Llama 3.1 대규모 언어 모델을 훈련한 Meta의 경험은 AI 개발에 있어 전례 없는 도전과 기회를 보여주었습니다. 16,384개의 GPU로 구성된 거대한 클러스터는 54일의 훈련 기간 동안 평균 3시간마다 오류를 경험했습니다. 이는 AI 모델 규모의 급속한 성장을 부각시켰을 뿐만 아니라 슈퍼컴퓨팅의 안정성에 큰 병목 현상을 노출시켰습니다. 체계. 이 기사에서는 Llama 3.1 교육 과정에서 Meta가 직면한 과제와 이러한 과제를 해결하기 위해 채택한 전략을 살펴보고 그것이 전체 AI 산업에 미치는 영향을 분석합니다.
인공 지능의 세계에서는 모든 혁신에는 놀라운 데이터가 수반됩니다. 16,384개의 GPU가 동시에 실행되고 있다고 상상해 보십시오. 이것은 공상 과학 영화의 한 장면이 아니라 최신 Llama3.1 모델을 훈련할 때 Meta의 실제 묘사입니다. 하지만 이런 기술의 향연 뒤에는 평균 3시간마다 발생하는 장애가 숨어 있다. 이 놀라운 숫자는 AI 개발 속도를 보여줄 뿐만 아니라 현재 기술이 직면한 엄청난 과제를 드러냅니다.
Llama1에 사용된 2,028개의 GPU부터 Llama3.1에 사용된 16,384개의 GPU까지, 이러한 비약적인 성장은 수량의 변화일 뿐만 아니라 기존 슈퍼컴퓨팅 시스템의 안정성에 대한 극단적인 도전이기도 합니다. Meta의 연구 데이터에 따르면 Llama3.1의 54일 훈련 주기 동안 총 419건의 예상치 못한 구성 요소 오류가 발생했으며 그 중 약 절반은 H100 GPU 및 HBM3 메모리와 관련이 있었습니다. 이 데이터를 통해 우리는 AI 성능의 혁신을 추구하는 동시에 시스템의 신뢰성도 향상되었는지 생각해 보게 됩니다.
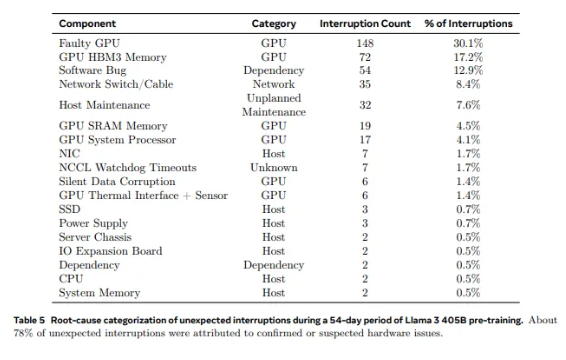
실제로 슈퍼컴퓨팅 분야에는 논란의 여지가 없는 사실이 있습니다. 규모가 클수록 오류를 피하기가 더 어렵다는 것입니다. Meta의 Llama 3.1 훈련 클러스터는 수만 개의 프로세서, 수십만 개의 기타 칩, 수백 마일의 케이블로 구성되어 있으며 이는 작은 도시의 신경망과 비교할 수 있는 수준의 복잡성입니다. 이런 거대 기업에서는 오작동이 흔히 발생하는 것 같습니다.
잦은 실패에도 불구하고 메타팀은 무력하지 않았습니다. 그들은 작업 시작 및 검문소 시간 단축, 독점 진단 도구 개발, PyTorch의 NCCL 비행 기록 장치 활용 등 일련의 대처 전략을 채택했습니다. 이러한 조치는 시스템의 내결함성을 향상시킬 뿐만 아니라 자동화된 처리 기능도 향상시킵니다. Meta의 엔지니어들은 현대의 소방관과 같아서 훈련 과정을 방해할 수 있는 모든 화재를 진압할 준비가 되어 있습니다.
그러나 문제는 하드웨어 자체에서만 발생하는 것이 아닙니다. 환경적 요인과 전력 소비 변동으로 인해 슈퍼컴퓨팅 클러스터에 예상치 못한 문제도 발생합니다. Meta 팀은 낮과 밤의 온도 변화와 GPU 전력 소비의 급격한 변동이 훈련 성능에 상당한 영향을 미칠 것이라는 사실을 발견했습니다. 이번 발견은 기술적 혁신을 추구하는 동시에 환경 및 에너지 소비 관리의 중요성을 무시할 수 없음을 상기시켜 줍니다.
Llama3.1의 훈련 과정은 슈퍼컴퓨팅 시스템의 안정성과 신뢰성에 대한 궁극적인 테스트라고 할 수 있습니다. Meta 팀이 과제를 해결하기 위해 채택한 전략과 개발된 자동화 도구는 전체 AI 산업에 귀중한 경험과 영감을 제공합니다. 어려움에도 불구하고, 기술의 지속적인 발전으로 미래의 슈퍼컴퓨팅 시스템은 더욱 강력하고 안정적이 될 것이라고 믿을 수 있는 이유가 있습니다.
AI 기술이 급속도로 발전하는 시대에 메타의 시도는 의심할 바 없이 용감한 모험이다. 이는 AI 모델의 성능 경계를 확장할 뿐만 아니라 한계를 추구하는 데 있어 우리가 직면하는 실제 과제를 보여줍니다. AI 기술이 가져올 무한한 가능성을 기대하며, 동시에 기술의 최전선에서 쉬지 않고 일하는 엔지니어들을 칭찬합시다. 그들의 모든 시도, 모든 실패, 모든 돌파구는 인간의 기술적 진보를 위한 길을 열어줍니다.
참고자료:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- 메타스-16384-gpu-훈련-클러스터에 대해 3시간마다 한 번의 실패
Llama 3.1의 훈련 사례는 우리에게 귀중한 교훈을 제공하고 슈퍼컴퓨팅 시스템의 향후 개발 방향을 지적했습니다. 성능을 추구하는 동시에 시스템 안정성과 신뢰성을 중요하게 생각하고 다양한 실패에 대처할 전략을 적극적으로 모색해야 합니다. 그래야만 AI 기술의 지속적이고 안정적인 발전을 보장하고 인류에게 이익을 줄 수 있습니다.