kotaemon
v0.7.6
Uma UI RAG de código aberto, limpa e personalizável para conversar com seus documentos. Construído pensando tanto nos usuários finais quanto nos desenvolvedores.
Demonstração ao vivo | Instalação on-line | Guia do usuário | Guia do desenvolvedor | Comentários | Contato
Este projeto serve como uma UI RAG funcional para usuários finais que desejam fazer controle de qualidade em seus documentos e desenvolvedores que desejam construir seu próprio pipeline RAG.
+---------------------------------------------------------------- ---------------------------+| Usuários finais: aqueles que usam aplicativos desenvolvidos com `kotaemon`. || (Você usa um aplicativo como o da demonstração acima) || +---------------------------------------------------------------- ---------------+ || | Desenvolvedores: Aqueles que construíram com `kotaemon`. | || | (Você tem `import kotaemon` em algum lugar do seu projeto) | || | +---------------------------------------------------------------- ---+ | || | | Colaboradores: Aqueles que tornam o `kotaemon` melhor. | | || | | (Você faz PR para este repositório) | | || | +---------------------------------------------------------------- ---+ | || +---------------------------------------------------------------- ---------------+ |+-------------------------------- --------------------------------------------+
UI limpa e minimalista : uma interface amigável para controle de qualidade baseado em RAG.
Suporte para vários LLMs : Compatível com provedores de API LLM (OpenAI, AzureOpenAI, Cohere, etc.) e LLMs locais (via ollama e llama-cpp-python ).
Fácil instalação : scripts simples para você começar rapidamente.
Estrutura para pipelines RAG : ferramentas para construir seu próprio pipeline de controle de qualidade de documentos baseado em RAG.
UI personalizável : veja seu pipeline RAG em ação com a UI fornecida, construída com Gradio.
Tema Gradio : Se você usa Gradio para desenvolvimento, confira nosso tema aqui: kotaemon-gradio-theme.
