Mamba 팀의 연구는 획기적인 성과를 거두었습니다. 그들은 대형 Transformer 모델 Llama를 보다 효율적인 Mamba 모델로 "증류"하는 데 성공했습니다. 본 연구는 점진적 증류, 감독된 미세 조정 및 방향 선호 최적화와 같은 기술을 교묘하게 결합하고 Mamba 모델의 고유한 구조를 기반으로 새로운 추론 디코딩 알고리즘을 설계하여 성능을 보장하지 않고도 모델의 추론 속도를 크게 향상시킵니다. 손실 없이 효율성이 달성되었습니다. 본 연구는 대규모 모델 훈련 비용을 절감할 뿐만 아니라, 향후 모델 최적화를 위한 새로운 아이디어를 제공하는데, 이는 학문적 의의와 활용 가치가 매우 중요합니다.
최근 Mamba 팀의 연구가 눈길을 끌고 있습니다. Cornell 및 Princeton과 같은 대학의 연구진은 대형 Transformer 모델인 Llama를 Mamba로 성공적으로 "증류"하고 모델 추론 속도를 크게 향상시킨 새로운 추론 디코딩 알고리즘을 설계했습니다.
연구원들의 목표는 라마를 맘바로 바꾸는 것입니다. 이렇게 하는 이유는 대규모 모델을 처음부터 훈련하는 데 비용이 많이 들고 Mamba가 처음부터 폭넓은 관심을 받았지만 실제로 대규모 Mamba 모델을 직접 훈련하는 팀은 거의 없기 때문입니다. AI21의 Jamba 및 NVIDIA의 Hybrid Mamba2와 같이 시장에 평판이 좋은 일부 변형 제품이 있지만, 많은 성공적인 Transformer 모델에는 풍부한 지식이 내장되어 있습니다. 이 지식을 확보하고 Transformer를 Mamba로 미세 조정할 수 있다면 문제는 해결될 것입니다.
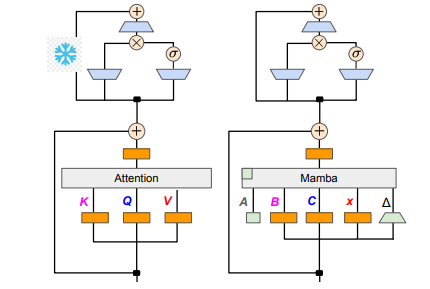
연구팀은 점진적 증류, 감독된 미세 조정, 방향 선호 최적화 등 다양한 방법을 결합하여 이 목표를 성공적으로 달성했습니다. 성능을 저하시키지 않으면서 속도도 중요하다는 점은 주목할 가치가 있습니다. Mamba는 긴 시퀀스 추론에서 확실한 이점을 갖고 있으며 Transformer에는 추측 디코딩과 같은 추론 가속 솔루션도 있습니다. Mamba의 고유한 구조는 이러한 솔루션을 직접적으로 적용할 수 없기 때문에 연구진은 특별히 새로운 알고리즘을 설계하고 이를 하드웨어 기능과 결합하여 Mamba 기반 추론적 디코딩을 구현했습니다.
마지막으로 연구원들은 Zephyr-7B와 Llama-38B를 선형 RNN 모델로 성공적으로 변환했으며 이들의 성능은 증류 전의 표준 모델과 비슷했습니다. 전체 훈련 과정에서는 20B 토큰만 사용하며 결과는 1.2T 토큰을 사용하여 처음부터 훈련한 Mamba7B 모델과 3.5T 토큰으로 훈련한 NVIDIA Hybrid Mamba2 모델과 비슷합니다.
기술적인 세부 사항에서는 선형 RNN과 선형 어텐션이 연결되어 있어 연구자들은 어텐션 메커니즘에서 투영 행렬을 직접 재사용하고 매개변수 초기화를 통해 모델 구축을 완료할 수 있습니다. 또한 연구팀은 Transformer에서 MLP 계층의 매개변수를 동결하고 Attention 헤드를 선형 RNN 계층(예: Mamba)으로 점차 교체했으며 헤드 전체에서 공유 키와 값에 대한 그룹 쿼리 Attention을 처리했습니다.
증류 과정에서 어텐션 레이어를 점진적으로 교체하는 전략이 채택됩니다. 감독된 미세 조정에는 두 가지 주요 방법이 포함됩니다. 하나는 단어 수준 KL 발산을 기반으로 하고 다른 하나는 시퀀스 수준 지식 증류를 기반으로 합니다. 사용자 선호도 조정 단계에서 팀은 DPO(Direct Preference Optimization) 방법을 사용하여 모델이 콘텐츠 생성 시 교사 모델의 출력과 비교하여 사용자 기대를 더 잘 충족할 수 있는지 확인했습니다.
다음으로, 연구원들은 Transformer의 추측적 디코딩을 Mamba 모델에 적용하기 시작했습니다. 추측적 디코딩은 작은 모델을 사용하여 여러 출력을 생성한 다음 큰 모델을 사용하여 이러한 출력을 검증하는 것으로 간단히 이해될 수 있습니다. 소형 모델은 빠르게 실행되고 여러 출력 벡터를 빠르게 생성할 수 있는 반면, 대형 모델은 이러한 출력의 정확성을 평가하여 전반적인 추론 속도를 높입니다.
이 프로세스를 구현하기 위해 연구진은 소형 모델을 사용하여 매번 K개의 초안 출력을 생성한 다음 대형 모델이 검증을 통해 최종 출력과 중간 상태의 캐시를 반환하는 일련의 알고리즘을 설계했습니다. 이 방법은 GPU에서 좋은 결과를 얻었습니다. Mamba2.8B는 추론 가속을 1.5배 달성했으며 승인률은 60%에 도달했습니다. 다양한 아키텍처의 GPU에 따라 효과가 다르지만 연구팀은 커널을 통합하고 구현 방법을 조정하여 더욱 최적화했으며 마침내 이상적인 가속 효과를 달성했습니다.
실험 단계에서 연구진은 Zephyr-7B와 Llama-3Instruct8B를 사용해 3단계 증류 훈련을 진행했고, 결국 8카드 80G A100에서 실행하는 데 3~4일밖에 걸리지 않아 연구 결과를 성공적으로 재현했다. 이번 연구는 Mamba와 Llama의 변화를 보여줄 뿐만 아니라 미래 모델의 추론 속도와 성능을 향상시키기 위한 새로운 아이디어를 제공합니다.
논문 주소: https://arxiv.org/pdf/2408.15237
본 연구는 대규모 언어 모델의 효율성을 향상시키기 위한 귀중한 경험과 기술 솔루션을 제공하며, 향후 더 많은 분야에 적용되어 인공지능 기술의 발전을 촉진할 것으로 기대됩니다. 논문 주소 제공을 통해 독자는 연구 내용을 더 깊이 이해할 수 있습니다.