bitnet.cpp é a estrutura de inferência oficial para LLMs de 1 bit (por exemplo, BitNet b1.58). Ele oferece um conjunto de kernels otimizados, que suportam inferência rápida e sem perdas de modelos de 1,58 bits na CPU (com suporte para NPU e GPU em seguida).
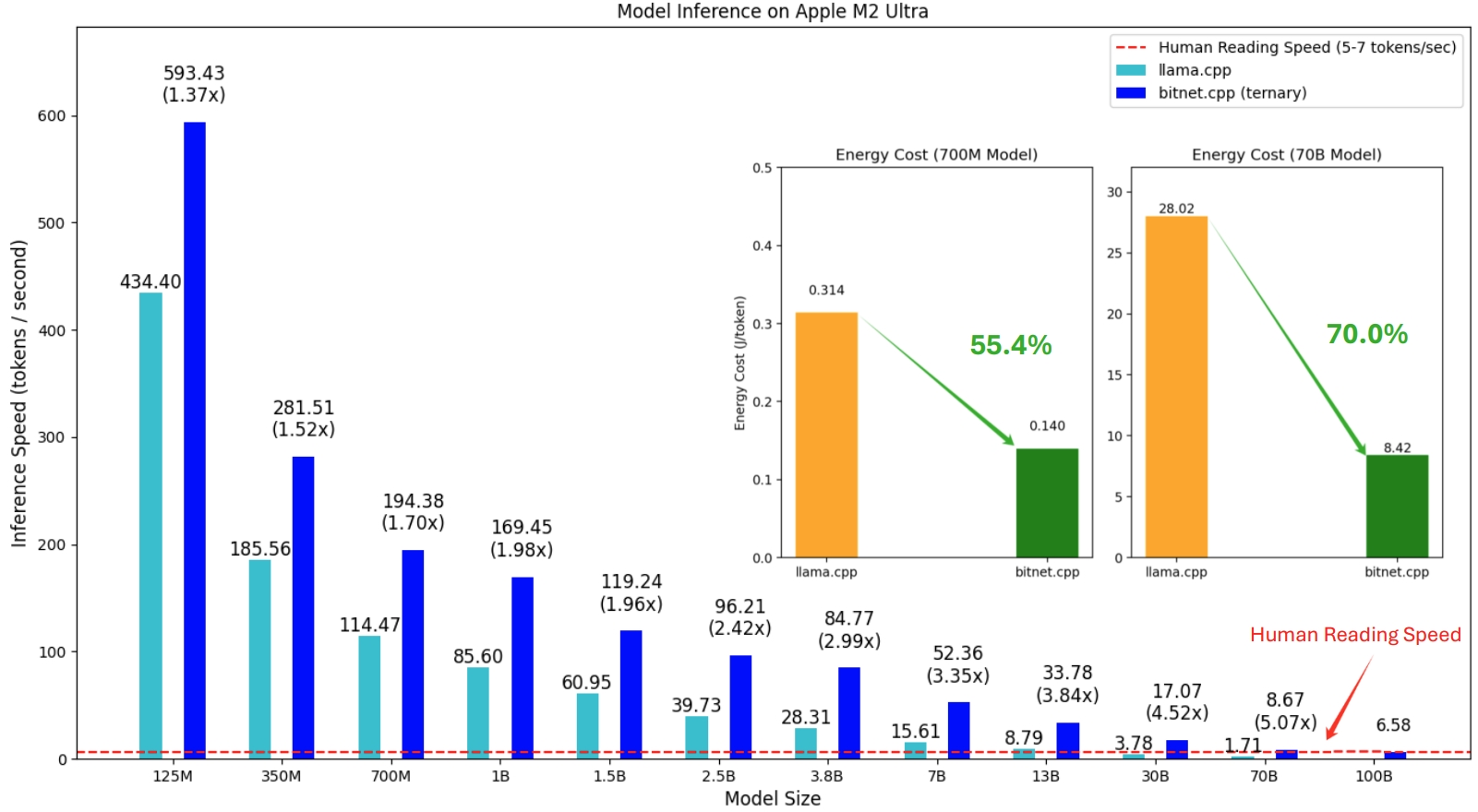
A primeira versão do bitnet.cpp é para oferecer suporte à inferência em CPUs. bitnet.cpp atinge velocidades de 1,37x a 5,07x em CPUs ARM, com modelos maiores apresentando maiores ganhos de desempenho. Além disso, reduz o consumo de energia entre 55,4% e 70,0% , aumentando ainda mais a eficiência geral. Em CPUs x86, as acelerações variam de 2,37x a 6,17x com reduções de energia entre 71,9% a 82,2% . Além disso, o bitnet.cpp pode executar um modelo BitNet b1.58 de 100B em uma única CPU, alcançando velocidades comparáveis à leitura humana (5 a 7 tokens por segundo), aumentando significativamente o potencial de execução de LLMs em dispositivos locais. Consulte o relatório técnico para obter mais detalhes.


Os modelos testados são configurações fictícias usadas em um contexto de pesquisa para demonstrar o desempenho de inferência do bitnet.cpp.
Uma demonstração de bitnet.cpp executando um modelo BitNet b1.58 3B no Apple M2:
21/10/2024 Infraestrutura de IA de 1 bit: Parte 1.1, Inferência BitNet b1.58 rápida e sem perdas em CPUs
17/10/2024 bitnet.cpp 1.0 lançado.
