(简体中文|Inglês|日本語)
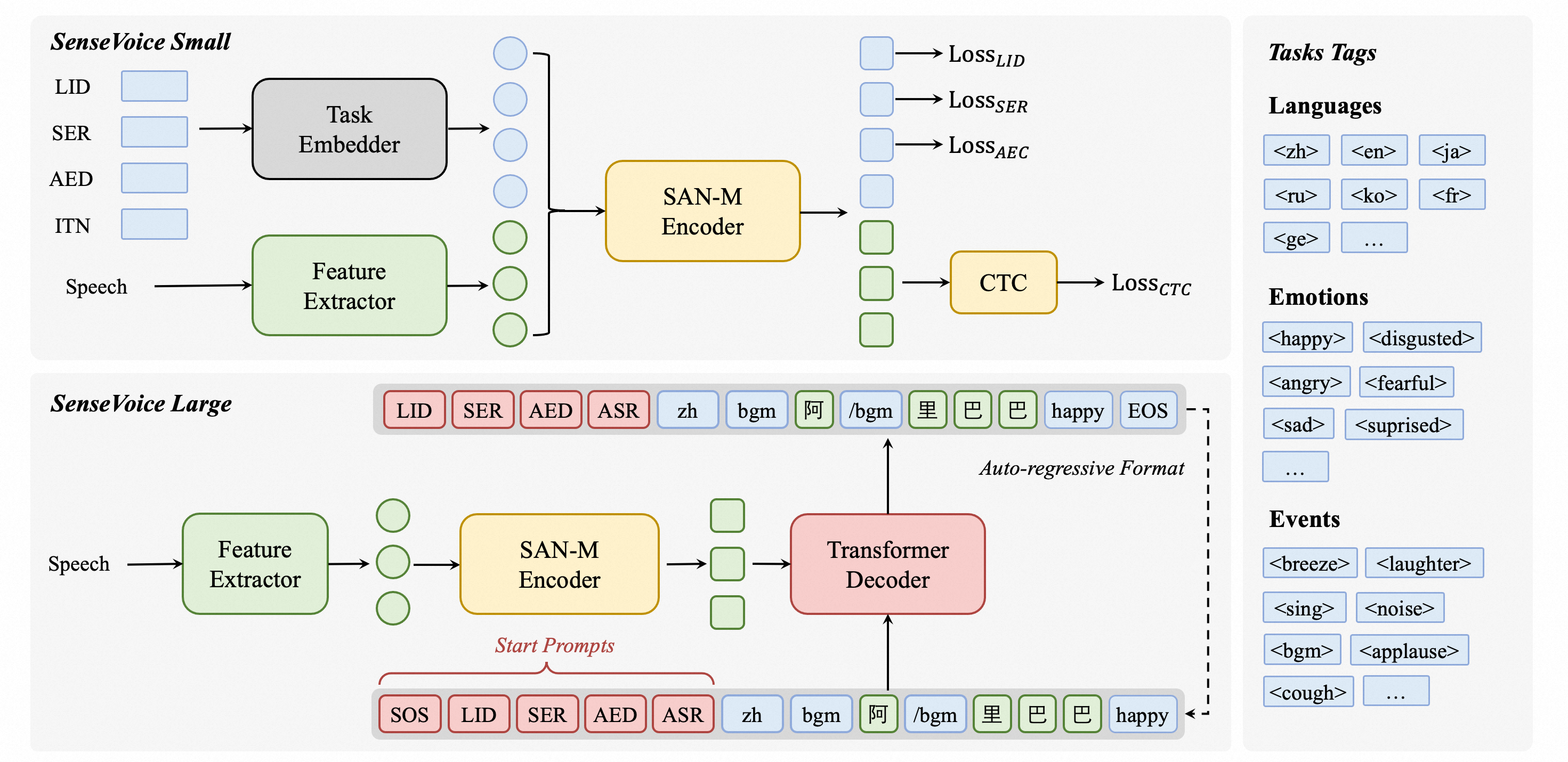
SenseVoice é um modelo básico de fala com vários recursos de compreensão de fala, incluindo reconhecimento automático de fala (ASR), identificação de linguagem falada (LID), reconhecimento de emoção de fala (SER) e detecção de eventos de áudio (AED).

