rodada automática
Intel®
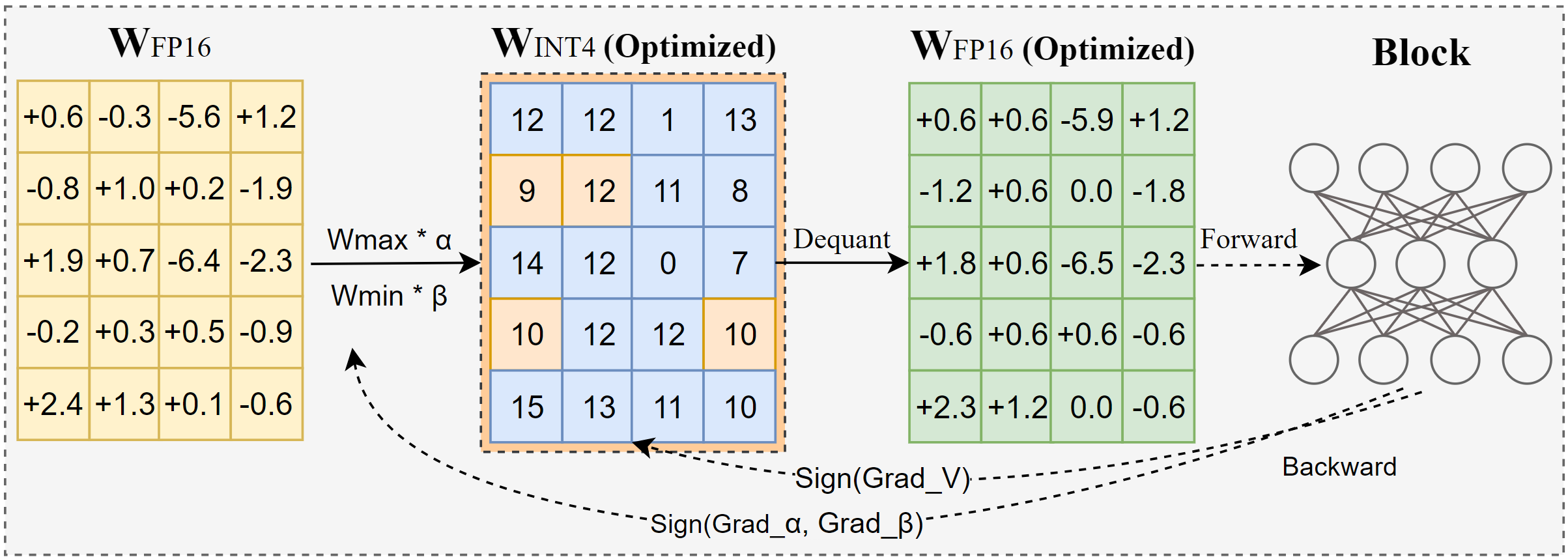
AutoRound é um algoritmo de quantização avançado para inferência LLM de bits baixos. É adaptado para uma ampla gama de modelos. O AutoRound adota descida de gradiente de sinal para ajustar valores de arredondamento e valores minmax de pesos em apenas 200 etapas, o que compete de forma impressionante com métodos recentes sem introduzir qualquer sobrecarga de inferência adicional e mantendo baixo custo de ajuste. A imagem abaixo apresenta uma visão geral do AutoRound. Confira nosso artigo sobre arxiv para obter mais detalhes e visite low_bit_open_llm_leaderboard para dados e receitas mais precisos em vários modelos.


[2024/10] AutoRound foi integrado ao torch/ao, confira a nota de lançamento
[2024/10] Atualização importante: agora oferecemos suporte à quantização simétrica de faixa completa e a tornamos a configuração padrão. Esta configuração é normalmente melhor ou comparável à quantização assimétrica e supera significativamente outras variantes simétricas, especialmente em larguras de bits baixas, como 2 bits.
[2024/09] O formato AutoRound suporta diversos modelos LVM, confira os exemplos Qwen2-Vl,Phi-3-vision, Llava
[2024/08] O formato AutoRound suporta dispositivos Intel Gaudi2. Consulte Intel/Qwen2-7B-int4-inc.
[2024/08] AutoRound introduz vários recursos experimentais, incluindo ajuste rápido de parâmetros de norma/viés (para 2 bits e W4A4), quantização de ativação e o tipo de dados mx_fp.
pip install -vvv --no-build-isolation -e .
pip instalar rodada automática
Um guia do usuário detalhando a lista completa de argumentos suportados é fornecido chamando auto-round -h no terminal. Alternativamente, você pode usar auto_round em vez de auto-round . Defina o format desejado e a exportação de vários formatos é suportada.
CUDA_VISIBLE_DEVICES=0 rodada automática
--modelo facebook/opt-125m
--bits 4
--group_size 128
--format "auto_round,auto_gptq"
--disable_eval
--output_dir./tmp_autoroundFornecemos duas receitas para melhor precisão e velocidade de execução rápida com pouca memória. Detalhes conforme abaixo.