Hospede sua própria interface da web de controle de qualidade (RAG) de documentos : suporte para login de vários usuários, organize seus arquivos em coleções privadas/públicas, colabore e compartilhe seu bate-papo favorito com outras pessoas.
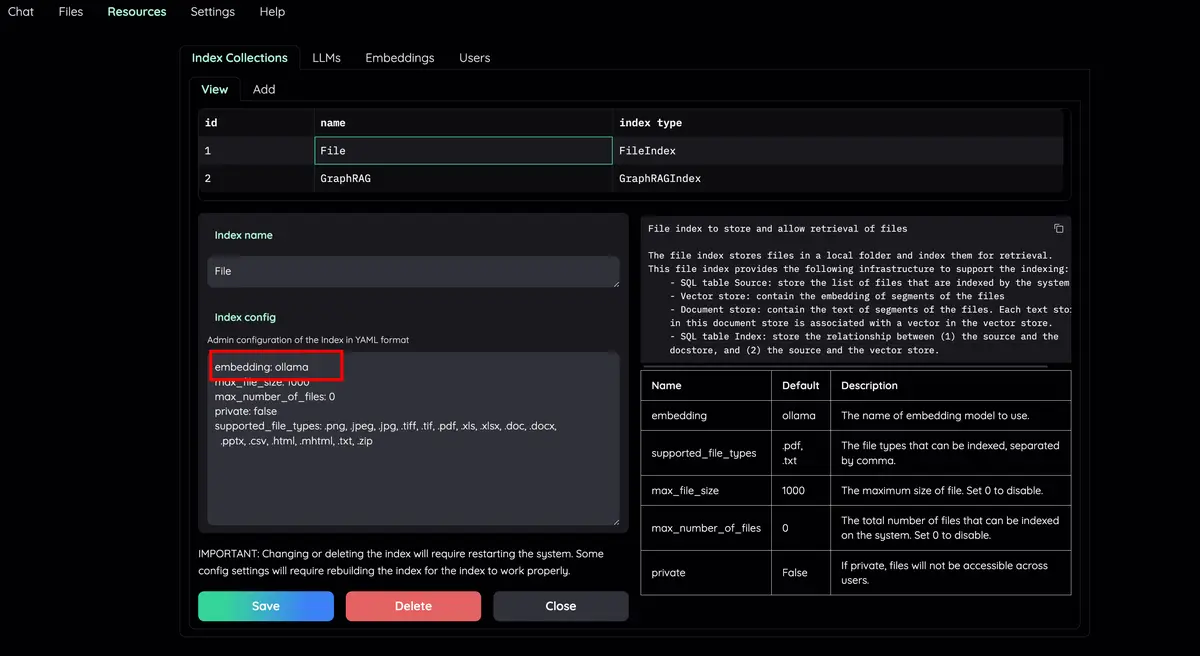
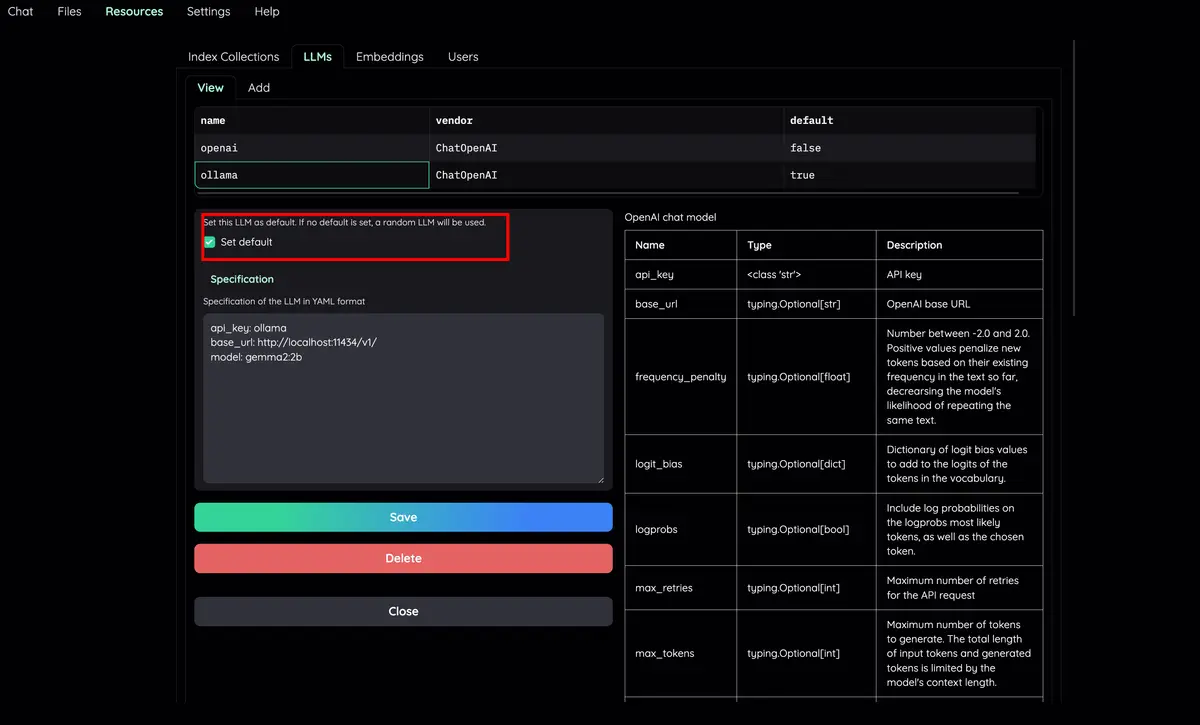
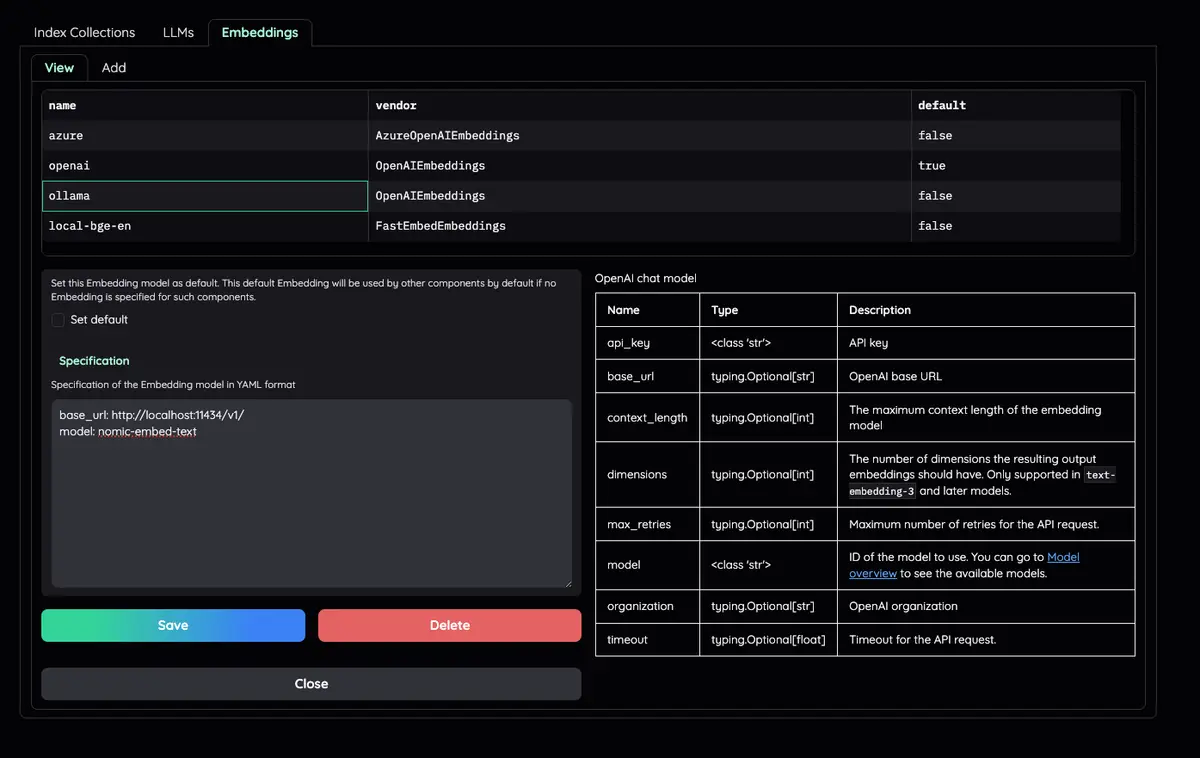
Organize seus modelos de LLM e incorporação : ofereça suporte a LLMs locais e provedores de API populares (OpenAI, Azure, Ollama, Groq).
Pipeline RAG híbrido : pipeline RAG padrão sensato com recuperador híbrido (texto completo e vetor) e reclassificação para garantir a melhor qualidade de recuperação.
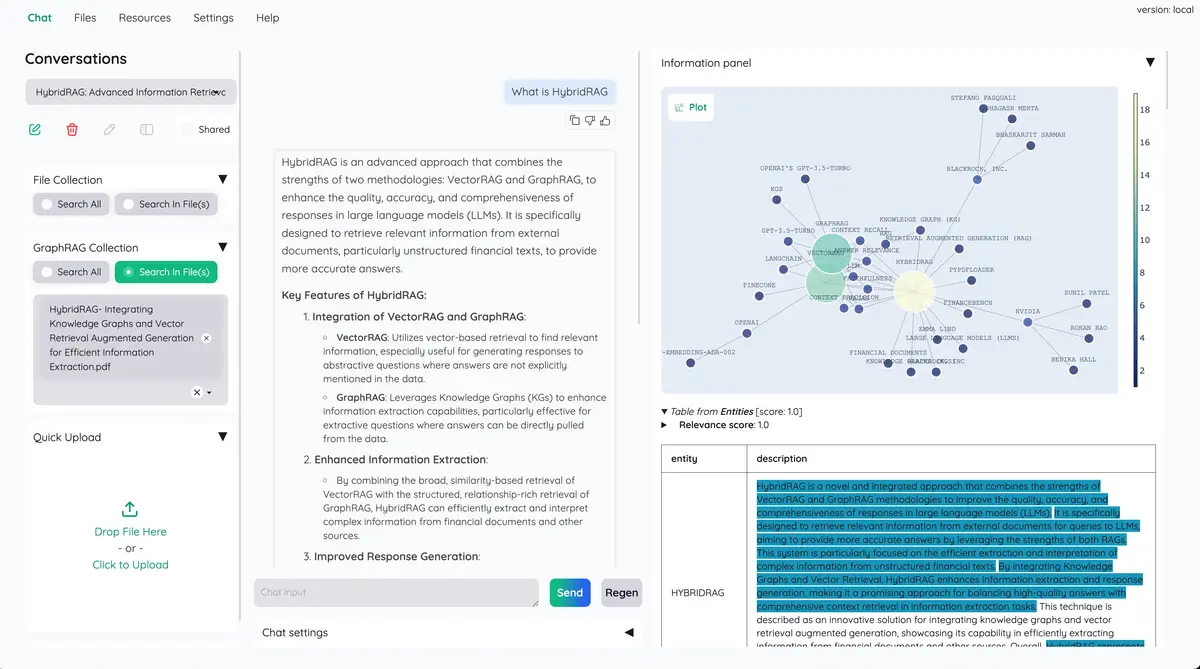
Suporte multimodal para controle de qualidade : responda a perguntas em vários documentos com suporte para figuras e tabelas. Suporta análise multimodal de documentos (opções selecionáveis na interface do usuário).
