Jina AI는 HTML을 깔끔한 마크다운으로 변환하도록 특별히 설계된 경량 언어 모델인 Reader-LM을 출시했습니다. 웹페이지에서 광고, 스크립트 등 복잡한 콘텐츠를 효율적으로 제거하여 복잡한 정규식이나 수동 작업 없이 명확하게 구조화된 마크다운 파일을 생성할 수 있습니다. Reader-LM은 Reader-LM-0.5B와 Reader-LM-1.5B의 두 가지 버전으로 제공됩니다. 두 버전 모두 리소스가 제한된 환경에서도 효율적으로 실행되도록 최적화되어 있으며 최대 256K 토큰까지 컨텍스트를 지원합니다.
Jina AI는 원본 HTML 콘텐츠를 깨끗하고 깔끔한 마크다운 형식으로 변환하도록 특별히 설계된 두 가지 작은 언어 모델을 출시하여 지루한 웹 페이지 데이터 처리를 없앨 수 있습니다.
Reader-LM이라는 이 모델의 가장 큰 특징은 웹 콘텐츠를 마크다운 파일로 빠르고 효율적으로 변환할 수 있다는 것입니다.
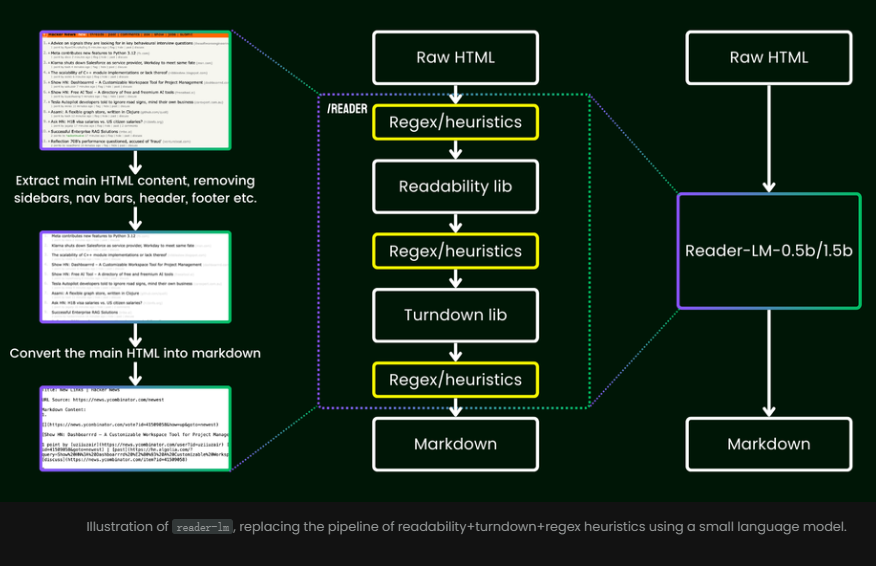
이를 사용하면 더 이상 복잡한 규칙이나 힘든 정규식에 의존할 필요가 없다는 장점이 있습니다. 이러한 모델은 광고, 스크립트, 탐색 표시줄 등 웹페이지에서 복잡한 콘텐츠를 지능적으로 자동으로 제거하고 최종적으로 명확하고 체계적인 마크다운 형식을 제공합니다.
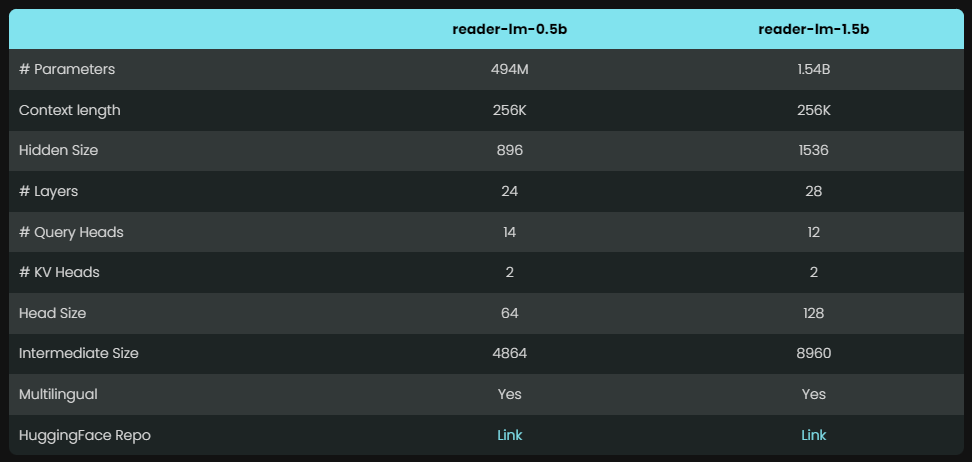
Reader-LM은 서로 다른 매개변수를 갖는 두 가지 모델, 즉 Reader-LM-0.5B와 Reader-LM-1.5B를 제공합니다. 이 두 모델의 매개변수 수는 크지 않지만 HTML을 Markdown으로 변환하는 작업에 최적화되어 있으며 그 결과는 놀랍고 많은 대형 언어 모델을 능가합니다.
