대규모 언어 모델의 효율성을 향상시키는 것은 항상 인공 지능 분야의 연구 핫스팟이었습니다. 최근 다름슈타트 공과대학 Aleph Alpha 및 기타 기관의 연구팀은 T-FREE라는 새로운 방법을 개발하여 대규모 언어 모델의 운영 효율성을 크게 향상시켰습니다. 이 방법은 희소 활성화를 위해 문자 트리플을 사용하여 임베딩 레이어 매개변수 수를 줄이고, 단어 간의 형태학적 유사성을 효과적으로 모델링하는 동시에 모델 성능을 보장하면서 컴퓨팅 리소스 소비를 크게 줄입니다. 이 획기적인 기술은 대규모 언어 모델의 적용에 새로운 가능성을 제공합니다.
연구팀은 최근 대규모 언어 모델의 운영 효율성을 급상승시킬 수 있는 T-FREE라는 흥미롭고 새로운 방법을 도입했습니다. Aleph Alpha, TU Darmstadt, hessian.AI 및 독일 인공 지능 연구 센터(DFKI)의 과학자들은 "태거 없는 희소 표현, 메모리 효율적인 임베딩이 가능합니다."라는 이름으로 이 놀라운 기술을 공동으로 출시했습니다.
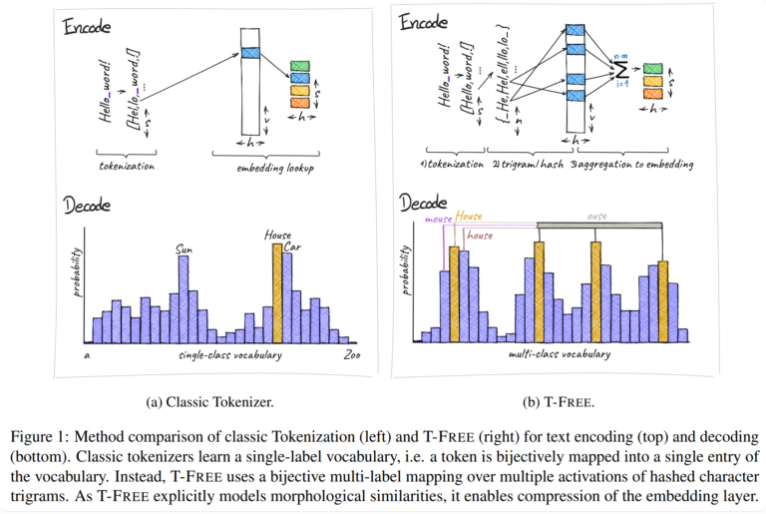
전통적으로 우리는 텍스트를 컴퓨터가 이해할 수 있는 숫자 형식으로 변환하기 위해 토크나이저를 사용했지만 T-FREE는 다른 경로를 선택했습니다. 이는 "트리플"이라고 부르는 문자 트리플을 사용하여 희소 활성화를 통해 단어를 모델에 직접 삽입합니다. 이러한 혁신적인 움직임의 결과로 임베딩 레이어의 매개변수 수는 무려 85% 이상 감소했으며, 텍스트 분류, 질문 답변 등의 작업을 처리할 때 모델 성능에는 전혀 영향을 미치지 않았습니다.
T-FREE의 또 다른 하이라이트는 단어 간의 형태학적 유사성을 매우 영리하게 모델링한다는 것입니다. 우리가 일상에서 자주 접하는 'house', 'houses', 'domestic'이라는 단어처럼 T-FREE는 이러한 유사한 단어를 모델에서 보다 효과적으로 표현할 수 있습니다. 연구원들은 더 높은 압축률을 달성하려면 유사한 단어가 서로 더 가깝게 삽입되어야 한다고 믿습니다. 따라서 T-FREE는 임베딩 레이어의 크기를 줄일 뿐만 아니라 텍스트의 평균 인코딩 길이를 56%까지 줄입니다.
더욱 언급할 가치가 있는 점은 T-FREE가 서로 다른 언어 간의 전이 학습에서 특히 뛰어난 성능을 발휘한다는 것입니다. 한 실험에서 연구원들은 처음에는 영어로 훈련한 다음 독일어로 훈련한 30억 개의 매개변수가 있는 모델을 사용했으며 T-FREE가 기존 태거 기반 방법보다 훨씬 더 적응력이 있다는 것을 발견했습니다.
그러나 연구자들은 현재 결과에 대해 겸손한 태도를 유지하고 있습니다. 그들은 지금까지 실험이 최대 30억 개의 매개변수를 가진 모델로 제한되었으며 앞으로 더 큰 모델과 더 큰 데이터 세트에 대한 추가 평가가 계획되어 있음을 인정합니다.
T-FREE 방법의 출현은 대규모 언어 모델의 효율성을 향상시키기 위한 새로운 아이디어를 제공하며, 계산 비용을 줄이고 모델 성능을 향상시키는 이점이 주목할 만합니다. 향후 연구 방향은 T-FREE의 적용 범위를 더욱 확대하고 대규모 언어 모델 기술의 지속적인 개발을 촉진하기 위해 대규모 모델 및 데이터 세트의 검증에 중점을 둘 것입니다. T-FREE는 가까운 미래에 더 많은 분야에서 중요한 역할을 할 것으로 믿어집니다.