한 모델이 이미지와 비디오를 인식하고 음성 상호 작용을 지원할 수 있도록 결합된 접근 방식을 사용하여 이미지, 비디오 및 음성 기능을 통합합니다. 그러나 이러한 기능은 아직 개발 중이며 아직 공식적으로 출시되지 않았습니다.
Meta는 또한 개발자가 Llama 모델의 출력을 사용하여 다른 모델을 개선할 수 있도록 라이선스 계약을 업데이트했습니다.
메타 연구원들은 “업계 최고의 인재들과 함께 AI의 최전선에서 일하고 연구 결과를 공개적이고 투명하게 발표하는 것은 매우 흥미롭다”고 말했다. 우리는 오픈 소스 모델이 가져올 혁신과 향후 Llama 시리즈 모델의 잠재력을 기대합니다!
이 오픈 소스 이니셔티브는 의심할 여지 없이 AI 분야에 새로운 기회와 도전을 가져오고 대규모 언어 모델 기술의 추가 개발을 촉진할 것입니다.
Llama 3.1 405B의 오픈소스는 대규모 언어 모델 기술의 발전을 크게 촉진하고 AI 분야에 더 많은 가능성을 가져올 것입니다. 우리는 개발자들이 이 모델을 기반으로 더욱 놀라운 애플리케이션을 개발할 수 있기를 기대합니다!