Componente de log distribuído Plumelog v3.5.3
3.5.3
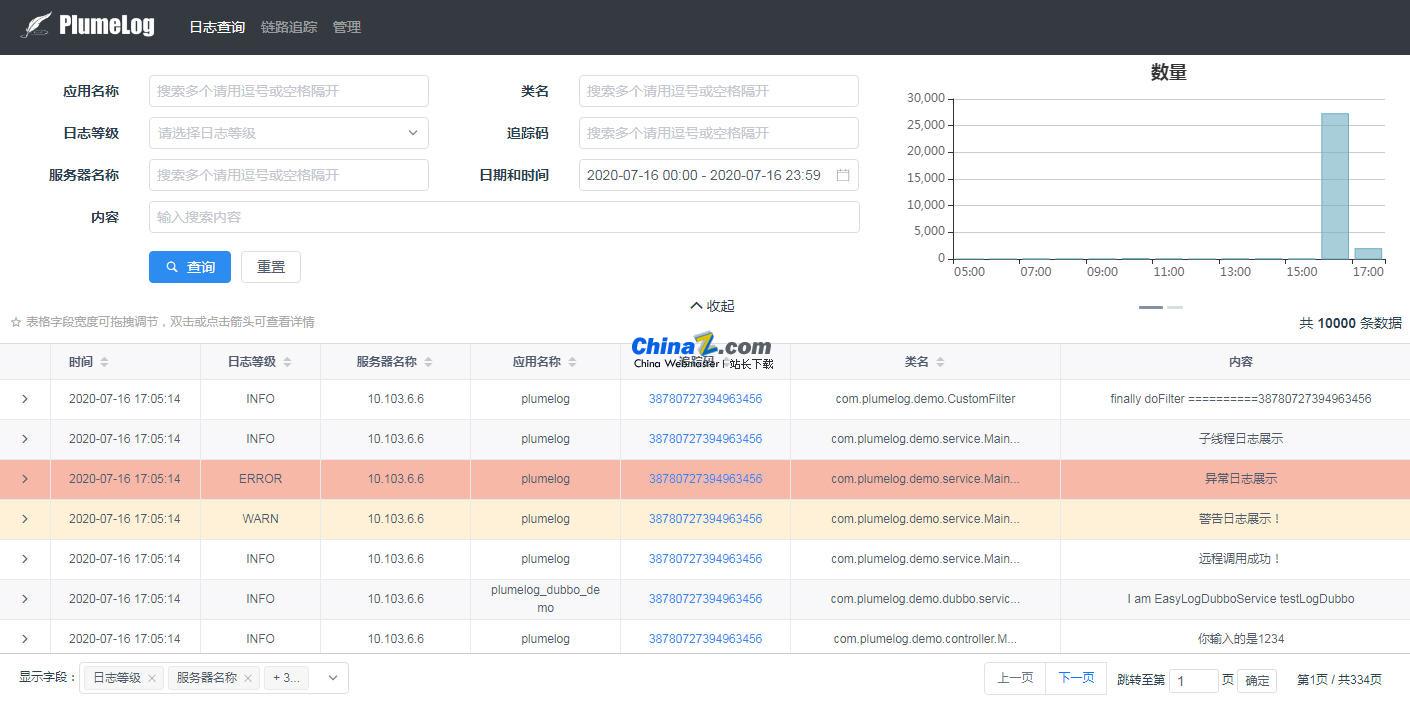
Plumelog é um componente de registro distribuído Java simples e fácil de usar. Suporta dezenas de bilhões de níveis, desde a coleta de logs até a consulta, é conveniente e rápido, sem a necessidade de ler logs em arquivos. Ele oferece suporte à consulta de logs de uma cadeia de chamadas, ao rastreamento de links e à verificação do consumo de tempo da cadeia de chamadas. Você também pode consultar logs relacionados em um sistema distribuído, pode ajudar a localizar problemas rapidamente, é simples e fácil de usar, não possui intrusão de código e possui uma interface de consulta amigável, eficiente e conveniente, desde que você esteja usando um Java. sistema, você não precisa fazer nenhuma modificação no projeto, basta acessá-lo e utilizá-lo diretamente. Os logs não serão salvos no disco local e não há necessidade de se preocupar com a ocupação dos logs. servidor. Se você acha que o projeto é útil, dê uma estrela. Sua estrela é a força motriz para seguirmos em frente.
Introdução à função Plumelog
1. Um sistema de log distribuído não invasivo que coleta logs com base em log4j, log4j2 e logback e define o ID do link para facilitar a consulta de logs relacionados.
2. Baseado no elasticsearch como mecanismo de consulta
3. Alto rendimento e alta eficiência de consulta
4. Todo o processo não ocupa o espaço em disco local da aplicação e é livre de manutenção, é transparente para o projeto e não afeta o funcionamento do projeto em si;
5. Não há necessidade de modificar projetos antigos, introduzir e usar diretamente, apoiar duadfdso, apoiar springcloud
Arquitetura Plumelog
plumelog-core: O componente principal inclui o final da coleta de logs, que é responsável por coletar logs e enviá-los para kafka, redis e outras filas.
plumelog-server: Responsável por gravar logs de forma assíncrona na fila para elasticsearch
plumelog-ui: display front-end, interface de consulta de log
plumelog-demo: caso de uso baseado em springboot
Como usar o Plumelog
Compile e instale você mesmo da seguinte maneira
Pré-requisito: kafka ou redis e elasticsearch (6.8 ou superior é o melhor) podem ser instalados por você mesmo e a compatibilidade foi feita. Não há necessidade de considerar o ES em teoria.
Pacote
maven deploy -DskipTests carrega o pacote para seu próprio servidor privado
Altere o endereço do servidor privado para plumelog/pom.xml
UTF-8
http://172.16.249.94:4000
Registro de atualização do Plumelog
v3.5
Adicionado modo de inicialização lite Neste momento, não há necessidade de configurar redis e es. No modo lite, campos estendidos, estatísticas de erro e alarmes de erro não podem ser usados.
O módulo plumelog-lite foi adicionado. Plumelog-lite existe como um pacote dependente do plumelog. Ele pode ser referenciado diretamente e usado sem implantação.
Adicione um console de log para visualizar a saída em tempo real. É um artefato durante a implantação e o teste. A abertura do console afetará o desempenho, portanto, preste atenção ao tempo de uso.
Corrigido um bug no rastreamento de link onde a camada mais externa pode não ser exibida.
Adicionada detecção automática de ES, sem necessidade de configuração
Aumente a configuração automática do número máximo de fragmentos ES, sem necessidade de configurá-lo manualmente
Otimizou a interface, otimizou o botão salvar fora dos limites da interface de alarme para exibir metade do bug
Otimize a configuração no modo redis Se todos os aplicativos usarem apenas um redis de fila, o redis de gerenciamento não precisará ser configurado. O redis de fila será habilitado automaticamente como o redis de gerenciamento.
Corrija bugs conhecidos e outras otimizações
Usuários antigos podem substituir diretamente o plumelog-server-3.5.jar ao atualizar e reiniciar.
modo lite, você precisa atualizar o cliente para 3.5
Springboot-admin incorporado facilita o gerenciamento de projetos springboot. Você pode usar springbootadmin para ajustar dinamicamente o nível de saída do log.