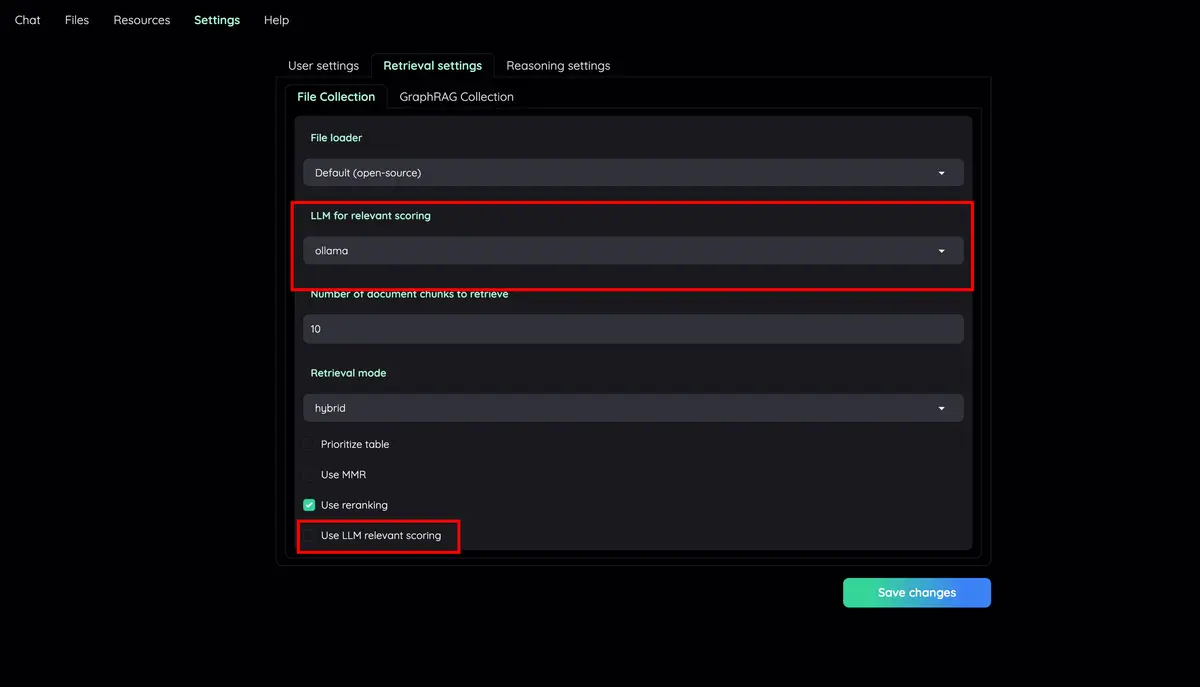
Citações avançadas com visualização do documento : Por padrão, o sistema fornecerá citações detalhadas para garantir a exatidão das respostas do LLM. Visualize suas citações (incluindo pontuação relevante) diretamente no visualizador de PDF no navegador com destaques. Aviso quando o pipeline de recuperação retorna artigos pouco relevantes.
Apoie métodos de raciocínio complexos : use a decomposição de perguntas para responder à sua pergunta complexa/multi-hop. Apoie o raciocínio baseado em agente com ReAct , ReWOO e outros agentes.
UI de configurações configuráveis : você pode ajustar os aspectos mais importantes do processo de recuperação e geração na UI (incl. prompts).
Extensível : sendo construído no Gradio, você pode personalizar ou adicionar quaisquer elementos da interface do usuário que desejar. Além disso, pretendemos apoiar múltiplas estratégias para indexação e recuperação de documentos. O pipeline de indexação GraphRAG é fornecido como exemplo.
