Transformer 아키텍처의 등장은 자연어 처리 분야에 혁명을 일으켰지만 높은 계산 비용으로 인해 긴 텍스트를 처리할 때 병목 현상이 발생했습니다. 이 문제에 대응하여 이 기사에서는 트리 축소를 통해 긴 컨텍스트 Transformer 모델의 self-attention 계산 복잡성을 효과적으로 줄이고 최신 GPU 클러스터의 성능을 최대한 활용하는 Tree Attention이라는 새로운 방법을 소개합니다. 컴퓨팅 효율성이 크게 향상됩니다.
정보가 폭발하는 시대에 인공지능은 마치 밝은 별처럼 인간 지혜의 밤하늘을 밝혀준다. 그 중에서도 Transformer 아키텍처는 의심의 여지 없이 가장 눈부신 아키텍처입니다. Self-Attention 메커니즘을 핵심으로 하여 자연어 처리의 새로운 시대를 선도합니다. 그러나 가장 밝은 별에도 도달하기 어려운 구석이 있습니다. 긴 컨텍스트 Transformer 모델의 경우 self-attention 계산의 높은 리소스 소비가 문제가 됩니다. 수만 단어 길이의 기사를 AI가 이해하도록 하려고 한다고 상상해 보십시오. 각 단어는 기사의 다른 모든 단어와 비교되어야 합니다.
이 문제를 해결하기 위해 Zyphra와 EleutherAI의 과학자 그룹은 Tree Attention이라는 새로운 방법을 제안했습니다.
Transformer 모델의 핵심인 Self-attention은 시퀀스 길이가 증가함에 따라 계산 복잡성이 2차적으로 증가합니다. 이는 특히 LLM(대형 언어 모델)의 경우 긴 텍스트를 처리할 때 극복할 수 없는 장애물이 됩니다.
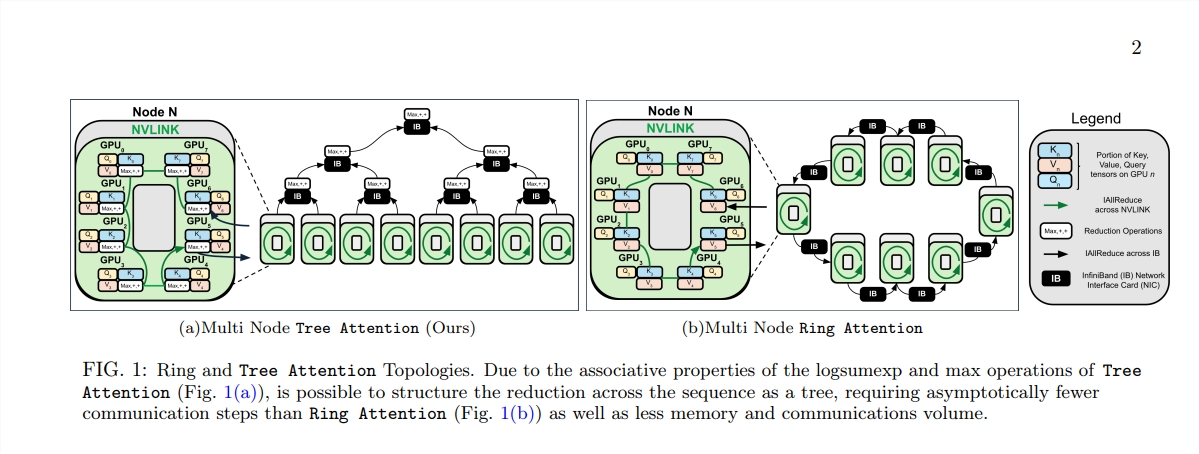
Tree Attention의 탄생은 이러한 계산의 숲에 효율적인 계산을 수행할 수 있는 나무를 심는 것과 같습니다. 트리 축소를 통해 self-attention 계산을 여러 병렬 작업으로 분해합니다. 각 작업은 나무의 잎과 같아서 함께 완전한 나무를 형성합니다.
더욱 놀라운 점은 Tree Attention 제안자들이 self-attention의 에너지 함수도 도출했다는 점입니다. 이는 self-attention에 대한 베이지안 설명을 제공할 뿐만 아니라 이를 Hopfield 네트워크 스탠드업과 같은 에너지 모델과 밀접하게 연결합니다.
또한 Tree Attention은 최신 GPU 클러스터의 네트워크 토폴로지를 특별히 고려하고 클러스터 내의 고대역폭 연결을 지능적으로 활용하여 노드 간 통신 요구 사항을 줄여 컴퓨팅 효율성을 향상시킵니다.
일련의 실험을 통해 과학자들은 다양한 시퀀스 길이와 GPU 수에서 Tree Attention의 성능을 검증했습니다. 결과는 여러 GPU에서 디코딩할 때 Tree Attention이 기존 Ring Attention 방법보다 최대 8배 더 빠르며 통신량과 최대 메모리 사용량을 크게 줄이는 것으로 나타났습니다.
Tree Attention의 제안은 긴 맥락 Attention 모델 계산을 위한 효율적인 솔루션을 제공할 뿐만 아니라 Transformer 모델의 내부 메커니즘을 이해하는 데 새로운 관점을 제공합니다. AI 기술이 계속 발전함에 따라 Tree Attention이 미래 AI 연구 및 응용 분야에서 중요한 역할을 할 것이라고 믿을 만한 이유가 있습니다.
논문 주소: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
Tree Attention의 출현은 긴 텍스트 처리의 계산 병목 현상을 해결하기 위한 효율적이고 혁신적인 솔루션을 제공합니다. 이는 Transformer 모델의 이해와 향후 개발에 광범위한 의미를 갖습니다. 이 방법은 성능을 크게 향상시킬 뿐만 아니라, 더 중요하게는 후속 연구에 대한 새로운 아이디어와 방향을 제공하므로 심층적인 연구와 토론의 가치가 있습니다.