Google DeepMind는 여러 대학과 협력하여 추론 작업에서 생성 AI의 정확성과 신뢰성이 부족한 문제를 해결하는 것을 목표로 하는 생성 보상 모델(GenRM)이라는 새로운 방법을 개발했습니다. 기존 생성 AI 모델은 자연어 처리 등의 분야에서 널리 사용되고 있지만, 특히 매우 높은 정확도가 요구되는 분야에서는 자신있게 잘못된 정보를 출력하는 경우가 많아 적용 범위가 제한됩니다. GenRM의 혁신은 검증 프로세스를 다음 단어 예측 작업으로 재정의하고, LLM(Large Language Model)의 텍스트 생성 기능을 검증 프로세스에 통합하고, 연쇄 추론을 지원함으로써 보다 포괄적이고 체계적인 검증을 달성하는 것입니다.
최근 Google DeepMind 연구팀은 여러 대학과 협력하여 추론 작업에서 생성 AI의 정확성과 신뢰성을 향상시키는 것을 목표로 하는 GenRM(Generative Reward Model)이라는 새로운 방법을 제안했습니다.
생성 AI는 자연어 처리 등 다양한 분야에서 널리 사용됩니다. 일련의 단어 중 다음 단어를 예측하여 일관된 텍스트를 생성합니다. 그러나 이러한 모델은 때때로 자신 있게 잘못된 정보를 출력하는데, 이는 특히 교육, 금융, 의료 등 정확성이 중요한 분야에서 큰 문제가 됩니다.
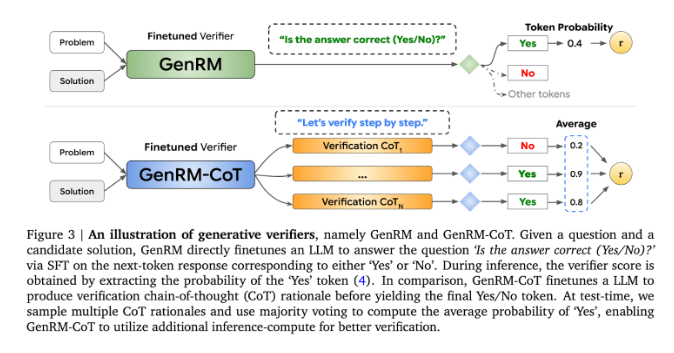
현재 연구자들은 출력 정확도 측면에서 생성 AI 모델이 겪는 어려움에 대해 다양한 솔루션을 시도했습니다. 그 중 차별적 보상 모델(RM)은 점수를 기반으로 잠재적 답변이 올바른지 여부를 결정하는 데 사용되지만 이 방법은 대규모 언어 모델(LLM)의 생성 기능을 완전히 활용하지 못합니다. 흔히 사용되는 또 다른 방법은 "심판으로서의 LLM"이지만, 이 방법은 복잡한 추론 과제를 해결할 때 전문 검증자만큼 효과적이지 않은 경우가 많습니다.
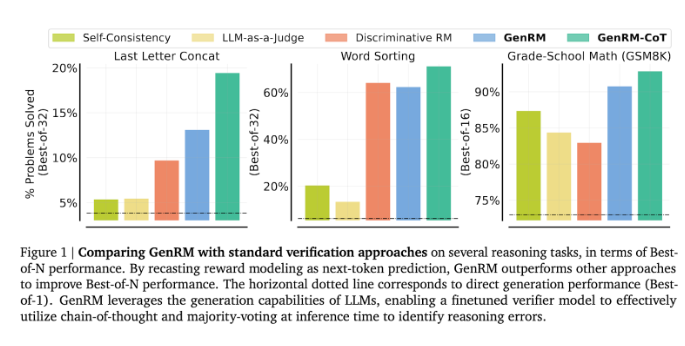
GenRM의 혁신은 검증 프로세스를 다음 단어 예측 작업으로 재정의하는 것입니다. 이는 기존의 차별적 보상 모델과 달리 GenRM이 LLM의 텍스트 생성 기능을 검증 프로세스에 통합하여 모델이 잠재적인 솔루션을 동시에 생성하고 평가할 수 있음을 의미합니다. 또한 GenRM은 연쇄 추론(CoT)도 지원합니다. 즉, 모델은 최종 결론에 도달하기 전에 중간 추론 단계를 생성할 수 있으므로 검증 프로세스가 더욱 포괄적이고 체계화됩니다.
생성과 검증을 결합함으로써 GenRM 접근 방식은 모델이 훈련 중에 생성 및 검증 기능을 동시에 향상시킬 수 있는 통합 훈련 전략을 채택합니다. 실제 애플리케이션에서 모델은 최종 답을 확인하는 데 사용되는 중간 추론 단계를 생성합니다.
연구원들은 GenRM 모델이 유치원 수학 및 알고리즘 문제 해결 작업의 정확도가 크게 향상되는 등 여러 가지 엄격한 테스트에서 우수한 성능을 발휘한다는 사실을 발견했습니다. 차별적 보상 모델과 LLM을 판단 방식으로 비교했을 때 GenRM의 문제 해결 성공률은 16%에서 64%로 증가했습니다.
예를 들어 Gemini1.0Pro 모델의 출력을 검증할 때 GenRM은 문제 해결 성공률을 73%에서 92.8%로 높였습니다.
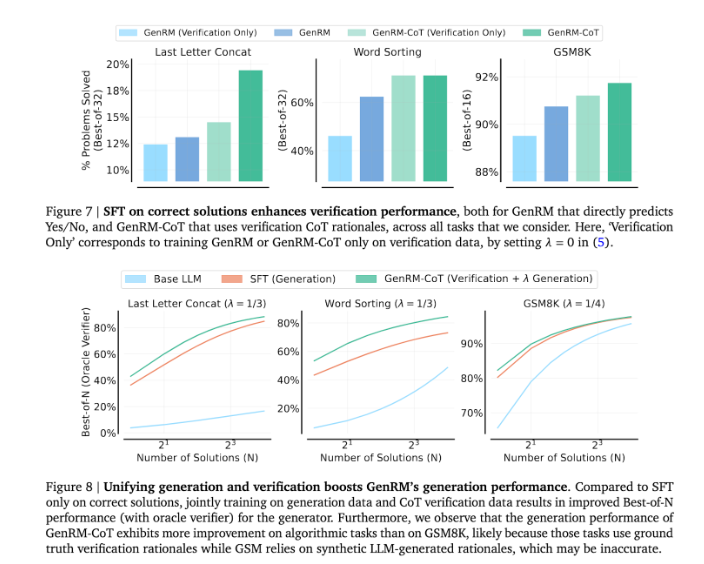
GenRM 방법의 도입은 생성 AI 분야에서 큰 발전을 의미하며, 솔루션 생성 및 검증을 하나의 프로세스로 통합하여 AI 생성 솔루션의 정확성과 신뢰성을 크게 향상시킵니다.
전체적으로, GenRM의 출현은 생성적 AI의 신뢰성을 향상시키기 위한 새로운 아이디어를 제공합니다. 복잡한 추론 문제를 해결하는 데 있어서 GenRM의 상당한 개선은 생성적 AI가 더 많은 분야에 적용될 가능성을 나타내며, 이는 추가 연구와 탐색의 가치가 있습니다.