Se você não é um desenvolvedor e deseja apenas usar o aplicativo, consulte nosso Guia do usuário fácil de seguir. Baixe o arquivo
.zipda versão mais recente para obter todos os recursos mais recentes e correções de bugs.
Pitão >= 3.10
Docker: opcional, se você instalar com Docker
Não estruturado se você deseja processar arquivos diferentes de documentos .pdf , .html , .mhtml e .xlsx . As etapas de instalação variam dependendo do seu sistema operacional. Visite o link e siga as instruções específicas fornecidas nele.
Oferecemos suporte às versões lite e full das imagens Docker. Com full , os pacotes extras de unstructured também serão instalados, ele pode suportar tipos de arquivos adicionais ( .doc , .docx , ...) mas o custo é maior no tamanho da imagem do docker. Para a maioria dos usuários, a imagem lite deve funcionar bem na maioria dos casos.
Para usar a versão lite .
execução do docker -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-lite
Para usar a versão full .
execução do docker -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-full
Atualmente oferecemos suporte e testamos duas plataformas: linux/amd64 e linux/arm64 (para Mac mais recente). Você pode especificar a plataforma passando --platform no comando docker run . Por exemplo:
# Para executar o docker com plataforma linux/arm64docker run -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm --plataforma linux/arm64 ghcr.io/cinnamon/kotaemon:main-lite
Depois que tudo estiver configurado corretamente, você pode acessar http://localhost:7860/ para acessar a WebUI.
Usamos GHCR para armazenar imagens docker, todas as imagens podem ser encontradas aqui.
Clone e instale os pacotes necessários em um novo ambiente python.
# opcional (ambiente de configuração)conda create -n kotaemon python=3.10 conda ativar kotaemon# clonar este repositório clone https://github.com/Cinnamon/kotaemoncd kotaemon pip install -e "libs/kotaemon[all]"pip install -e "libs/ktem"
Crie um arquivo .env na raiz deste projeto. Use .env.example como modelo
O arquivo .env existe para servir casos de uso em que os usuários desejam pré-configurar os modelos antes de iniciar o aplicativo (por exemplo, implantar o aplicativo no hub HF). O arquivo só será usado para preencher o banco de dados uma vez na primeira execução, ele não será mais usado nas execuções subsequentes.
(Opcional) Para ativar o visualizador PDF_JS no navegador, baixe PDF_JS_DIST e extraia-o para libs/ktem/ktem/assets/prebuilt
Inicie o servidor web:
aplicativo python.py
O aplicativo será iniciado automaticamente no seu navegador.
O nome de usuário e a senha padrão são admin . Você pode configurar usuários adicionais diretamente pela IU.
Verifique a guia Resources e LLMs and Embeddings e certifique-se de que seu valor api_key esteja definido corretamente em seu arquivo .env . Se não estiver definido, você pode configurá-lo lá.
Observação
A indexação oficial do MS GraphRAG funciona apenas com API OpenAI ou Ollama. Recomendamos que a maioria dos usuários use a implementação NanoGraphRAG para integração direta com Kotaemon.
Instale o nano-GraphRAG: pip install nano-graphrag
A instalação nano-graphrag pode introduzir conflitos de versão, consulte este problema
Para corrigir rapidamente: pip uninstall hnswlib chroma-hnswlib && pip install chroma-hnswlib
Inicie o Kotaemon com a variável de ambiente USE_NANO_GRAPHRAG=true .
Defina seus modelos LLM e incorporação padrão na configuração de Recursos e eles serão reconhecidos automaticamente pelo NanoGraphRAG.
Instalação não Docker : se você não estiver usando o Docker, instale o GraphRAG com o seguinte comando:
pip instalar graphrag futuro
Configurando API KEY : Para usar o recurso de recuperação GraphRAG, certifique-se de definir a variável de ambiente GRAPHRAG_API_KEY . Você pode fazer isso diretamente em seu ambiente ou adicionando-o a um arquivo .env .
Usando modelos locais e configurações personalizadas : se você deseja usar GraphRAG com modelos locais (como Ollama ) ou personalizar o LLM padrão e outras configurações, defina a variável de ambiente USE_CUSTOMIZED_GRAPHRAG_SETTING como true. Em seguida, ajuste suas configurações no arquivo settings.yaml.example .