Modelo Zoo: modelscope, abraço
Demonstração on-line: demonstração modelscope, espaço huggingface
SenseVoice se concentra no reconhecimento de fala multilíngue de alta precisão, reconhecimento de emoções de fala e detecção de eventos de áudio.
Comparamos o desempenho do reconhecimento de fala multilíngue entre SenseVoice e Whisper em conjuntos de dados de benchmark de código aberto, incluindo AISHELL-1, AISHELL-2, Wenetspeech, LibriSpeech e Common Voice. Em termos de reconhecimento chinês e cantonês, o modelo SenseVoice-Small apresenta vantagens.


Devido à atual falta de benchmarks e métodos amplamente utilizados para reconhecimento de emoções de fala, realizamos avaliações de várias métricas em vários conjuntos de testes e realizamos uma comparação abrangente com vários resultados de benchmarks recentes. Os conjuntos de testes selecionados abrangem dados em chinês e inglês e incluem vários estilos, como performances, filmes e conversas naturais. Sem ajustes finos nos dados alvo, o SenseVoice foi capaz de alcançar e superar o desempenho dos melhores modelos atuais de reconhecimento de emoções de fala.

Além disso, comparamos vários modelos de reconhecimento de emoções de fala de código aberto nos conjuntos de teste, e os resultados indicam que o modelo SenseVoice-Large alcançou o melhor desempenho em quase todos os conjuntos de dados, enquanto o modelo SenseVoice-Small também superou outros modelos de código aberto em a maioria dos conjuntos de dados.

Embora treinado exclusivamente em dados de fala, o SenseVoice ainda pode funcionar como um modelo independente de detecção de eventos. Comparamos seu desempenho no conjunto de dados de classificação sonora ambiental ESC-50 com os modelos industriais amplamente utilizados BEATS e PANN. O modelo SenseVoice alcançou resultados louváveis nessas tarefas. No entanto, devido a limitações nos dados e metodologia de treinamento, seu desempenho na classificação de eventos apresenta algumas lacunas em comparação com modelos especializados de DEA.

O modelo SenseVoice-Small implanta uma arquitetura ponta a ponta não autorregressiva, resultando em latência de inferência extremamente baixa. Com um número semelhante de parâmetros ao modelo Whisper-Small, ele infere mais de 5 vezes mais rápido que o Whisper-Small e 15 vezes mais rápido que o Whisper-Large.

pip install -r requirements.txtSuporta entrada de áudio em qualquer formato e duração.
from funasr import AutoModel
from funasr . utils . postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel (
model = model_dir ,
trust_remote_code = True ,
remote_code = "./model.py" ,
vad_model = "fsmn-vad" ,
vad_kwargs = { "max_single_segment_time" : 30000 },
device = "cuda:0" ,
)
# en
res = model . generate (
input = f" { model . model_path } /example/en.mp3" ,
cache = {},
language = "auto" , # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn = True ,
batch_size_s = 60 ,
merge_vad = True , #
merge_length_s = 15 ,
)
text = rich_transcription_postprocess ( res [ 0 ][ "text" ])
print ( text )model_dir : o nome do modelo ou o caminho para o modelo no disco local.trust_remote_code :True , significa que a implementação do código do modelo é carregada de remote_code , que especifica a localização exata do código model (por exemplo, model.py no diretório atual). Ele oferece suporte a caminhos absolutos, caminhos relativos e URLs de rede.False , indica que a implementação do código do modelo é a versão integrada dentro do FunASR. Neste momento, as modificações feitas em model.py no diretório atual não terão efeito, pois a versão carregada é a interna do FunASR. Para o código do modelo, clique aqui para visualizar.vad_model : Indica a ativação do VAD (Voice Activity Detection). O objetivo do VAD é dividir áudio longo em clipes mais curtos. Neste caso, o tempo de inferência inclui o consumo total do VAD e do SenseVoice e representa a latência ponta a ponta. Se desejar testar o tempo de inferência do modelo SenseVoice separadamente, o modelo VAD pode ser desativado.vad_kwargs : Especifica as configurações do modelo VAD. max_single_segment_time : denota a duração máxima para segmentação de áudio pelo vad_model , sendo a unidade milissegundos (ms).use_itn : se o resultado de saída inclui pontuação e normalização inversa de texto.batch_size_s : Indica o uso de batching dinâmico, onde a duração total do áudio no lote é medida em segundos(s).merge_vad : Se deseja mesclar pequenos fragmentos de áudio segmentados pelo modelo VAD, com a duração mesclada sendo merge_length_s , em segundos (s).ban_emo_unk : Se deve banir a saída do token emo_unk . Se todas as entradas forem áudios curtos (<30s) e a inferência em lote for necessária para acelerar a eficiência da inferência, o modelo VAD poderá ser removido e batch_size poderá ser definido adequadamente.
