Ecossistema de camada intermediária de banco de dados distribuído Apache ShardingSphere v5.5.0
5.5.0
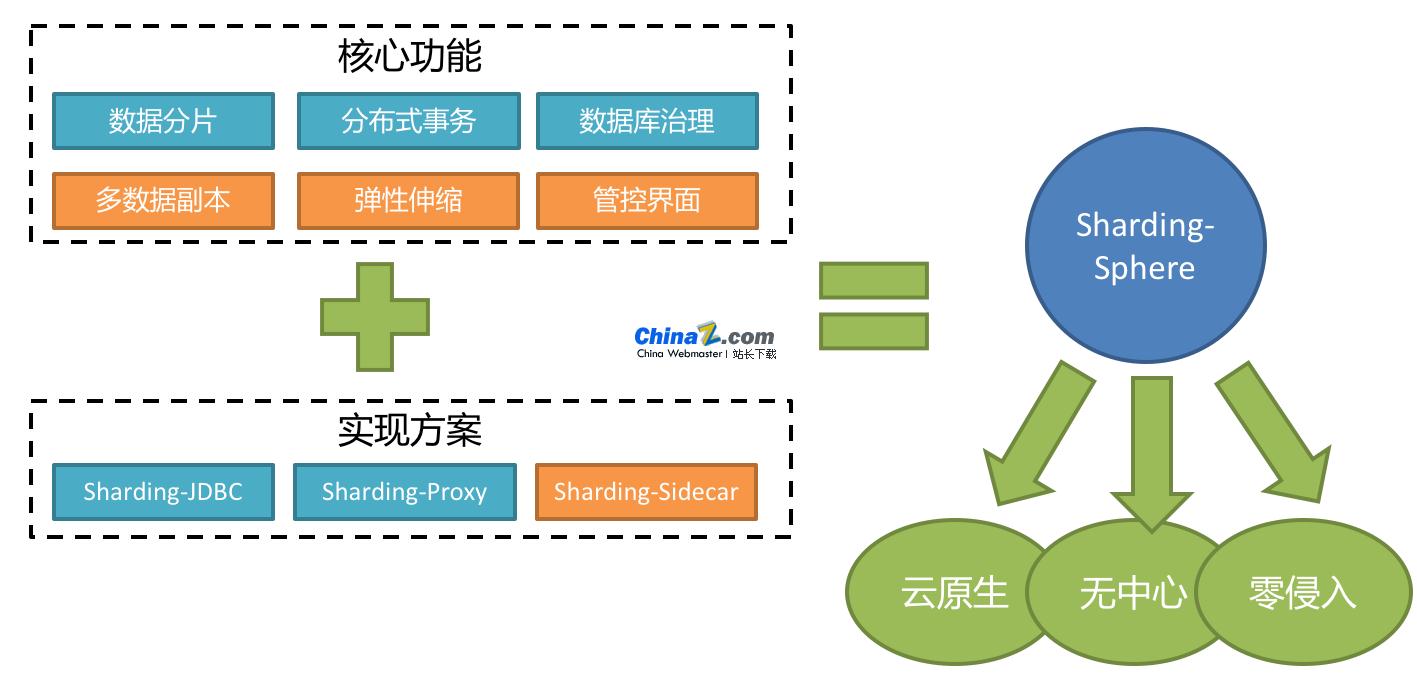
Apache ShardingSphere é um ecossistema composto por um conjunto de soluções de middleware de banco de dados distribuído de código aberto. Consiste em JDBC, Proxy e Sidecar (em planejamento), três produtos independentes entre si, mas que podem ser implantados e usados em conjunto. Todos eles fornecem fragmentação de dados padronizada, transações distribuídas e funções de gerenciamento de banco de dados, e podem ser aplicados a vários cenários de aplicação diversos, como isomorfismo Java, linguagens heterogêneas, nuvem nativa, etc.
Apache ShardingSphere está posicionado como middleware de banco de dados relacional, com o objetivo de utilizar plena e razoavelmente os recursos de computação e armazenamento de bancos de dados relacionais em cenários distribuídos, em vez de implementar um novo banco de dados relacional. Ele captura a essência das coisas, concentrando-se no imutável. Os bancos de dados relacionais ainda ocupam um mercado enorme hoje e são a base do negócio principal de cada empresa. Neste estágio, estamos mais focados em incrementos baseados na base original do que na subversão.
