Magika é uma nova ferramenta de detecção de tipo de arquivo alimentada por IA que depende do recente avanço do aprendizado profundo para fornecer detecção precisa. Internamente, o Magika emprega um modelo Keras personalizado e altamente otimizado que pesa apenas alguns MBs e permite a identificação precisa de arquivos em milissegundos, mesmo quando executado em uma única CPU.
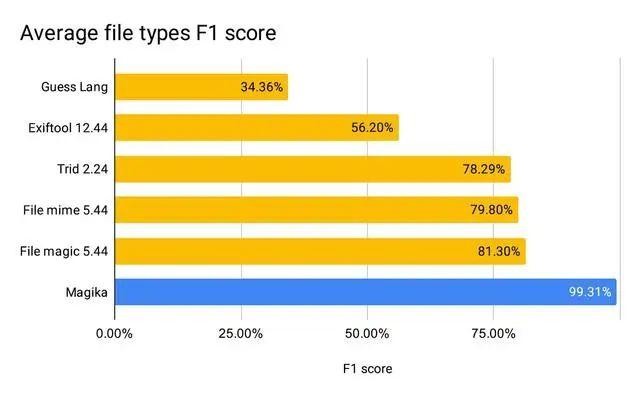
Em uma avaliação com mais de 1 milhão de arquivos e mais de 100 tipos de conteúdo (abrangendo formatos de arquivo binários e textuais), Magika atinge mais de 99% de precisão e recuperação. Magika é usado em grande escala para ajudar a melhorar a segurança dos usuários do Google, roteando arquivos do Gmail, Drive e Navegação segura para os scanners de segurança e política de conteúdo adequados. Leia mais em nosso artigo de pesquisa!
Você pode experimentar o Magika sem instalar nada usando nossa demonstração na web, que roda localmente no seu navegador!
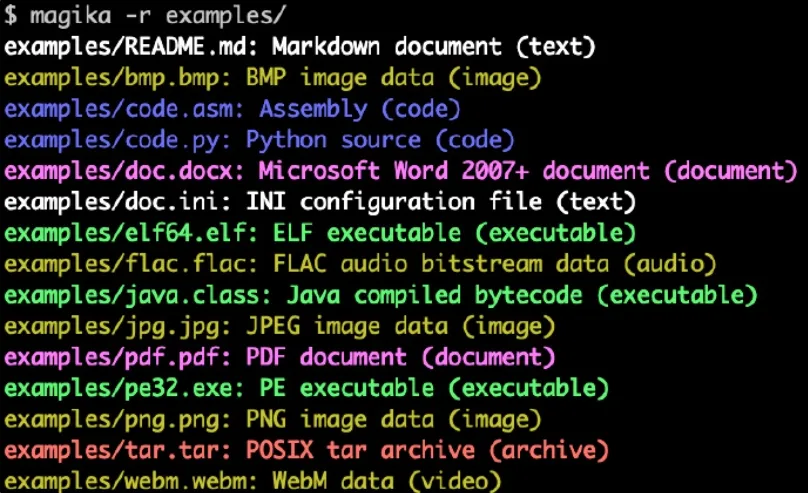
Aqui está um exemplo da aparência da saída da linha de comando do Magika:
Para obter mais contexto, você pode ler nossa postagem de anúncio inicial no blog OSS do Google

Importante
Estamos prestes a lançar uma série de novidades e elas estão prontas para testes!
Um novo modelo de ML com suporte para mais de 200 tipos de conteúdo.
Uma nova CLI escrita em Rust. Isso substituirá a CLI anterior escrita em python. Mais informações aqui. A base de código Rust também pode ser usada para aplicativos escritos em Rust, consulte a documentação.
Pacote Python 0.6.0rc1: esta versão vem com o novo modelo com suporte para mais de 200 tipos de conteúdo, a CLI escrita em Rust (que substitui a antiga escrita em python) e uma API Python renovada com algumas alterações importantes, consulte a documentação e o changelog! Se você precisar de documentos sobre a versão estável, navegue neste repositório na tag estável mais recente, aqui.
Disponível como uma ferramenta de linha de comando escrita em Rust, uma API Python, uma API Rust e uma versão experimental do TFJS (que alimenta nossa demonstração na web).
Treinado em um conjunto de dados de mais de 25 milhões de arquivos em mais de 100 tipos de conteúdo.
