ModelScope 커뮤니티는 대규모 DiT 모델을 기반으로 한 텍스트-비디오 생성 모델인 국내 오픈 소스 Sora 비디오 생성 모델 CogVideoX - CogVideoX-5B의 업그레이드 버전을 오픈 소스화했습니다. 이전 CogVideoX-2B에 비해 새 모델은 비디오 품질과 시각 효과가 크게 향상되었습니다. CogVideoX-5B는 3D Causal Variational Autoencoder(3D Causal VAE)와 전문 Transformer 기술을 활용하며, 시공간 관절 모델링을 위한 위치 인코딩 및 3D Full Attention 메커니즘으로 3D-RoPE를 사용하여 더 긴 시간 동안 생성할 수 있습니다. , 더 높은 품질, 더 많은 모션 기능을 갖춘 비디오.
이전 CogVideoX-2B와 비교하여 새 모델은 비디오 생성의 품질과 시각 효과를 크게 향상시켰습니다.
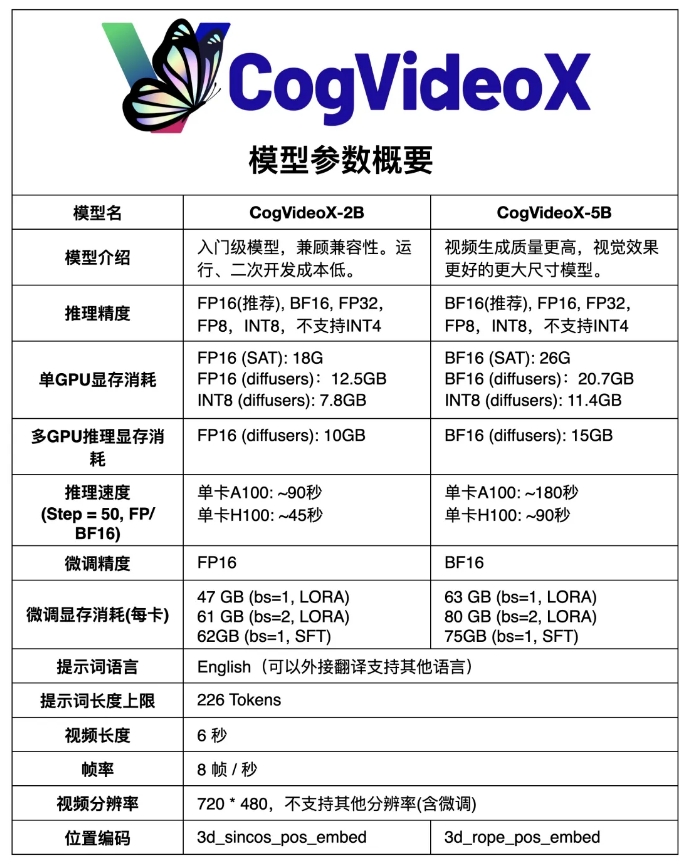
CogVideoX-5B는 텍스트-비디오 생성 작업을 위해 특별히 설계된 대규모 DiT(확산 변환기) 모델을 기반으로 합니다. 이 모델은 3D Causal Variation Autoencoder(3D Causal VAE)와 전문 Transformer 기술을 채택하고 텍스트와 비디오 임베딩을 결합하며 3D-RoPE를 위치 인코딩으로 사용하고 시공간 관절 모델링을 위해 3D Full Attention 메커니즘을 활용합니다.
또한 이 모델은 진보적인 훈련 기술을 채택하고 중요한 모션 기능을 갖춘 일관되고 장기적인 고품질 비디오를 생성할 수 있습니다.
모델 링크:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
CogVideoX-5B의 오픈 소스는 국내 AI 비디오 생성 분야에 새로운 기술 혁신과 개발 기회를 가져왔으며 연구원과 개발자에게 강력한 도구와 리소스를 제공했습니다. CogVideoX-5B를 기반으로 한 보다 혁신적인 애플리케이션이 앞으로 등장하여 AI 비디오 생성 기술의 지속적인 발전을 촉진할 것으로 예상됩니다. 모델에 대한 쉬운 접근은 연구와 적용의 문턱을 낮추어 기술의 더 넓은 보급과 적용을 촉진합니다.