O Apache ShardingSphere 5.x começou a se concentrar na arquitetura conectável, e os componentes funcionais do projeto podem ser expandidos de maneira flexível e conectável. Atualmente, funções como fragmentação de dados, separação leitura-gravação, múltiplas cópias de dados, criptografia de dados e testes de estresse de banco de dados sombra, bem como suporte para SQL e protocolos como MySQL, PostgreSQL, SQLServer e Oracle, estão todos integrados ao projeto através de plug-ins. Os desenvolvedores podem personalizar seu próprio sistema exclusivo da mesma forma que usam blocos de construção. Atualmente, o Apache ShardingSphere fornece dezenas de SPIs como pontos de extensão do sistema, e mais ainda estão sendo adicionados.
ShardingSphere-JDBC
Posicionado como uma estrutura Java leve, ele fornece serviços adicionais na camada JDBC do Java. Ele usa o cliente para se conectar diretamente ao banco de dados e fornece serviços na forma de pacotes jar sem implantação e dependências adicionais. Pode ser entendido como uma versão aprimorada do driver JDBC e é totalmente compatível com JDBC e várias estruturas ORM.
Aplicável a qualquer estrutura ORM baseada em JDBC, como: JPA, Hibernate, Mybatis, Spring JDBC Template ou use JDBC diretamente.
Suporta qualquer pool de conexões de banco de dados de terceiros, como: DBCP, C3P0, BoneCP, Druid, HikariCP, etc.
Suporta qualquer banco de dados que implemente a especificação JDBC. Atualmente, suporta MySQL, Oracle, SQLServer, PostgreSQL e qualquer banco de dados que siga o padrão SQL92.
ShardingSphere-Proxy
Posicionado como um agente de banco de dados transparente, fornece um servidor que encapsula o protocolo binário do banco de dados para suportar linguagens heterogêneas. Atualmente são fornecidos MySQL e PostgreSQL. Ele pode usar qualquer cliente de acesso compatível com o protocolo MySQL/PostgreSQL (como MySQL Command Client, MySQL Workbench, Navicat, etc.) para operar dados, tornando-os mais amigáveis para DBAs.
É totalmente transparente para a aplicação e pode ser usado diretamente como servidor MySQL/PostgreSQL.
Aplicável a qualquer cliente compatível com o protocolo MySQL/PostgreSQL.
ShardingSphere-Sidecar (TODO)
Posicionado como um proxy de banco de dados nativo da nuvem para Kubernetes, ele faz proxy de todo o acesso ao banco de dados na forma de Sidecar. Uma solução centerless e de intrusão zero fornece uma camada de engajamento que interage com o banco de dados, ou seja, Database Mesh, também conhecida como grade de banco de dados.
O foco do Database Mesh é como conectar organicamente aplicativos e bancos de dados de acesso a dados distribuídos. Ele se concentra mais na interação e na classificação eficaz das interações entre aplicativos e bancos de dados confusos. Usando o Database Mesh, os aplicativos e bancos de dados que acessam o banco de dados acabarão formando um enorme sistema de grade. Os aplicativos e bancos de dados só precisam ser registrados no sistema de grade.
arquitetura híbrida
ShardingSphere-JDBC adota uma arquitetura descentralizada e é adequado para aplicativos OLTP leves de alto desempenho desenvolvidos em Java; ShardingSphere-Proxy fornece entrada estática e suporte a linguagem heterogênea e é adequado para aplicativos OLAP e gerenciamento e operação de bancos de dados fragmentados.
Apache ShardingSphere é um ecossistema composto por múltiplos terminais de acesso. Ao misturar ShardingSphere-JDBC e ShardingSphere-Proxy e usar o mesmo centro de registro para configurar estratégias de sharding de maneira uniforme, sistemas de aplicativos adequados para vários cenários podem ser construídos com flexibilidade, permitindo que os arquitetos ajustem com mais liberdade o melhor sistema para a arquitetura atual.
1. Fragmentação de dados
Subbiblioteca e subtabela
Separação de leitura e gravação
Personalização da estratégia de fragmentação
Chave primária distribuída não centralizada
2. Transações distribuídas
Interface de transação padronizada
Transações XA fortemente consistentes
Assuntos flexíveis
3. Gerenciamento de banco de dados
Governança distribuída
Escala elástica
Observabilidade (rastreamento distribuído, métricas)
Criptografia e descriptografia de dados
Teste de pressão do manômetro de sombra