Em nossa avaliação, Magika atinge 99%+ de precisão e recall médios, superando as abordagens existentes.
Mais de 200 tipos de conteúdo (veja a lista completa).
Depois que o modelo é carregado (esta é uma sobrecarga única), o tempo de inferência é de cerca de 5 ms por arquivo.
Lote: você pode passar para a linha de comando e vários arquivos da API ao mesmo tempo, e o Magika usará o lote para acelerar o tempo de inferência. Você pode invocar o Magika até com milhares de arquivos ao mesmo tempo. Você também pode usar -r para verificar recursivamente um diretório.
Tempo de inferência quase constante, independentemente do tamanho do arquivo; Magika usa apenas um subconjunto limitado de bytes do arquivo.
Magika usa um sistema de limite por tipo de conteúdo que determina se deve "confiar" na previsão do modelo ou se deve retornar um rótulo genérico, como "Documento de texto genérico" ou "Dados binários desconhecidos".
Suporta três modos de previsão diferentes, que ajustam a tolerância a erros: high-confidence , medium-confidence e best-guess .
É código aberto! (E mais ainda está por vir.)
Para obter mais detalhes, consulte a documentação do pacote python e do pacote js (dev docs).
Começando
Linha de comando Python
API Python
Modelo experimental TFJS e pacote npm
Instalação
Executando no Docker
Uso
Configuração de desenvolvimento
Documentação Importante
Limitações conhecidas e contribuições
Perguntas frequentes
Recursos Adicionais
Artigo de pesquisa e citação
Licença
Isenção de responsabilidade
Magika está disponível como magika no PyPI:
$ pip instalar magika
Se você pretende usar Magika apenas como linha de comando, você pode usar $ pipx install magika .
git clone https://github.com/google/magika cd magika/ docker build -t magika . docker run -it --rm -v $(pwd):/magika magika -r /magika/tests_data
A nova linha de comando é escrita em Rust e está disponível no pacote magika python.
Exemplos:
$ cd testes_data/basic && magika -r *asm/code.asm: Montagem (código) batch/simple.bat: arquivo em lote DOS (código) c/code.c: fonte C (código) css/code.css: fonte CSS (código) csv/magika_test.csv: documento CSV (código) dockerfile/Dockerfile: Dockerfile (código) docx/doc.docx: documento do Microsoft Word 2007+ (documento) epub/doc.epub: documento EPUB (documento) epub/magika_test.epub: documento EPUB (documento) flac/test.flac: dados de fluxo de bits de áudio FLAC (áudio) handlebars/example.handlebars: Fonte do guidão (código) html/doc.html: documento HTML (código) ini/doc.ini: arquivo de configuração INI (texto) javascript/code.js: fonte JavaScript (código) jinja/example.j2: modelo Jinja (código) jpeg/magika_test.jpg: dados de imagem JPEG (imagem) json/doc.json: documento JSON (código) latex/sample.tex: documento LaTeX (texto) makefile/simple.Makefile: fonte do Makefile (código) markdown/README.md: documento Markdown (texto) [...]
$ magika ./tests_data/basic/python/code.py --json
[
{ "caminho": "./tests_data/basic/python/code.py", "resultado": { "status": "ok", "valor": { "dl": { "descrição": "Fonte Python" , "extensões": [ "py", "pyi"
], "grupo": "código", "is_text": true, "label": "python", "mime_type": "texto/x-python"
}, "saída": { "descrição": "Fonte Python", "extensões": [ "py", "pyi"
], "grupo": "código", "is_text": true, "label": "python", "mime_type": "texto/x-python"
}, "pontuação": 0,753000020980835
}
}
}
]$ gato doc.ini | magia - -: arquivo de configuração INI (texto)
$ magika --help
Determina o tipo de conteúdo dos arquivos com aprendizado profundo
Uso: magika [OPÇÕES] [CAMINHO]...
Argumentos: [PATH]...
Lista de caminhos para os arquivos a serem analisados.
Use um traço (-) para ler a entrada padrão (só pode ser usado uma vez).