## melhor precisão, 3X mais lento, low_gpu_mem_usage pode economizar ~20G, mas ~30% mais lentoCUDA_VISIBLE_DEVICES=0 auto-round --modelo facebook/opt-125m --bits 4 --group_size 128 --nsamples 512 --iters 1000 --low_gpu_mem_usage --disable_eval
## memória rápida e com pouca memória, aceleração de 2-3X, leve queda de precisão em W4G128CUDA_VISIBLE_DEVICES=0 rodada automática --modelo facebook/opt-125m --bits 4 --group_size 128 --nsamples 128 --iters 200 --seqlen 512 --batch_size 4 --disable_eval
Formato AutoRound : Este formato é adequado para CPU, dispositivos HPU, 2 bits, bem como inferência de precisão mista. [2,4] bits são suportados. Ele também se beneficia do kernel Marlin, que pode aumentar notavelmente o desempenho da inferência. No entanto, ainda não obteve ampla adoção pela comunidade.
Formato AutoGPTQ : Este formato é adequado para quantização simétrica em dispositivos CUDA e é amplamente adotado pela comunidade, [2,3,4,8] bits são suportados. Ele também se beneficia do kernel Marlin, que pode aumentar notavelmente o desempenho da inferência. No entanto, o kernel assimétrico apresenta problemas que podem causar quedas consideráveis na precisão, principalmente na quantização de 2 bits e em modelos pequenos. Além disso, a quantização simétrica tende a ter um desempenho ruim com precisão de 2 bits.
Formato AutoAWQ : Este formato é adequado para quantização assimétrica de 4 bits em dispositivos CUDA e é amplamente adotado na comunidade, apenas a quantização de 4 bits é suportada. Possui fusão de camadas especializada adaptada para modelos Llama.
de transformadores import AutoModelForCausalLM, AutoTokenizermodel_name = "facebook/opt-125m"model = AutoModelForCausalLM.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)from auto_round import AutoRoundbits, group_size, sym = 4, 128, Trueautoround = AutoRound(model, tokenizer , bits=bits, group_size=group_size, sym=sym)## a melhor precisão, 3X mais lento, low_gpu_mem_usage pode economizar ~20G, mas ~30% mais lento# autoround = AutoRound(model, tokenizer, nsamples=512, iters=1000, low_gpu_mem_usage =True, bits=bits, group_size=group_size, sym=sym)## memória rápida e baixa, aceleração de 2-3X, ligeira queda de precisão em W4G128# autoround = AutoRound(model, tokenizer, nsamples=128, iters=200, seqlen =512, batch_size=4, bits=bits, group_size=group_size, sym=sym )autoround.quantize()output_dir = "./tmp_autoround"## format= 'auto_round'(padrão na versão> 0.3.0), 'auto_gptq ', 'auto_awq'autoround.save_quantized(output_dir, formato='auto_round', inplace=True)
Os testes foram realizados na Nvidia A100 80G usando a versão noturna do PyTorch 2.6.0.dev20241029+cu124. Observe que os custos de carregamento e embalagem de dados foram excluídos da avaliação. Habilitamos torch.compile para Torch 2.6, mas não para 2.5 devido a problemas encontrados.
Para otimizar o uso de memória da GPU, além de ativar low_gpu_mem_usage , você pode definir gradient_accumulate_steps=8 e batch_size=1 , embora isso possa aumentar o tempo de ajuste.
Os modelos 3B e 14B foram avaliados no Qwen 2.5, o modelo 8X7B é Mixtral, enquanto os demais modelos utilizaram LLaMA 3.1.
| Versão/configuração da tocha W4G128 | 3B | 8B | 14B | 70B | 8X7B |
|---|---|---|---|---|---|
| 2.6 com compilação da tocha | 7 minutos 10 GB | 12 minutos 18 GB | 23 minutos 22 GB | 120 minutos 42 GB | 28 minutos 46 GB |
| 2.6 com compilação da tocha low_gpu_mem_usage=Verdadeiro | 12 minutos 6GB | 19 minutos 10 GB | 33 minutos 11 GB | 140 minutos 25 GB | 38 minutos 36 GB |
| 2.6 com compilação da tocha low_gpu_mem_usage=Verdadeiro gradiente_accumulate_steps=8,bs=1 | 15 minutos 3GB | 25 minutos 6GB | 45 minutos 7 GB | 187 minutos 19 GB | 75 minutos 36 GB |
| 2.5 sem compilação da tocha | 8 minutos 10 GB | 16 minutos 20 GB | 30 minutos 25 GB | 140 minutos 49 GB | 50 minutos 49 GB |
Por favor, execute o código de quantização primeiro
CPU : versão auto_round> 0.3.1 , pip install intel-extension-for-pytorch (velocidade muito maior na CPU Intel) ou pip install intel-extension-for-transformers,
HPU : imagem docker com Gaudi Software Stack é recomendada. Mais detalhes podem ser encontrados no Guia Gaudi.