컴팩트한 디자인 덕분에 이 모델은 리소스가 제한된 환경에서도 효율적으로 작동할 수 있습니다. 더욱 칭찬할 만한 점은 Reader-LM이 다국어를 지원할 뿐만 아니라 최대 256K 토큰까지 컨텍스트 데이터를 처리할 수 있어 복잡한 HTML 파일도 쉽게 처리할 수 있다는 점입니다.
정규식이나 수동 설정에 의존하는 기존 방법과 달리 Reader-LM은 HTML 데이터를 자동으로 정리하고 주요 정보를 추출하는 엔드투엔드 솔루션을 제공합니다.
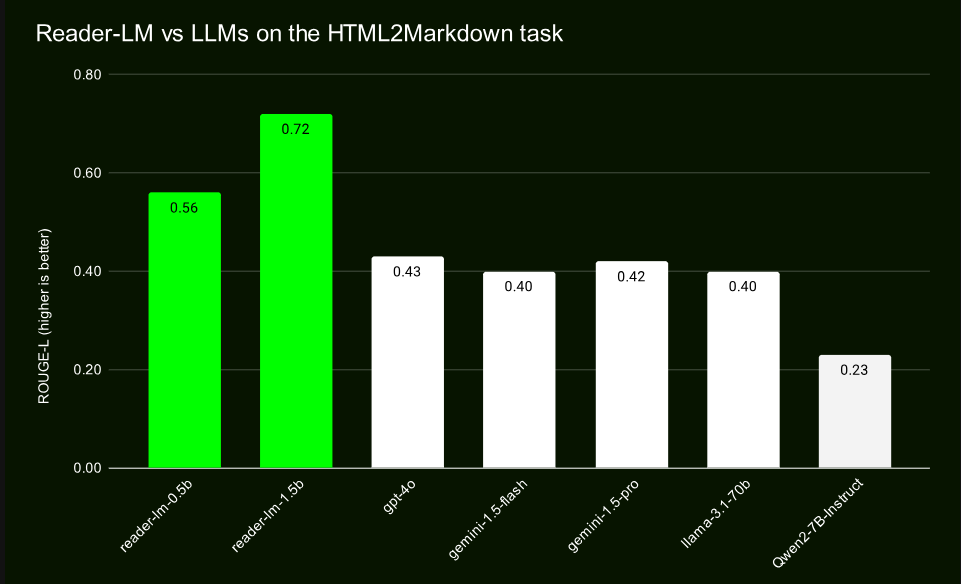
GPT-4, Gemini 등 대규모 모델과의 비교 테스트를 통해 Reader-LM은 특히 구조 보존 및 Markdown 구문 사용 측면에서 탁월한 성능을 입증했습니다. Reader-LM-1.5B는 다양한 지표에서 특히 좋은 성능을 보여 ROUGE-L 점수가 0.72로 콘텐츠 생성 정확도가 높고 오류율도 유사 제품에 비해 현저히 낮습니다.
Reader-LM은 컴팩트한 디자인으로 인해 하드웨어 리소스 사용량이 가벼우며, 특히 0.5B 모델은 Google Colab과 같은 저사양 환경에서도 원활하게 실행될 수 있습니다. 작은 크기에도 불구하고 Reader-LM은 여전히 강력한 긴 컨텍스트 처리 기능을 갖추고 있으며 성능에 영향을 주지 않고 크고 복잡한 웹 콘텐츠를 효율적으로 처리할 수 있습니다.
교육 측면에서 Reader-LM은 다단계 프로세스를 채택하고 원본 및 시끄러운 HTML에서 Markdown 콘텐츠를 추출하는 데 중점을 둡니다.
훈련 과정에는 다수의 실제 웹페이지와 합성 데이터의 결합이 포함되어 모델의 효율성과 정확성을 보장합니다. 신중하게 설계된 2단계 교육을 통해 Reader-LM은 복잡한 HTML 파일을 처리하는 능력을 점차적으로 향상시키고 반복 생성 문제를 효과적으로 피했습니다.
공식 소개: https://jina.ai/news/reader-lm-small-언어-models-for-cleaning-and-converting-html-to-markdown/
전체적으로 Reader-LM은 HTML에서 Markdown으로의 변환을 위한 효율적이고 편리하며 정확한 솔루션을 제공합니다. 가벼운 디자인으로 인해 다양한 환경에서 쉽게 실행할 수 있으므로 웹 페이지 데이터 처리에 이상적인 선택입니다. 자세한 내용은 공식 소개 링크를 참조하세요.