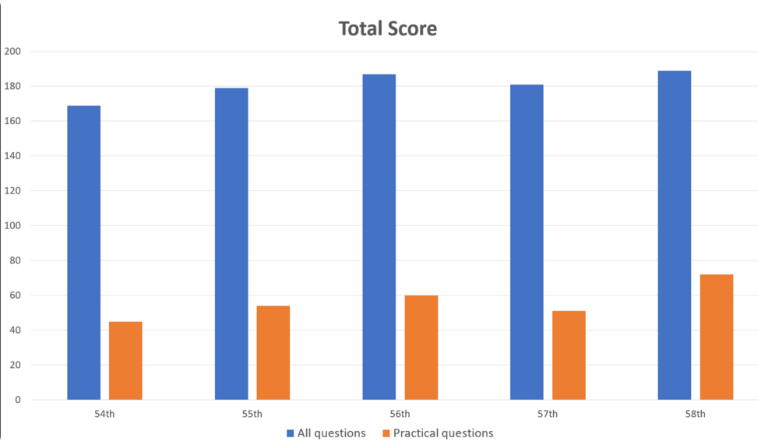
최근 Cureus 매거진에 발표된 연구에 따르면 OpenAI의 GPT-4 모델은 추가 교육 없이 일본 물리치료 시험을 성공적으로 통과한 것으로 나타났습니다. 연구진은 기억력, 독해력, 적용력, 분석력, 평가력 등 총 1,000문항을 대상으로 GPT-4를 테스트한 결과, 정확도 73.4%로 5개 테스트 항목을 모두 통과한 것으로 나타났다. 이 연구는 의료 응용 분야에서 GPT-4의 잠재력에 대한 우려를 불러일으키는 동시에 실제 문제 및 그림 표가 포함된 문제와 같은 특정 유형의 문제를 처리하는 데 한계가 있음을 보여줍니다.
Cureus 저널에 발표된 최근 동료 검토 연구에 따르면 OpenAI의 GPT-4 언어 모델은 추가 교육 없이 일본 물리 치료 시험을 성공적으로 통과했습니다.
연구원들은 기억, 이해, 적용, 분석 및 평가와 같은 영역을 다루는 1,000개의 질문을 GPT-4에 입력했습니다. 결과에 따르면 GPT-4는 전체 질문의 73.4%를 정확하게 답변하여 5개 테스트 부분을 모두 통과한 것으로 나타났습니다. 그러나 연구 결과에 따르면 일부 영역에서는 AI의 한계도 드러났습니다.

GPT-4는 일반적인 문제에서는 80.1%의 정확도로 좋은 성능을 보였지만 실제 문제에서는 46.6%에 그쳤습니다. 마찬가지로, 그림과 표가 포함된 질문(35.4% 정답)보다 텍스트로만 구성된 질문(80.5% 정답)을 훨씬 더 잘 처리합니다. 이 발견은 GPT-4 시각적 이해의 한계에 대한 이전 연구와 일치합니다.
질문 난이도와 텍스트 길이가 GPT-4의 성능에 거의 영향을 미치지 않는다는 점은 주목할 가치가 있습니다. 모델은 주로 영어 데이터를 사용하여 학습되었지만 일본어 입력을 처리할 때도 좋은 성능을 보였습니다.
연구자들은 이 연구가 임상 재활 및 의학 교육에서 GPT-4의 잠재력을 입증하지만 주의 깊게 살펴봐야 한다고 지적했습니다. 그들은 GPT-4가 모든 질문에 올바르게 답하지 않으며 새 버전에 대한 향후 평가와 필기 및 추론 테스트에서 모델의 기능이 필요할 것이라고 강조했습니다.
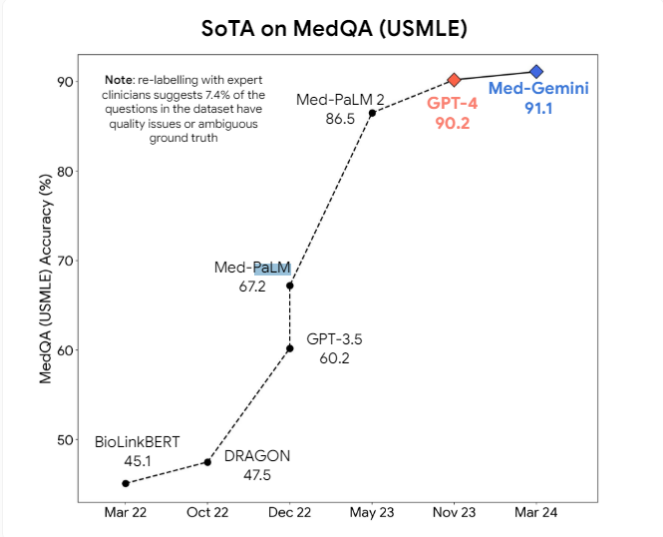
또한 연구원들은 GPT-4v와 같은 다중 모드 모델이 시각적 이해를 더욱 향상시킬 수 있다고 제안했습니다. 현재 Google의 Med-PaLM2, Med-Gemini 등 전문 의료 AI 모델과 Llama3를 기반으로 한 Meta의 의료 모델이 의료 업무에서 범용 모델을 뛰어넘는 것을 목표로 활발히 개발되고 있습니다.
그러나 전문가들은 의료용 AI 모델이 실제로 널리 사용되기까지는 오랜 시간이 걸릴 수 있다고 생각합니다. 현재 모델의 오차 공간은 의료 환경에서 여전히 너무 크며, 이러한 모델을 일상적인 의료 행위에 안전하게 통합하려면 추론 기능의 상당한 발전이 필요합니다.
이 연구는 의료 분야에서 GPT-4의 잠재력을 보여주지만 AI 기술이 복잡한 의료 시나리오에 실제로 적용되기 위해서는 여전히 지속적으로 개선되어야 한다는 점을 상기시켜 줍니다. 앞으로는 다중 모드 모델과 더욱 강력한 추론 기능이 의료 분야에서 AI의 안전성과 신뢰성을 보장하는 핵심 개선 사항이 될 것입니다.