Nvidia AI가 출시한 최신 ChatQA2 모델은 긴 텍스트 컨텍스트 이해 및 검색 강화 생성(RAG) 분야에서 획기적인 발전을 이루었습니다. 강력한 Llama3 모델을 기반으로 하며 컨텍스트 창을 128K 토큰으로 확장하고 3단계 명령 미세 조정을 채택하여 명령 추적 기능, RAG 성능 및 긴 텍스트 이해 기능을 크게 향상시킵니다. ChatQA2는 대용량 텍스트 데이터를 처리할 때 문맥적 일관성과 높은 재현율을 유지할 수 있으며, 여러 벤치마크 테스트에서 GPT-4-Turbo에 필적하는 성능을 입증했으며 일부 측면에서는 이를 능가하기도 했습니다. 이는 긴 텍스트를 처리하는 대규모 언어 모델의 능력이 크게 향상되었음을 나타냅니다.
성능 혁신: ChatQA2는 컨텍스트 창을 128K 토큰으로 확장하고 3단계 명령 조정 프로세스를 채택하여 명령 추적 기능, RAG 성능 및 긴 텍스트 이해를 크게 향상시킵니다. 이 기술적 혁신을 통해 모델은 최대 10억 개의 토큰으로 구성된 데이터 세트를 처리할 때 상황별 일관성과 높은 재현율을 유지할 수 있습니다.
기술적 세부사항: ChatQA2는 상세하고 재현 가능한 기술 솔루션을 사용하여 개발되었습니다. 이 모델은 먼저 지속적인 사전 학습을 통해 Llama3-70B의 컨텍스트 창을 8K에서 128K 토큰으로 확장합니다. 다음으로, 모델이 다양한 작업을 효과적으로 처리할 수 있도록 3단계 명령 튜닝 프로세스를 적용했습니다.
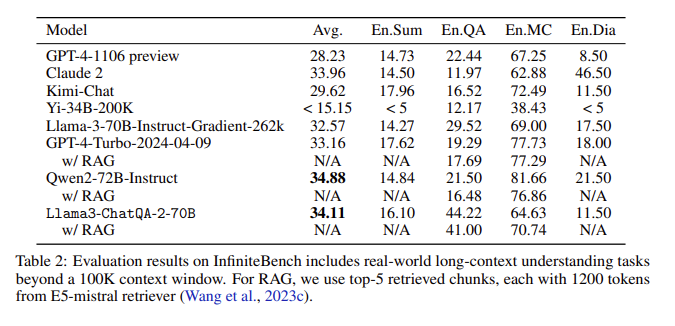
평가 결과: InfiniteBench 평가에서 ChatQA2는 긴 텍스트 요약, 질문 및 답변, 객관식, 대화 등의 작업에서 GPT-4-Turbo-2024-0409에 필적하는 정확도를 달성했으며 RAG 벤치마크에서도 이를 능가했습니다. 이 성과는 다양한 컨텍스트 길이와 기능에 걸쳐 ChatQA2의 포괄적인 기능을 강조합니다.
주요 문제 해결: ChatQA2는 검색 정확성과 효율성을 향상시키기 위해 최첨단 긴 텍스트 검색기를 사용하여 컨텍스트 조각화 및 낮은 재현율과 같은 RAG 프로세스의 주요 문제를 목표로 합니다.
컨텍스트 창을 확장하고 3단계 명령 튜닝 프로세스를 구현함으로써 ChatQA2는 GPT-4-Turbo에 필적하는 긴 텍스트 이해 및 RAG 성능을 달성합니다. 이 모델은 고급 긴 텍스트 및 검색 강화 생성 기술을 통해 정확성과 효율성의 균형을 유지하면서 다양한 다운스트림 작업을 위한 유연한 솔루션을 제공합니다.
논문 입구: https://arxiv.org/abs/2407.14482
ChatQA2의 출현은 긴 텍스트 처리 및 RAG 애플리케이션에 대한 새로운 가능성을 제공합니다. 효율성과 정확성은 향후 인공 지능 개발에 중요한 참조 가치를 제공합니다. 이 모델에 대한 공개 연구는 학계와 업계 간의 협력을 촉진하여 해당 분야의 지속적인 발전을 촉진합니다. 앞으로 이 모델을 기반으로 한 더욱 혁신적인 응용 프로그램을 볼 수 있기를 기대합니다.