Versão oficial do data warehouse analítico Apache Kylin v4.0.3
4.0.3
Apache Kylin: uma ferramenta de consulta em menos de um segundo para dados de escala extremamente grande
Editor de códigos de descida
Apache Kylin é um data warehouse analítico distribuído de código aberto que fornece interface de consulta SQL e recursos de análise multidimensional (OLAP) sobre Hadoop/Spark e pode processar com eficiência dados em escala extremamente grande. Originalmente desenvolvido pelo eBay e contribuído para a comunidade de código aberto, ele completa consultas em dados massivos em menos de segundos.
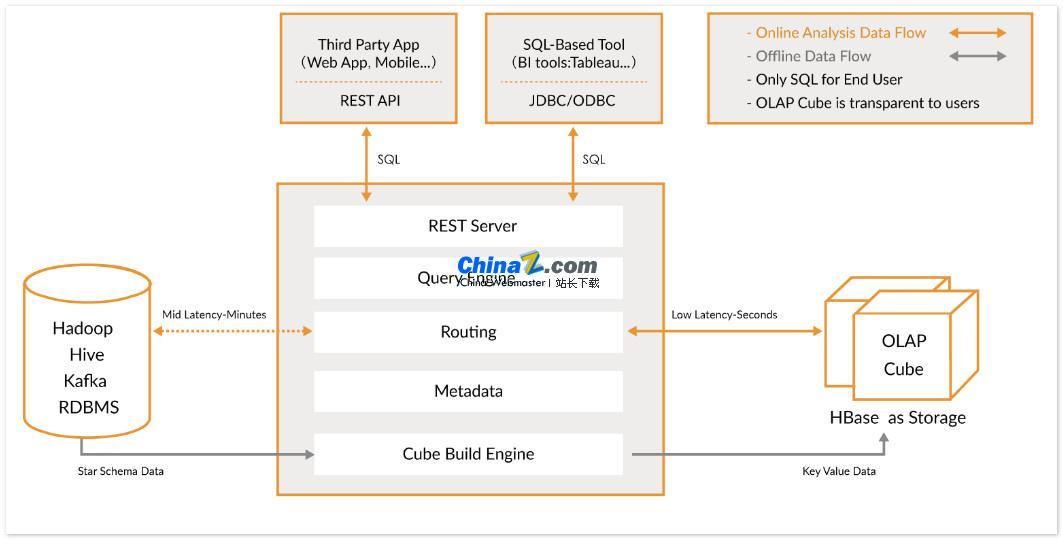
As três etapas principais de Kylin
Kylin permite que os usuários implementem consultas em segundos em conjuntos de dados muito grandes em apenas três etapas:
1. Defina um modelo estrela ou floco de neve em seu conjunto de dados: primeiro, você precisa definir um modelo estrela ou floco de neve para descrever seu conjunto de dados. Isso ajudará Kylin a compreender a relação entre os dados e, assim, otimizar o desempenho da consulta.
2. Construir Cubo: Construir Cubo na tabela de dados definida é a unidade para Kylin pré-calcular e armazenar dados, o que pode melhorar muito a velocidade da consulta.
3. Use consulta SQL padrão: Use a sintaxe SQL padrão para consultar o Cube por meio de ODBC, JDBC ou API RESTFUL pode retornar resultados da consulta em subsegundos.
Capacidades de integração de Kylin
Kylin se integra a uma variedade de ferramentas de visualização de dados, como Tableau, Power BI, etc. Os usuários podem usar essas ferramentas de BI para analisar dados do Hadoop e exibir visualmente insights de dados.
Resumir
Apache Kylin é uma ferramenta poderosa que pode ajudar os usuários a concluir consultas em dados de escala extremamente grande em menos de segundos. Sua facilidade de uso, escalabilidade e eficiência o tornam ideal para lidar com análises de dados em larga escala.