메타 과학자 Thomas Scialom은 Latent Space 팟캐스트에서 Llama 3.1의 개발 과정을 자세히 설명하고 Llama 4의 개발 방향을 미리 소개했습니다. Llama 3.1은 단순한 매개변수 스태킹이 아니라 매개변수 크기, 훈련 시간 및 하드웨어 제한 간의 절충안입니다. 405B 매개변수 크기는 GPT-4o에 대한 대응입니다. 거대한 모델 크기로 인해 일반 컴퓨터에서는 실행하기가 어렵지만, 오픈 소스 기능을 통해 더 많은 사람들이 참여하고 기술 개발을 촉진할 수 있습니다.
Llama3.1의 탄생은 매개변수 규모, 훈련 시간 및 하드웨어 제한 간의 완벽한 균형을 이루었습니다. 405B의 거대한 몸체는 무작위 선택이 아니라 Meta가 GPT-4o에게 제기한 도전입니다. 하드웨어 제한으로 인해 Llama3.1이 모든 가정용 컴퓨터에서 실행될 수는 없지만 오픈 소스 커뮤니티의 힘으로 모든 것이 가능해졌습니다.
Llama 3.1을 개발하는 동안 Scialom과 그의 팀은 확장 법칙을 재검토했습니다. 그들은 모델 크기가 실제로 핵심이지만 더 중요한 것은 훈련 데이터의 총량이라는 것을 발견했습니다. Llama3.1은 더 많은 컴퓨팅 성능을 소비하더라도 훈련 토큰 수를 늘리는 것을 선택했습니다.
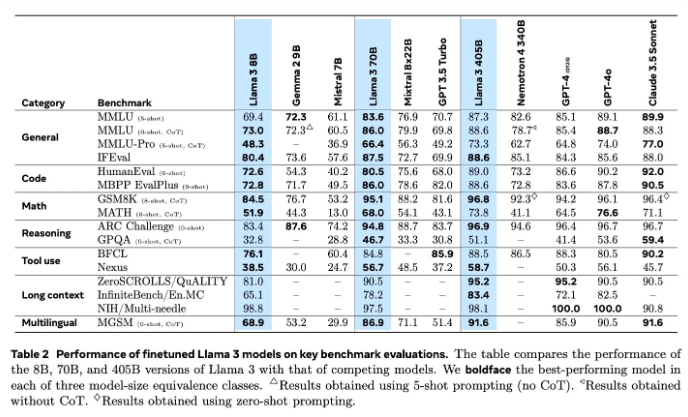
Llama 3.1의 아키텍처에는 획기적인 변화가 없지만, 메타는 데이터의 규모와 품질 측면에서 많은 노력을 기울였습니다. 15T 토큰 바다는 Llama3.1에 지식의 깊이와 폭에 있어 질적인 도약을 제공했습니다.
데이터 선택 측면에서 Scialom은 공용 인터넷에 텍스트 쓰레기가 너무 많고 실제 금은 합성 데이터라고 굳게 믿습니다. Llama3.1의 학습 후 과정에서는 수동으로 작성된 답변이 전혀 사용되지 않았으며 Llama2에서 생성된 합성 데이터에 전적으로 의존했습니다.
모델 평가는 AI 분야에서 늘 어려운 문제였습니다. Llama3.1은 보상 모델, 다양한 벤치마크 테스트 등 다양한 평가 및 개선 방법을 시도했습니다. 그러나 진정한 도전은 강력한 모델을 물리칠 수 있는 올바른 프롬프트를 찾는 것입니다.
Meta는 지난 6월부터 Llama4의 훈련을 시작했으며, 이번에는 Agent 기술에 중점을 두었습니다. Toolformer와 같은 에이전트 도구의 개발은 AI 분야에서 Meta의 새로운 탐구를 예고합니다.
Llama3.1의 오픈소스는 메타의 과감한 시도일 뿐만 아니라, AI의 미래에 대한 심오한 고민이기도 합니다. Llama4의 출시로 우리는 Meta가 계속해서 AI 분야를 선도할 것이라고 믿을 이유가 있습니다. Llama4와 에이전트 기술이 AI의 미래를 어떻게 재정의할지 기대해 보겠습니다.
Llama 3.1의 R&D 프로세스에 대한 심층적인 이해를 통해 대규모 언어 모델 분야에서 Meta의 지속적인 혁신과 노력, 그리고 오픈 소스 커뮤니티에 대한 강조를 확인할 수 있습니다. Llama 4의 연구 개발 방향은 AI 기술의 향후 발전 추세를 나타내므로 기다려 볼 가치가 있습니다. 앞으로 AI 기술이 어떻게 발전할지 기대해 보자.