Consulte Configuração do modelo local.
Por padrão, todos os dados do aplicativo são armazenados na pasta ./ktem_app_data . Você pode fazer backup ou copiar esta pasta para transferir sua instalação para uma nova máquina.
Para usuários avançados ou casos de uso específicos, você pode personalizar estes arquivos:
flowsettings.py
.env
flowsettings.pyEste arquivo contém a configuração da sua aplicação. Você pode usar o exemplo aqui como ponto de partida.
# configure seu armazenamento de documentos preferido (com recursos de pesquisa de texto completo)KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)# configure seu armazenamento de vetores preferido (para pesquisa baseada em vetor)KH_VECTORSTORE=(ChromaDB | LanceDB | InMemory | Qdrant)# Ativar/desativar multimodal QAKH_REASONINGS_USE_MULTIMODAL=True# Configure seu novo pipeline de raciocínio ou modifique o existente.KH_REASONINGS = ["ktem.reasoning.simple.FullQAPipeline","ktem.reasoning.simple.FullDecomposeQAPipeline","ktem.reasoning.react.ReactAgentPipeline","ktem .reasoning.rewoo.RewooAgentPipeline", ]
.envEste arquivo fornece outra maneira de configurar seus modelos e credenciais.
Alternativamente, você pode configurar os modelos por meio do arquivo .env com as informações necessárias para conectar-se aos LLMs. Este arquivo está localizado na pasta do aplicativo. Se você não vê, você pode criar um.
Atualmente, os seguintes provedores são suportados:
Usando servidor compatível com ollama OpenAI:
Usando GGUF com llama-cpp-python
Você pode pesquisar e baixar um LLM para ser executado localmente no Hugging Face Hub. Atualmente, estes formatos de modelo são suportados:
Instale ollama e inicie o aplicativo.
Puxe seu modelo, por exemplo:
ollama puxa lhama3.1:8b ollama pull nomic-embed-text
Defina os nomes dos modelos na UI da web e torne-os padrão:
GGUF
Você deve escolher um modelo cujo tamanho seja menor que a memória do seu aparelho e deve deixar cerca de 2 GB. Por exemplo, se você tem 16 GB de RAM no total, dos quais 12 GB estão disponíveis, então você deve escolher um modelo que ocupe no máximo 10 GB de RAM. Modelos maiores tendem a proporcionar melhor geração, mas também levam mais tempo de processamento.
Aqui estão algumas recomendações e seu tamanho na memória:
Qwen1.5-1.8B-Chat-GGUF: cerca de 2 GB
Adicione um novo modelo LlamaCpp com o nome do modelo fornecido na UI da web.
OpenAI
No arquivo .env , defina a variável OPENAI_API_KEY com sua chave de API OpenAI para permitir o acesso aos modelos do OpenAI. Existem outras variáveis que podem ser modificadas, sinta-se à vontade para editá-las para se adequar ao seu caso. Caso contrário, o parâmetro padrão deverá funcionar para a maioria das pessoas.
OPENAI_API_BASE=https://api.openai.com/v1 OPENAI_API_KEY=OPENAI_CHAT_MODEL=gpt-3.5-turbo OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002
Azure Open AI
Para modelos OpenAI através da plataforma Azure, é necessário fornecer o ponto final do Azure e a chave API. Talvez também seja necessário fornecer o nome dos seus desenvolvimentos para o modelo de chat e o modelo de incorporação, dependendo de como você configurou o desenvolvimento do Azure.
AZURE_OPENAI_ENDPOINT= AZURE_OPENAI_API_KEY= OPENAI_API_VERSION=2024-02-15-visualização AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002
Modelos Locais
Verifique a implementação do pipeline padrão aqui. Você pode fazer ajustes rápidos no funcionamento do pipeline de controle de qualidade padrão.
Adicione uma nova implementação .py em libs/ktem/ktem/reasoning/ e posteriormente inclua-a em flowssettings para habilitá-la na UI.
Verifique a implementação de amostra em libs/ktem/ktem/index/file/graph
(mais instruções WIP).
Como nosso projeto está sendo desenvolvido ativamente, valorizamos muito seus comentários e contribuições. Consulte nosso Guia de contribuição para começar. Obrigado a todos os nossos colaboradores!