21/03/2024 A era dos LLMs de 1 bit__Training_Tips_Code_FAQ
27/02/2024 A era dos LLMs de 1 bit: todos os modelos de linguagem grande estão em 1,58 bits
17/10/2023 BitNet: Dimensionando transformadores de 1 bit para modelos de linguagem grande
Este projeto é baseado na estrutura llama.cpp. Gostaríamos de agradecer a todos os autores por suas contribuições à comunidade de código aberto. Além disso, os kernels do bitnet.cpp são construídos com base nas metodologias Lookup Table pioneiras no T-MAC. Para inferência de LLMs gerais de baixo bit além dos modelos ternários, recomendamos o uso de T-MAC.
❗️ Usamos LLMs de 1 bit existentes disponíveis no Hugging Face para demonstrar os recursos de inferência do bitnet.cpp. Esses modelos não são treinados nem lançados pela Microsoft. Esperamos que o lançamento do bitnet.cpp inspire o desenvolvimento de LLMs de 1 bit em configurações de grande escala em termos de tamanho do modelo e tokens de treinamento.
| Modelo | Parâmetros | CPU | Núcleo | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-grande | 0,7B | x86 | ✔ | ✘ | ✔ |
| BRAÇO | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3,3B | x86 | ✘ | ✘ | ✔ |
| BRAÇO | ✘ | ✔ | ✘ | ||
| Lhama3-8B-1.58-100B-tokens | 8,0B | x86 | ✔ | ✘ | ✔ |
| BRAÇO | ✔ | ✔ | ✘ | ||
píton>=3.9
cmmake>=3,22
clang>=18
Desenvolvimento de desktop com C++
Ferramentas C++-CMake para Windows
Git para Windows
Compilador C++-Clang para Windows
Suporte MS-Build para conjunto de ferramentas LLVM (clang)
Para usuários do Windows, instale o Visual Studio 2022. No instalador, ative pelo menos as seguintes opções (isso também instala automaticamente as ferramentas adicionais necessárias, como CMake):
Para usuários Debian/Ubuntu, você pode baixar com script de instalação automática
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
conda (altamente recomendado)
Importante
Se você estiver usando Windows, lembre-se de sempre usar um prompt de comando do desenvolvedor/PowerShell para VS2022 para os seguintes comandos
Clonar o repositório
git clone --recursivo https://github.com/microsoft/BitNet.gitcd BitNet
Instale as dependências
# (Recomendado) Crie um novo ambiente condaconda create -n bitnet-cpp python=3.9 conda ativar bitnet-cpp pip instalar -r requisitos.txt
Construa o projeto
# Baixe o modelo do Hugging Face, converta-o para o formato gguf quantizado e construa o projetopython setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# Ou você pode baixar manualmente o modelo e execute com pathhuggingface-cli local baixe HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens python setup_env.py -md modelos/Llama3-8B-1.58-100B-tokens -q i2_s
uso: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [ --log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd]
[--use-pretuned]
Configure o ambiente para executar inferência
argumentos opcionais:
-h, --help mostra esta mensagem de ajuda e sai
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3- 8B-1.58-100B-tokens}
Modelo usado para inferência
--model-dir MODEL_DIR, -md MODEL_DIR
Diretório para salvar/carregar o modelo
--log-dir LOG_DIR, -ld LOG_DIR
Diretório para salvar as informações de registro
--quant-type {i2_s,tl1}, -q {i2_s,tl1}
Tipo de quantização
--quant-embd Quantiza os embeddings para f16
--use-pretuned, -p Use os parâmetros do kernel pré-ajustados# Execute a inferência com o modelo quantizadopython run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel voltou para o jardim. Mary foi para a cozinha. Sandra foi para a cozinha. Sandra foi para o corredor. John foi para o quarto. Mary voltou para o jardim. Mary foi até a cozinha. Sandra foi até a cozinha. Sandra foi para o corredor. John foi para o quarto. Maria voltou para o jardim. Onde está Maria?# Resposta: Maria está no jardim.
uso: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE]
Executar inferência
argumentos opcionais:
-h, --help mostra esta mensagem de ajuda e sai
-m MODELO, --model MODELO
Caminho para o arquivo de modelo
-n N_PREDICT, --n-prever N_PREDICT
Número de tokens a serem previstos ao gerar texto
-p PROMPT, --prompt PROMPT
Solicitação para gerar texto de
-t TÓPICOS, --threads TÓPICOS
Número de threads a serem usados
-c CTX_SIZE, --ctx-tamanho CTX_SIZE
Tamanho do contexto de prompt
-temp TEMPERATURA, --temperatura TEMPERATURA
Temperatura, um hiperparâmetro que controla a aleatoriedade do texto geradoFornecemos scripts para executar o benchmark de inferência fornecendo um modelo.
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
Aqui está uma breve explicação de cada argumento:
-m , --model : O caminho para o arquivo de modelo. Este é um argumento obrigatório que deve ser fornecido ao executar o script.
-n , --n-token : O número de tokens a serem gerados durante a inferência. É um argumento opcional com valor padrão de 128.
-p , --n-prompt : O número de tokens de prompt a serem usados para gerar texto. Este é um argumento opcional com valor padrão de 512.
-t , --threads : O número de threads a serem usados para executar a inferência. É um argumento opcional com valor padrão 2.
-h , --help : mostra a mensagem de ajuda e sai. Use este argumento para exibir informações de uso.
Por exemplo:
python utils/e2e_benchmark.py -m /caminho/para/modelo -n 200 -p 256 -t 4
Este comando executaria o benchmark de inferência usando o modelo localizado em /path/to/model , gerando 200 tokens a partir de um prompt de 256 tokens, utilizando 4 threads.
Para o layout do modelo que não é compatível com nenhum modelo público, fornecemos scripts para gerar um modelo fictício com o layout do modelo fornecido e executar o benchmark em sua máquina:
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# Execute benchmark com o modelo gerado, use -m para especificar o caminho do modelo, -p para especificar o prompt processado, -n para especificar o número de token para gerarpython utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128