LLM(대형 언어 모델)의 발전은 인상적이지만 몇 가지 간단한 문제에서 예상치 못한 단점을 나타냅니다. Andrej Karpathy는 이러한 "지그재그 지능" 현상을 날카롭게 지적했습니다. 즉, LLM은 복잡한 작업을 수행할 수 있지만 간단한 문제에서는 실수를 자주 저지르는 것입니다. 이로 인해 LLM의 본질적인 결함과 향후 개선 방향에 대한 심층적인 생각이 촉발되었습니다. 이 기사에서는 이에 대해 자세히 설명하고 LLM을 더 잘 활용하고 한계를 피하는 방법을 모색할 것입니다.
최근에는 "9.11이 9.9보다 더 큰가?"라는 단순해 보이는 질문이 전 세계적으로 널리 관심을 끌었습니다. 거의 모든 LLM(대형 언어 모델)이 이 문제에 대해 실수를 범했습니다. 이러한 현상은 AI 분야 전문가인 안드레이 카르파티(Andrej Karpathy)의 주목을 끌었다. 이번 호를 시작으로 현재 대형 모델 기술의 본질적인 결함과 향후 개선 방향에 대해 심도있게 논의했다.
Karpathy는 이 현상을 "변형 지능" 또는 "변형 지능"이라고 부르며, 최첨단 LLM이 어려운 수학적 문제 해결과 같은 다양하고 복잡한 작업을 수행할 수 있지만 겉보기에 단순해 보이는 일부 작업에서는 실패한다는 점을 지적합니다. 문제를 제대로 수행하지 못하며 이러한 지능의 불균형은 톱니 모양과 유사합니다.
예를 들어 OpenAI 연구원인 Noam Brown은 Tic-Tac-Toe 게임에서 LLM의 성능이 좋지 않아 사용자가 승리하려고 할 때에도 모델이 올바른 결정을 내릴 수 없다는 사실을 발견했습니다. Karpathy는 이것이 모델이 "정당하지 않은" 결정을 내리기 때문이라고 믿고 있는 반면, Noam은 이것이 훈련 데이터에서 전략에 대한 관련 논의가 부족하기 때문일 수 있다고 믿습니다.
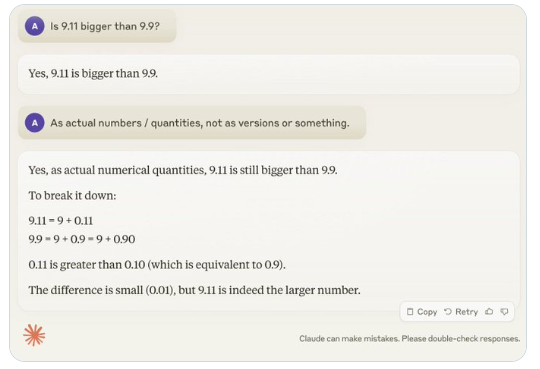
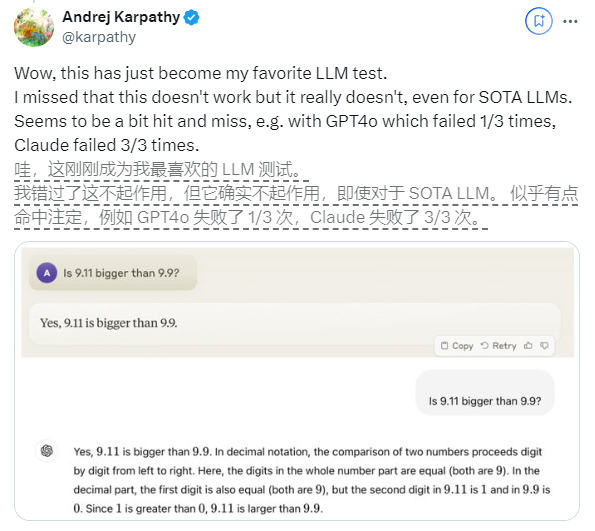
또 다른 예는 LLM이 영숫자 수량을 계산할 때 발생하는 오류입니다. Llama 3.1의 최신 릴리스조차도 간단한 질문에 잘못된 답변을 제공합니다. Karpathy는 이것이 LLM의 "자기 지식" 부족, 즉 모델이 자신이 할 수 있는 것과 할 수 없는 것을 구별할 수 없기 때문에 모델이 작업에 직면할 때 "자신감 있는 자신감"을 갖게 되는 데서 비롯된다고 설명했습니다.
이 문제를 해결하기 위해 Karpathy는 Meta가 발표한 Llama3.1 논문에서 제안한 솔루션을 언급했습니다. 이 논문에서는 모델이 자기 인식을 개발하고 알고 있는 내용을 알 수 있도록 훈련 후 단계에서 모델 정렬을 달성할 것을 권장합니다. 단순히 사실 지식을 추가하는 것만으로는 환상 문제를 근절할 수 없습니다. Llama 팀은 모델이 이해하는 질문에만 답하고 불확실한 답은 생성하지 않도록 하는 '지식 탐지'라는 훈련 방법을 제안했습니다.
Karpathy는 AI의 현재 기능에 다양한 문제가 있지만 이는 근본적인 결함을 구성하지 않으며 실행 가능한 해결책이 있다고 믿습니다. 그는 현재의 AI 훈련 아이디어는 단지 "인간 라벨을 모방하고 규모를 확장하는 것"이라고 제안했습니다. AI의 지능을 지속적으로 향상하려면 전체 개발 스택에 걸쳐 더 많은 작업이 수행되어야 합니다.
문제가 완전히 해결될 때까지 LLM을 프로덕션에 사용하려면 자신이 잘하는 작업으로 제한하고 "톱니 모양의 가장자리"를 인식하고 항상 사람의 참여를 유지해야 합니다. 이러한 방식으로 우리는 AI의 한계로 인한 위험을 피하면서 AI의 잠재력을 더 잘 활용할 수 있습니다.
전체적으로 LLM의 "변덕스러운 지능"은 현재 AI 분야가 직면한 과제이지만 극복할 수 없는 것은 아닙니다. 훈련 방법을 개선하고, 모델의 자기 인식을 강화하고, 이를 실제 시나리오에 신중하게 적용함으로써 LLM의 장점을 더 잘 활용하고 인공 지능 기술의 지속적인 개발을 촉진할 수 있습니다.