Opções:
-r, --recursivo
Identifica arquivos dentro de diretórios em vez de identificar o próprio diretório
--no-dereference
Identifica links simbólicos como estão, em vez de identificar seu conteúdo seguindo-os
--cores
Imprime com cores independentemente do suporte do terminal
--sem cores
Imprime sem cores, independentemente do suporte do terminal
-s, --pontuação de saída
Imprime a pontuação de previsão além do tipo de conteúdo
-i, --mime-type
Imprime o tipo MIME em vez da descrição do tipo de conteúdo
-l, --rótulo
Imprime um rótulo simples em vez da descrição do tipo de conteúdo
--json
Imprime no formato JSON
--jsonl
Imprime no formato JSONL
--format <PERSONALIZADO>
Imprime usando um formato personalizado (use --help para detalhes).
Os seguintes espaços reservados são suportados:
%p O caminho do arquivo
%l O rótulo exclusivo que identifica o tipo de conteúdo
%d A descrição do tipo de conteúdo
%g O grupo do tipo de conteúdo
%m O tipo MIME do tipo de conteúdo
%e Possíveis extensões de arquivo para o tipo de conteúdo
%s A pontuação do tipo de conteúdo do arquivo
%S A pontuação do tipo de conteúdo do arquivo em porcentagem
%b A saída do modelo se for anulada (vazia caso contrário)
%% Uma % literal
-h, --ajuda
Imprimir ajuda (veja um resumo com '-h')
-V, --versão
Versão impressaVeja aqui para documentação mais detalhada.
Exemplos:
>>> from magika import Magika>>> m = Magika()>>> res = m.identify_bytes(b"# ExemplonEste é um exemplo de markdown!")>>> print(res.output.label)markdown
Consulte a documentação do python para obter documentação detalhada.
Também fornecemos Magika como um pacote experimental para pessoas interessadas em usar um aplicativo web. Observe que o desempenho da implementação do Magika JS é significativamente mais lento e você deve esperar gastar mais de 100 ms por arquivo.
Consulte a documentação js para obter detalhes.
Consulte a seção "Configuração de desenvolvimento" na documentação do python.
Documentação sobre a CLI
Documentação sobre o novo Rust CLI
Documentação sobre as ligações para diferentes idiomas
Lista de tipos de conteúdo suportados (para v1, mais em breve).
Lista de tipos de conteúdo suportados para o novo modelo
Documentação sobre como interpretar a saída do Magika.
Perguntas frequentes
Magika melhora significativamente em relação ao estado da arte, mas sempre há espaço para melhorias! Mais trabalho pode ser feito para aumentar a precisão da detecção, suporte para tipos de conteúdo adicionais, ligações para mais idiomas, etc.
Esta versão inicial não tem como alvo a detecção poliglota e estamos ansiosos para ver exemplos adversários da comunidade. Também adoraríamos ouvir a comunidade sobre problemas encontrados, detecções incorretas, solicitações de recursos, necessidade de suporte para tipos de conteúdo adicionais, etc.
Verifique nossos problemas abertos do GitHub para ver o que está em nosso roteiro e relate erros de detecção ou solicitações de recursos abrindo problemas do GitHub (preferencial) ou enviando um e-mail para [email protected].
NOTA: NÃO envie relatórios sobre arquivos que possam conter PII, o relatório contém (uma pequena) parte do conteúdo do arquivo!
Consulte CONTRIBUTING.md para obter detalhes.
Coletamos uma série de perguntas frequentes aqui.
Postagem no blog OSS do Google sobre o anúncio do Magika.
Demonstração da web: demonstração da web.
Descrevemos como desenvolvemos o Magika e as escolhas que fizemos em nosso artigo de pesquisa.
Se você usa este software para sua pesquisa, cite-o como:
@misc{magika, title={{Magika: detecção de tipo de conteúdo baseada em IA}}, autor={{Fratantonio, Yanick e Invernizzi, Luca e Farah, Loua e Kurt, Thomas e Zhang, Marina e Albertini, Ange e Galilee , François e Metitieri, Giancarlo e Cretin, Julien e Petit-Bianco, Alexandre e Tao, David e Bursztein, Elie}}, ano={2024}, eprint={2409.13768}, archivePrefix={arXiv}, primáriaClass={cs. CR}, url={https://arxiv.org/abs/2409.13768},
}Entre em contato conosco diretamente em [email protected]
Apache2.0; consulte LICENSE para obter detalhes.
Este projeto não é um projeto oficial do Google. Não é suportado pelo Google e o Google isenta-se especificamente de todas as garantias quanto à sua qualidade, comercialização ou adequação a uma finalidade específica.