4,050억 개의 매개변수를 가진 이 거대한 오픈소스 언어 모델인 라마 3.1은 정식 출시도 없이 유출돼 AI 분야에 큰 충격을 안겼다. 성능이 너무 강력해서 일부 벤치마크 테스트에서 GPT-4o를 능가하여 오픈 소스 모델에 대한 새로운 벤치마크를 설정했습니다. Reddit에 대한 열띤 토론은 그것이 AI 커뮤니티에 미치는 영향을 더욱 입증합니다. 이 기사에서는 Llama 3.1의 성능, 하이라이트 및 안전 조치를 자세히 살펴보고 이 신비한 모델을 공개합니다.
Llama3.1이 유출되었습니다! 4,050억 개의 매개변수가 포함된 이 오픈 소스 모델이 Reddit에서 소란을 일으켰습니다. 이는 아마도 현재까지 GPT-4o에 가장 가까운 오픈 소스 모델일 것이며 일부 측면에서는 이를 능가하기도 합니다.
Llama3.1은 Meta(이전의 Facebook)에서 개발한 대규모 언어 모델입니다. 아직 정식 버전은 나오지 않았지만, 유출된 버전은 이미 커뮤니티에 큰 반향을 불러일으켰습니다. 이 모델에는 기본 모델뿐만 아니라 벤치마크 결과인 8B, 70B와 최대 매개변수인 405B도 포함되어 있습니다.
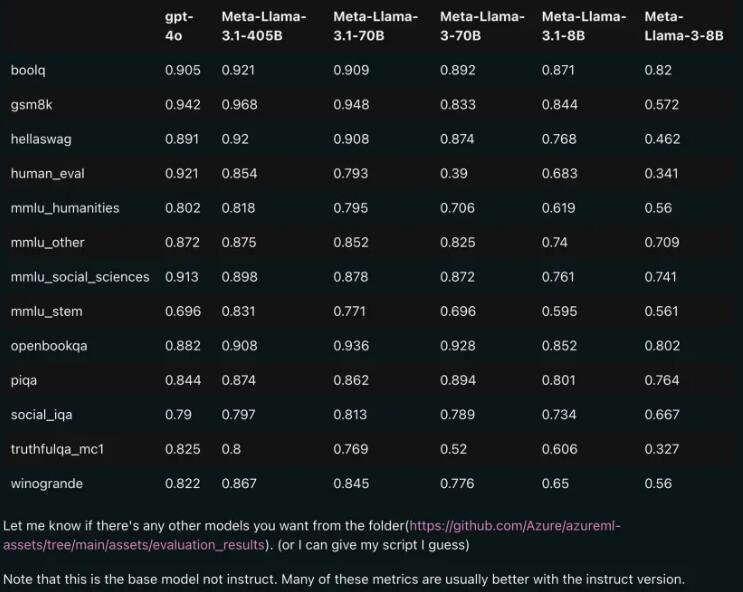
성능 비교: Llama3.1 대 GPT-4o
유출된 비교 결과에 따르면 Llama3.1의 70B 버전도 여러 벤치마크 테스트에서 GPT-4o를 능가했습니다. 오픈소스 모델이 여러 벤치마크에서 SOTA(최첨단 기술, State of the Art) 수준에 도달한 것은 이번이 처음입니다. 사람들은 한숨을 쉬지 않을 수 없습니다. 오픈소스의 힘은 정말 강력합니다!
모델 하이라이트: 다국어 지원, 풍부한 교육 데이터
Llama3.1 모델은 훈련을 위해 공개 소스의 15T+ 토큰을 사용하며 사전 훈련 데이터 마감일은 2023년 12월입니다. 영어뿐만 아니라 프랑스어, 독일어, 힌디어, 이탈리아어, 포르투갈어, 스페인어, 태국어도 지원합니다. 이는 다국어 대화 사용 사례에 적합합니다.

Llama3.1 연구팀은 모델의 보안을 매우 중요하게 생각합니다. 그들은 잠재적인 보안 위험을 완화하기 위해 인간이 생성한 데이터와 합성 데이터를 결합하는 다각적인 데이터 수집 접근 방식을 사용했습니다. 또한 모델에는 데이터 품질 관리를 향상시키기 위해 경계 프롬프트와 적대적 프롬프트도 도입되었습니다.
모델 카드 출처: https://pastebin.com/9jGkYbXY#google_vignette
Llama 3.1의 유출은 의심할 여지없이 AI 분야에 지대한 영향을 미칠 것입니다. 이는 오픈 소스 모델의 엄청난 잠재력을 보여줄 뿐만 아니라 모델 보안 및 윤리적 문제에 대한 더 많은 생각을 촉발합니다. 앞으로도 Llama 3.1과 후속 개발에 계속 관심을 갖고 AI 기술 발전에 더 많은 놀라움을 가져다 줄 것으로 기대합니다.