Kunlun Technology는 최근 자사가 개발한 두 가지 보상 모델인 Skywork-Reward-Gemma-2-27B와 Skywork-Reward-Llama-3.1-8B가 RewardBench에서 탁월한 결과를 달성했으며 27B 모델이 목록 1위를 차지했다고 발표했습니다. 이는 Kunlun Wanwei가 인공 지능 분야, 특히 보상 모델의 연구 및 개발에서 획기적인 발전을 이루었으며 대규모 언어 모델 훈련을 위한 새로운 기술 지원을 제공한다는 것을 의미합니다. 보상 모델은 모델 학습을 안내하고 인간 선호도에 더 부합하는 콘텐츠를 생성할 수 있으므로 강화 학습에서 매우 중요합니다. Kunlun Wanwei의 모델은 데이터 선택 및 모델 훈련에 고유한 장점이 있어 대화 및 보안과 같은 측면에서 좋은 성능을 발휘하며 특히 어려운 샘플을 처리할 때 강력한 기능을 보여줍니다.
Kunlun Wanwei Technology Co., Ltd.는 최근 자사가 개발한 두 가지 새로운 보상 모델인 Skywork-Reward-Gemma-2-27B와 Skywork-Reward-Llama-3.1-8B가 국제적으로 권위 있는 보상 모델인 RewardBench에서 좋은 성과를 거두었다고 발표했습니다. 평가 벤치마크 중 Skywork-Reward-Gemma-2-27B 모델이 1위를 차지하며 RewardBench 관계자로부터 높은 평가를 받았습니다.
보상 모델은 강화 학습에서 핵심적인 위치를 차지하며 다양한 상태에서 에이전트의 성능을 평가하고 에이전트의 학습 과정을 안내하는 보상 신호를 제공하여 특정 환경에서 최적의 선택을 할 수 있도록 합니다. 대규모 언어 모델 학습에서 보상 모델은 특히 중요한 역할을 하며 모델이 인간 선호도에 맞는 콘텐츠를 보다 정확하게 이해하고 생성하도록 돕습니다.
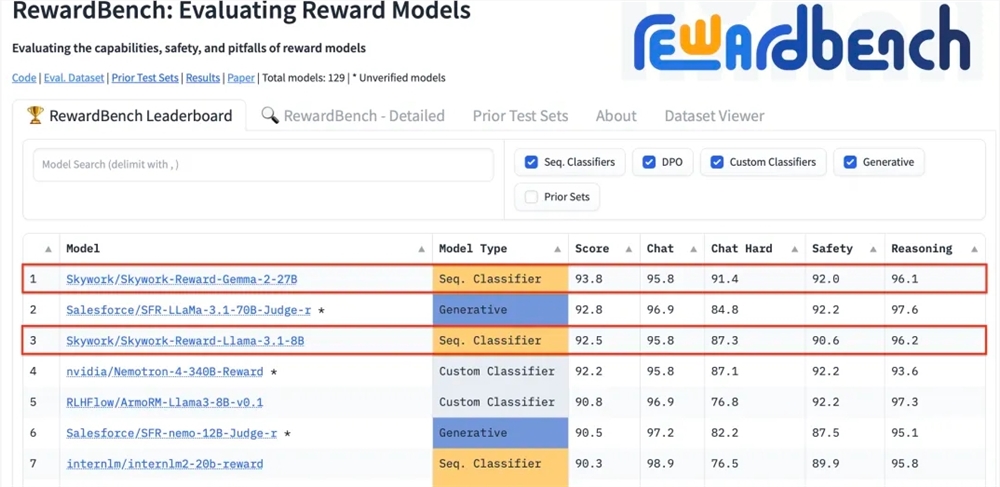
RewardBench는 대화, 추론, 보안 등 여러 작업을 통해 모델을 종합적으로 평가하는 벤치마크 목록입니다. 이 목록의 테스트 데이터 세트는 프롬프트 단어, 선택된 응답 및 거부된 응답으로 구성된 트리플로 구성됩니다. 이는 응답을 거부하기 전에 프롬프트 단어가 주어지면 거부된 응답 중에서 선택된 응답의 순위를 올바르게 지정할 수 있는지 테스트하는 데 사용됩니다. .
Kunlun Wanwei의 Skywork-Reward 모델은 신중하게 선택된 부분 정렬 데이터 세트와 상대적으로 작은 기본 모델을 통해 개발되었습니다. 기존 보상 모델과 비교하여 부분 정렬 데이터는 인터넷의 공개 데이터에서만 나오며 특정 필터를 통해 필터링됩니다. -품질 선호도 데이터 세트. 데이터는 보안, 수학, 코드 등 광범위한 주제를 다루며, 데이터의 객관성과 보상 격차의 중요성을 보장하기 위해 수동으로 검증됩니다.
테스트 결과 Kunlun Wanwei의 보상 모델은 대화 및 보안과 같은 분야에서 탁월한 성능을 보였습니다. 특히 어려운 샘플에 직면했을 때 Skywork-Reward-Gemma-2-27B 모델만이 올바른 예측을 제공했습니다. 이번 성과는 글로벌 AI 분야에서 Kunlun Wanwei의 기술적 강점과 혁신 역량을 나타내며 AI 기술의 개발 및 적용에 대한 새로운 가능성을 제공합니다.
27B 모델 주소:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
8B 모델 주소:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
RewardBench에서 Kunlun Wanwei의 뛰어난 성과는 인공 지능 분야에서 선도적인 기술과 혁신 역량을 보여주며, 향후 대규모 언어 모델 개발을 위한 새로운 방향과 가능성을 제시합니다.