model = AutoModel ( model = model_dir , trust_remote_code = True , device = "cuda:0" )
res = model . generate (
input = f" { model . model_path } /example/en.mp3" ,
cache = {},
language = "zh" , # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn = False ,
batch_size = 64 ,
)Para mais uso, consulte os documentos
Suporta entrada de áudio em qualquer formato, com limite de duração de entrada de 30 segundos ou menos.
from model import SenseVoiceSmall
from funasr . utils . postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
m , kwargs = SenseVoiceSmall . from_pretrained ( model = model_dir , device = "cuda:0" )
m . eval ()
res = m . inference (
data_in = f" { kwargs [ 'model_path' ] } /example/en.mp3" ,
language = "auto" , # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn = False ,
ban_emo_unk = False ,
** kwargs ,
)
text = rich_transcription_postprocess ( res [ 0 ][ 0 ][ "text" ])
print ( text ) # pip3 install -U funasr funasr-onnx
from pathlib import Path
from funasr_onnx import SenseVoiceSmall
from funasr_onnx . utils . postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = SenseVoiceSmall ( model_dir , batch_size = 10 , quantize = True )
# inference
wav_or_scp = [ "{}/.cache/modelscope/hub/{}/example/en.mp3" . format ( Path . home (), model_dir )]
res = model ( wav_or_scp , language = "auto" , use_itn = True )
print ([ rich_transcription_postprocess ( i ) for i in res ])Nota: O modelo ONNX é exportado para o diretório do modelo original.
from pathlib import Path
from funasr_torch import SenseVoiceSmall
from funasr_torch . utils . postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = SenseVoiceSmall ( model_dir , batch_size = 10 , device = "cuda:0" )
wav_or_scp = [ "{}/.cache/modelscope/hub/{}/example/en.mp3" . format ( Path . home (), model_dir )]
res = model ( wav_or_scp , language = "auto" , use_itn = True )
print ([ rich_transcription_postprocess ( i ) for i in res ])Nota: O modelo Libtorch é exportado para o diretório do modelo original.
