학계에서는 허위 논문의 확산이 심각한 문제가 되어 과학 연구의 발전과 지식의 보급을 심각하게 저해하고 있습니다. 이러한 문제를 해결하기 위해 뉴욕주 Binghamton University의 연구원 Ahmed Abdin Hameed는 xFakeSci라는 기계 학습 알고리즘을 개발했습니다. 이 알고리즘은 가짜 학술 논문을 효과적으로 식별하고 학문적 무결성을 유지하는 것이 새로운 기술적 수단을 제공할 수 있습니다. 이 기사에서는 xFakeSci 알고리즘의 원리, 적용 및 향후 개발 방향을 깊이 탐구하여 학술 사기 퇴치에 있어 엄청난 잠재력을 보여줍니다.
오늘날 정보 폭발 시대, 특히 과학 연구 분야에서는 가짜 논문의 출현을 막기가 어렵습니다.
최근 뉴욕주 빙엄턴 대학의 연구원인 Ahmed Abdeen Hamed는 최대 94%의 정확도로 위조된 학술 논문을 식별할 수 있는 xFakeSci라는 기계 학습 알고리즘을 개발했습니다.
Hameed는 자신의 주요 연구 방향이 생물의학 정보학이며 전염병 기간 동안 가짜 과학 연구 기사가 끝없이 나타났다고 말했습니다.
그와 그의 팀은 알츠하이머병, 암, 우울증 등 세 가지 인기 의학 주제에 대해 수많은 실험을 진행하고 가짜 기사 50개를 제작했으며, 동일한 주제에 대한 실제 기사와 비교 분석을 수행했습니다. 이런 식으로 그는 차이점과 패턴을 발견하기를 희망합니다.
연구 과정에서 Hameed는 국립 보건원의 PubMed 데이터베이스를 사용하여 관련 문헌을 추출하고 동일한 키워드를 사용하여 ChatGPT에 논문 생성을 요청했습니다. 그의 직관은 그에게 가짜 서류와 진짜 서류 사이에 어떤 패턴이 있다는 것을 알았습니다.
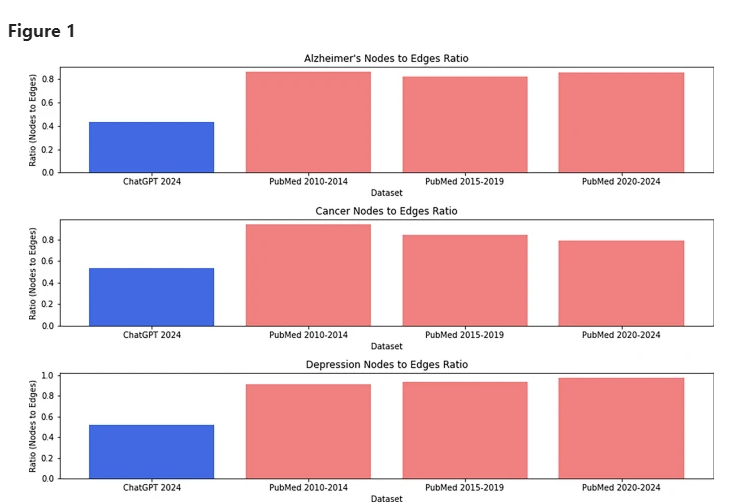
다양한 데이터 세트 ChatGPT 및 과학 기사에 대한 노드 대 가장자리 비율.
심층 분석 후 xFakeSci 알고리즘은 주로 두 가지 주요 기능에 중점을 둡니다. 첫째, "기후 변화", "임상 시험" 등과 같은 기사의 바이그램과 두 번째로 이러한 바이그램과 다른 단어 및 개념.
그는 가짜 논문에 나타난 이중 단어 조합의 수가 실제 논문에 비해 현저히 적다는 사실을 발견했습니다. 이러한 조합은 가짜 논문의 다른 내용과 밀접한 관련이 있음에도 불구하고 말입니다.
그는 AI로 생성된 논문은 독자를 설득하기 위해 설계되는 경우가 많은 반면, 인간 연구자의 목표는 실험 결과와 방법을 진실되게 보고하는 것이라고 지적했습니다.
앞으로 하메드는 xFakeSci 알고리즘을 공학, 과학, 인문학 등 더 많은 분야로 확장해 위조종이의 특성이 일치하는지 검증할 계획이다. 그는 AI 기술이 지속적으로 발전할수록 논문의 진위 여부를 판별하는 것이 점점 더 어려워질 것이라고 강조했다. 따라서 포괄적인 솔루션을 설계하는 것이 특히 중요합니다.
현재 알고리즘은 가짜 종이의 94%를 탐지할 수 있지만, 가짜 종이의 6%는 여전히 네트워크를 통과할 수 있습니다. 그는 중요한 진전이 있었지만 인식률을 높이고 대중의 인식을 높이기 위해서는 여전히 지속적인 노력이 필요하다고 겸손하게 말했습니다.
종이 입구: https://www.nature.com/articles/s41598-024-66784-6
가장 밝은 부분:
** 새로운 도구 xFakeSci는 최대 94%의 정확도로 가짜 과학 연구 논문을 식별하여 과학 연구를 보호할 수 있습니다. **
? ** 연구자들은 가짜 논문을 대량으로 제작해 실제 논문과 비교한 결과 둘 사이의 글쓰기 스타일에 상당한 차이가 있음을 발견했습니다. **
** 앞으로 AI 생성 논문의 점점 복잡해지는 과제를 해결하기 위해 알고리즘의 적용 범위가 확장될 예정입니다. **
xFakeSci 알고리즘의 출현은 학술 사기에 맞서기 위한 강력한 무기를 제공하지만, 여전히 지속적으로 개선되고 개선되어야 합니다. 기술의 발전과 학문의 진실성 유지를 위해서는 보다 건강한 학문 생태계를 만들기 위한 공동의 노력이 필요합니다.