급성장하고 있는 AI 분야에서는 데이터 수집 방법이 점점 더 주목받고 있습니다. 이 글은 AI 기업 Anthropic 산하 클로드 팀의 대규모 데이터 스크래핑 행위로 인해 발생한 논란을 살펴본다. 클로드 팀의 크롤러 프로그램인 클로드봇(ClaudeBot)은 다수의 웹사이트에서 허가 없이 대량의 데이터를 크롤링해 웹사이트 규정을 위반했을 뿐만 아니라 엄청난 양의 서버 리소스를 소모해 광범위한 비난과 우려를 불러일으켰다. 이 사건은 AI 개발과 데이터 저작권 보호 사이의 모순을 부각시켜 업계가 데이터 수집의 윤리 및 법적 규범을 다시 생각하게 만들었습니다.
사건의 원인은 클로드 팀의 크롤러가 24시간 동안 한 회사의 서버를 100만 번 방문하여 웹사이트 콘텐츠를 무료로 크롤링했기 때문입니다. 이러한 행위는 해당 웹사이트의 크롤링 금지 공지를 노골적으로 무시했을 뿐만 아니라, 대량의 서버 리소스를 강제로 점유했습니다.
자신을 방어하기 위한 최선의 노력에도 불구하고 피해자 회사는 결국 Claude 팀의 데이터 스크랩을 막는 데 실패했습니다. 회사 리더들은 화가 나서 소셜 미디어를 통해 Claude 팀의 행동을 비난했습니다. 많은 네티즌들도 불만을 토로했고, 일부 네티즌들은 이러한 행동을 '도둑질'이라는 단어로 표현하자고 제안하기도 했습니다.
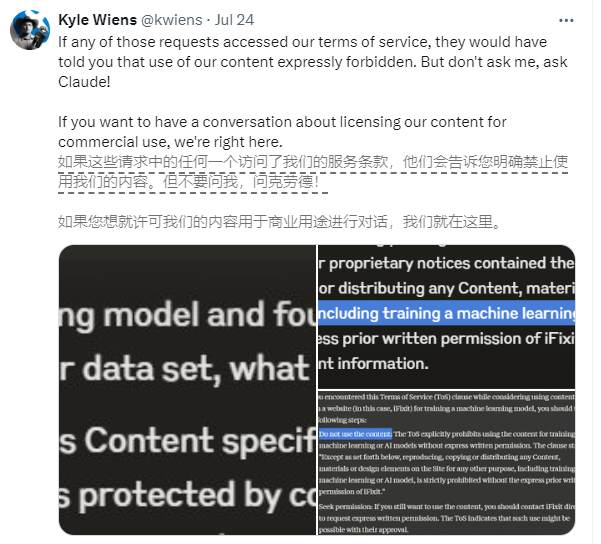
관련된 회사는 미국 전자상거래 및 사용법 웹사이트인 iFixit입니다. iFixit은 가전제품과 기기를 다루는 수백만 페이지의 무료 온라인 수리 안내서를 제공합니다. 그러나 iFixit은 Claude의 크롤러 프로그램인 ClaudeBot이 짧은 시간 내에 많은 수의 요청을 시작하여 하루에 10TB의 파일에 액세스하고 5월 한 달 동안 총 73TB에 액세스했다는 사실을 발견했습니다.
iFixit CEO Kyle Wiens는 ClaudeBot이 허가 없이 모든 데이터를 훔쳤으며 서버 리소스를 점유했다고 말했습니다. iFixit은 웹사이트에 무단 데이터 스크랩이 금지되어 있음을 명시적으로 명시하고 있지만 Claude 팀은 이를 무시하고 있는 것 같습니다.
Claude 팀의 행동은 독특하지 않습니다. 올해 4월에는 Linux Mint 포럼도 ClaudeBot의 빈번한 방문으로 인해 포럼이 느리게 실행되거나 심지어 충돌하는 문제를 겪었습니다. 또 클로드와 오픈AI의 GPT 외에도 해당 웹사이트의 robots.txt 설정을 무시하고 데이터를 강제로 빼앗는 AI 기업이 많다는 지적도 나온다.
이러한 상황에 직면하여 웹사이트 소유자는 데이터가 불법적으로 스크랩되었는지 여부를 감지하기 위해 추적 가능하거나 고유한 정보가 포함된 가짜 콘텐츠를 페이지에 추가하는 것이 좋습니다. iFixit은 실제로 이 조치를 취하여 Claude뿐만 아니라 OpenAI에서도 데이터를 스크랩했다는 사실을 발견했습니다.
이 사건은 AI 회사의 데이터 스크랩 관행에 대한 광범위한 논의를 촉발시켰습니다. 한편으로는 AI 개발을 지원하기 위해 많은 양의 데이터가 필요한 반면, 데이터 캡처는 웹사이트 소유자의 권리와 규정도 존중해야 합니다. 기술 발전 촉진과 저작권 보호 사이에서 균형을 찾는 방법은 업계 전체가 고민해야 할 문제입니다.
클로드 팀의 데이터 탈취 사건은 AI 기업들에게 기술 진보를 추구하는 동시에 지적 재산권을 존중하고, 법률과 규정을 준수하며, 데이터를 얻기 위한 규정을 준수하는 방법을 적극적으로 모색해야 한다는 점을 상기시키며 경종을 울렸습니다. 그래야만 AI 기술의 건전한 발전을 보장하고 부적절한 행동으로 인해 업계 평판과 대중의 신뢰가 훼손되는 것을 피할 수 있습니다.