export SENSEVOICE_DEVICE=cuda:0
fastapi run --port 50000git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./Exemplos de dados
{"key": "YOU0000008470_S0000238_punc_itn", "text_language": "<|en|>", "emo_target": "<|NEUTRAL|>", "event_target": "<|Speech|>", "with_or_wo_itn": "<|withitn|>", "target": "Including legal due diligence, subscription agreement, negotiation.", "source": "/cpfs01/shared/Group-speech/beinian.lzr/data/industrial_data/english_all/audio/YOU0000008470_S0000238.wav", "target_len": 7, "source_len": 140}
{"key": "AUD0000001556_S0007580", "text_language": "<|en|>", "emo_target": "<|NEUTRAL|>", "event_target": "<|Speech|>", "with_or_wo_itn": "<|woitn|>", "target": "there is a tendency to identify the self or take interest in what one has got used to", "source": "/cpfs01/shared/Group-speech/beinian.lzr/data/industrial_data/english_all/audio/AUD0000001556_S0007580.wav", "target_len": 18, "source_len": 360}
Referência completa para data/train_example.jsonl
Descrição:
key : ID exclusivo do arquivo de áudiosource : caminho para o arquivo de áudiosource_len :número de frames fbank do arquivo de áudiotarget : transcriçãotarget_len :comprimento do alvotext_language : id do idioma do arquivo de áudioemo_target :rótulo de emoção do arquivo de áudioevent_target :rótulo do evento do arquivo de áudiowith_or_wo_itn :inclui pontuação e normalização inversa de texto train_text.txt
BAC009S0764W0121 甚至出现交易几乎停滞的情况
BAC009S0916W0489 湖北一公司以员工名义贷款数十员工负债千万
asr_example_cn_en 所有只要处理 data 不管你是做 machine learning 做 deep learning 做 data analytics 做 data science 也好 scientist 也好通通都要都做的基本功啊那 again 先先对有一些>也许对
ID0012W0014 he tried to think how it could be train_wav.scp
BAC009S0764W0121 https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/BAC009S0764W0121.wav
BAC009S0916W0489 https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/BAC009S0916W0489.wav
asr_example_cn_en https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_cn_en.wav
ID0012W0014 https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_en.wav train_text_language.txt
Os IDs de idioma incluem <|zh|> 、 <|en|> 、 <|yue|> 、 <|ja|> e <|ko|> .
BAC009S0764W0121 < | zh | >
BAC009S0916W0489 < | zh | >
asr_example_cn_en < | zh | >
ID0012W0014 < | en | > train_emo.txt
Os rótulos de emoção incluem <|HAPPY|> 、 <|SAD|> 、 <|ANGRY|> 、 <|NEUTRAL|> 、 <|FEARFUL|> 、 <|DISGUSTED|> e <|SURPRISED|> .
BAC009S0764W0121 < | NEUTRAL | >
BAC009S0916W0489 < | NEUTRAL | >
asr_example_cn_en < | NEUTRAL | >
ID0012W0014 < | NEUTRAL | > train_event.txt
Os rótulos de eventos incluem <|BGM|> 、 <|Speech|> 、 <|Applause|> 、 <|Laughter|> 、 <|Cry|> 、 <|Sneeze|> 、 <|Breath|> e <|Cough|> .
BAC009S0764W0121 < | Speech | >
BAC009S0916W0489 < | Speech | >
asr_example_cn_en < | Speech | >
ID0012W0014 < | Speech | > Command
# generate train.jsonl and val.jsonl from wav.scp, text.txt, text_language.txt, emo_target.txt, event_target.txt
sensevoice2jsonl
++scp_file_list= ' ["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt", "../../../data/list/train_text_language.txt", "../../../data/list/train_emo.txt", "../../../data/list/train_event.txt"] '
++data_type_list= ' ["source", "target", "text_language", "emo_target", "event_target"] '
++jsonl_file_out= " ../../../data/list/train.jsonl " Se não houver train_text_language.txt , train_emo_target.txt e train_event_target.txt , o idioma, a emoção e o rótulo do evento serão previstos automaticamente usando o modelo SenseVoice .
# generate train.jsonl and val.jsonl from wav.scp and text.txt
sensevoice2jsonl
++scp_file_list= ' ["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt"] '
++data_type_list= ' ["source", "target"] '
++jsonl_file_out= " ../../../data/list/train.jsonl "
++model_dir= ' iic/SenseVoiceSmall ' Certifique-se de modificar train_tool em finetune.sh para o caminho absoluto de funasr/bin/train_ds.py do diretório de instalação do FunASR que você configurou anteriormente.
bash finetune.shpython webui.py
Se você encontrar problemas de uso, poderá levantar problemas diretamente na página do github.
Você também pode digitalizar o seguinte código QR do grupo DingTalk para ingressar no grupo da comunidade para comunicação e discussão.
| DiversãoASR |
|---|
 |