CUDA : sem operações extras para quantização simbólica, para quantização assimétrica, é necessário instalar o arredondamento automático da fonte
from transformers import AutoModelForCausalLM, AutoTokenizerfrom auto_round import AutoRoundConfigbackend = "auto" ##cpu, hpu, cuda, cuda:marlin(suportado em auto_round>0.3.1 e 'pip install -v gptqmodel --no-build-isolation')quantization_config = AutoRoundConfig(backend=backend)quantized_model_path = "./tmp_autoround"model = AutoModelForCausalLM.from_pretrained(quantized_model_path, device_map=backend.split(':')[0], quantization_config=quantization_config)tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)text = " Tem uma garota que gosta de aventura,"inputs = tokenizer(text, return_tensors="pt").to(model.device)print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]) ) rodada automática --model salvo_quantizado_modelo
--eval
--task lambada_openai
--eval_bs 1from transformers import AutoModelForCausalLM, AutoTokenizerquantized_model_path = "./tmp_autoround"model = AutoModelForCausalLM.from_pretrained(quantized_model_path, device_map="auto")tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)text = "Tem uma garota que gosta de aventura,"inputs = tokenizer( texto, return_tensors="pt").to(model.device)print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]))
AutoRound suporta basicamente todos os principais modelos de linguagem grande.
Observe que um asterisco (*) indica modelos quantizados de terceiros, que podem não ter dados de precisão e usar uma receita diferente. Agradecemos imensamente seus esforços e encorajamos mais usuários a compartilharem seus modelos, já que não podemos lançar a maioria dos modelos sozinhos.
| Modelo | Suportado |
|---|---|
| meta-lhama/Meta-Llama-3.1-70B-Instruir | receita |
| meta-lhama/Meta-Llama-3.1-8B-Instruir | modelo-kaitchup-autogptq-int4*, modelo-kaitchup-autogptq-sym-int4*, receita |
| metal-lhama/Meta-lhama-3.1-8B | modelo-kaitchup-autogptq-sym-int4* |
| Qwen/Qwen-VL | precisão, receita |
| Qwen/Qwen2-7B | modelo-autoround-sym-int4, modelo-autogptq-sym-int4 |
| Qwen/Qwen2-57B-A14B-Instrução | modelo-autoround-sym-int4,model-autogptq-sym-int4 |
| 01-ai/Yi-1.5-9B | modelo-LnL-AI-autogptq-int4* |
| 01-ai/Yi-1.5-9B-Chat | modelo-LnL-AI-autogptq-int4* |
| Intel/neural-chat-7b-v3-3 | modelo-autogptq-int4 |
| Intel/neural-chat-7b-v3-1 | modelo-autogptq-int4 |
| TinyLlama-1.1B-intermediário | modelo-LnL-AI-autogptq-int4* |
| mistralai/Mistral-7B-v0.1 | modelo-autogptq-lmhead-int4, modelo-autogptq-int4 |
| google/gemma-2b | modelo-autogptq-int4 |
| tiiuae/falcon-7b | modelo-autogptq-int4-G64 |
| sapienzanlp/modello-italia-9b | modelo-fbaldassarri-autogptq-int4* |
| microsoft/phi-2 | modelo-autoround-sym-int4 modelo-autogptq-sym-int4 |
| microsoft/Phi-3.5-mini-instrução | modelo-kaitchup-autogptq-sym-int4* |
| microsoft/Phi-3-vision-128k-instruct | receita |
| mistralai/Mistral-7B-Instruct-v0.2 | precisão, receita, exemplo |
| mistralai/Mixtral-8x7B-Instruct-v0.1 | precisão, receita, exemplo |
| mistralai/Mixtral-8x7B-v0.1 | precisão, receita, exemplo |
| meta-lhama/Meta-Llama-3-8B-Instruir | precisão, receita, exemplo |
| google/gemma-7b | precisão, receita, exemplo |
| metal-lhama/Llama-2-7b-chat-hf | precisão, receita, exemplo |
| Qwen/Qwen1.5-7B-Chat | precisão, receita sym, receita assimétrica, exemplo |
| baichuan-inc/Baichuan2-7B-Chat | precisão, receita, exemplo |
| 01-ai/Yi-6B-Chat | precisão, receita, exemplo |
| facebook/opt-2.7b | precisão, receita, exemplo |
| bigscience/bloom-3b | precisão, receita, exemplo |
| EleutherAI/gpt-j-6b | precisão, receita, exemplo |
AutoRound foi integrado em vários repositórios.
Compressor Neural Intel
ModeloCloud/GPTQModel
pytorch/ao
Se você achar o AutoRound útil para sua pesquisa, cite nosso artigo:
@artigo{cheng2023otimizar,
title={Otimize o arredondamento de peso por meio de gradiente descendente assinado para a quantização de LLMs},
autor = {Cheng, Wenhua e Zhang, Weiwei e Shen, Haihao e Cai, Yiyang e He, Xin e Lv, Kaokao e Liu, Yi},
diário = {pré-impressão arXiv arXiv:2309.05516},
ano={2023}
}