NVIDIA는 최근 4B 및 8B 버전을 포함한 소형 언어 모델의 Minitron 시리즈를 출시했습니다. 이러한 움직임은 대규모 언어 모델의 교육 및 배포 비용을 줄이고 더 많은 개발자가 이 고급 기술을 쉽게 사용할 수 있도록 하는 것을 목표로 합니다. Minitron 모델은 "가지치기" 및 "지식 증류" 기술을 통해 대형 모델에 필적하는 성능을 유지하면서 모델 크기를 크게 줄였으며 일부 지표에서는 다른 잘 알려진 모델을 능가합니다. 이는 인공지능 기술의 대중화를 촉진하는데 큰 의미가 있다.
최근 NVIDIA는 인공 지능 분야에서 새로운 움직임을 보였습니다. 그들은 4B 및 8B 버전을 포함한 소형 언어 모델의 Minitron 시리즈를 출시했습니다. 이러한 모델은 훈련 속도를 40배 향상시킬 뿐만 아니라 개발자가 번역, 감정 분석, 대화형 AI 등 다양한 애플리케이션에 이를 더 쉽게 사용할 수 있도록 해줍니다.
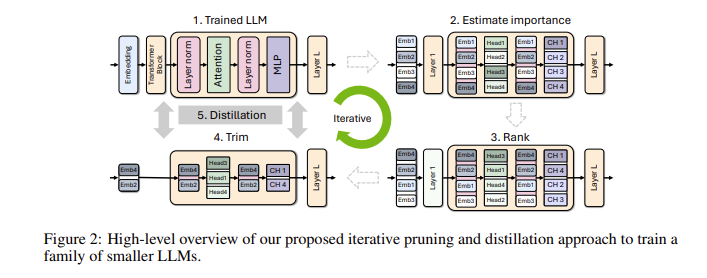
소규모 언어 모델이 왜 그렇게 중요한지 궁금하실 수도 있습니다. 실제로 기존의 대규모 언어 모델은 강력한 성능을 제공하지만 교육 및 배포 비용이 매우 높으며 많은 양의 컴퓨팅 리소스와 데이터가 필요한 경우가 많습니다. 이러한 고급 기술을 더 많은 사람들이 저렴하게 사용할 수 있도록 NVIDIA 연구팀은 "가지치기"와 "지식 증류"라는 두 가지 기술을 결합하여 모델의 크기를 효율적으로 줄이는 획기적인 방법을 생각해냈습니다.
구체적으로, 연구자들은 먼저 기존의 대규모 모델에서 시작하여 이를 정리할 것입니다. 모델의 각 뉴런, 레이어 또는 주의 헤드의 중요성을 평가하고 덜 중요한 항목을 제거합니다. 이렇게 하면 모델이 훨씬 작아지고 학습에 필요한 리소스와 시간도 크게 줄어듭니다. 다음으로, 소규모 데이터 세트를 사용하여 정리된 모델에 대한 지식 증류 훈련을 수행하여 모델의 정확성을 복원합니다. 놀랍게도 이 과정은 비용을 절약할 뿐만 아니라 모델의 성능도 향상시킵니다!
실제 테스트에서 NVIDIA 연구팀은 Nemotron-4 모델 제품군에서 좋은 결과를 얻었습니다. 유사한 성능을 유지하면서 모델 크기를 2~4배 줄이는 데 성공했습니다. 더욱 흥미로운 점은 8B 모델이 여러 지표에서 Mistral7B 및 LLaMa-38B와 같은 다른 잘 알려진 모델을 능가하고 훈련 과정에서 필요한 훈련 데이터가 40배 적어서 컴퓨팅 비용이 1.8배 절약된다는 점입니다. 이것이 무엇을 의미하는지 상상해 보십시오. 더 많은 개발자가 더 적은 리소스와 비용으로 강력한 AI 기능을 경험할 수 있습니다!
NVIDIA는 모든 사람이 자유롭게 사용할 수 있도록 최적화된 Minitron 모델을 Huggingface의 오픈 소스로 만듭니다.
데모 입구: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
하이라이트:
** 훈련 속도 향상 **: Minitron 모델 훈련 속도는 기존 모델보다 40배 빨라 개발자의 시간과 노력을 절약할 수 있습니다.
**비용 절감**: 가지치기 및 지식 증류 기술을 통해 교육에 필요한 컴퓨팅 리소스와 데이터 양이 크게 줄어듭니다.
? **오픈소스 공유**: 미니트론 모델을 허깅페이스에 오픈소스화해 더 많은 사람들이 쉽게 접근하고 사용할 수 있도록 함으로써 AI 기술의 대중화를 촉진하고 있습니다.
Minitron 모델의 오픈 소스는 소규모 언어 모델의 실제 적용에 있어 중요한 돌파구를 제시합니다. 이는 또한 인공 지능 기술이 더욱 대중화되고 사용하기 쉬워져 더 많은 개발자와 응용 시나리오에 힘을 실어줄 것임을 나타냅니다. 앞으로는 더욱 유사한 혁신이 인공지능 기술의 지속적인 발전을 촉진할 것으로 기대할 수 있습니다.