KAN: Kolmogorov-Arnold Networks é um desafiante promissor para MLPs tradicionais. Estamos entusiasmados com a integração do KAN ao NeRF! O KAN é adequado para tarefas de síntese de visualizações ? Que desafios enfrentaremos? Como iremos enfrentá-los? Fornecemos nossas observações iniciais e discussões futuras!
KANeRF é construído com base em nerfstudio e Efficient-KAN. Consulte o site para obter instruções detalhadas de instalação se encontrar algum problema.
# create python env
conda create --name nerfstudio -y python=3.8
conda activate nerfstudio
python -m pip install --upgrade pip
# install torch
pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
conda install -c " nvidia/label/cuda-11.8.0 " cuda-toolkit
# install tinycudann
pip install ninja git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torch
# install nerfstudio
pip install nerfstudio
# install efficient-kan
pip install git+https://github.com/Blealtan/efficient-kan.gitIntegramos KAN e NeRFacto e comparamos KANeRF com NeRFacto em termos de parâmetros de modelo, tempo de treinamento, desempenho de síntese de nova visualização, etc. no conjunto de dados do Blender. Nas mesmas configurações de rede, o KAN supera ligeiramente o MLP na síntese de novas visualizações, sugerindo que o KAN possui uma capacidade de ajuste mais poderosa. No entanto, a inferência e a velocidade de treinamento do KAN são significativamente** mais lentas do que as do MLP. Além disso, com um número comparável de parâmetros, o KAN apresenta desempenho inferior ao MLP.
| Modelo | NeRFato | NeRFacto minúsculo | KANeRF |
|---|---|---|---|
| Parâmetros de rede treináveis | 8192 | 2176 | 7131 |
| Parâmetros totais de rede | 8192 | 2176 | 10683 |
| oculto_dim | 64 | 8 | 8 |
| cor escura escondida | 64 | 8 | 8 |
| num camadas | 2 | 1 | 1 |
| num camadas de cor | 2 | 1 | 1 |
| geo façanha dim | 15 | 7 | 7 |
| aparência incorporar escurecida | 32 | 8 | 8 |
| Tempo de treinamento | 14m 13s | 13m 47s | 37m 20s |
| FPS | 2,5 | ~2,5 | 0,95 |
| LPIPS | 0,0132 | 0,0186 | 0,0154 |
| PSNR | 33,69 | 32,67 | 33.10 |
| SSIM | 0,973 | 0,962 | 0,966 |
| Perda | 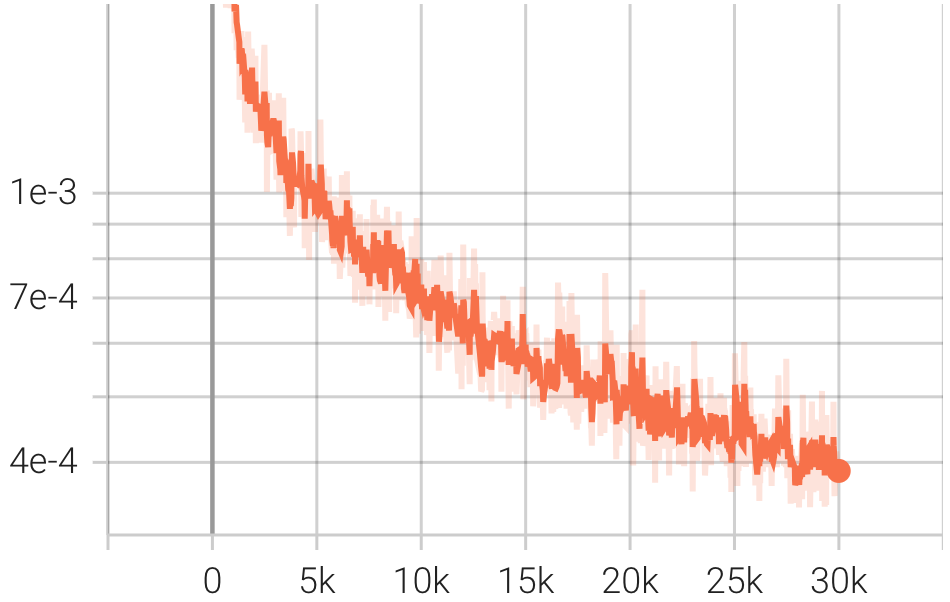 | 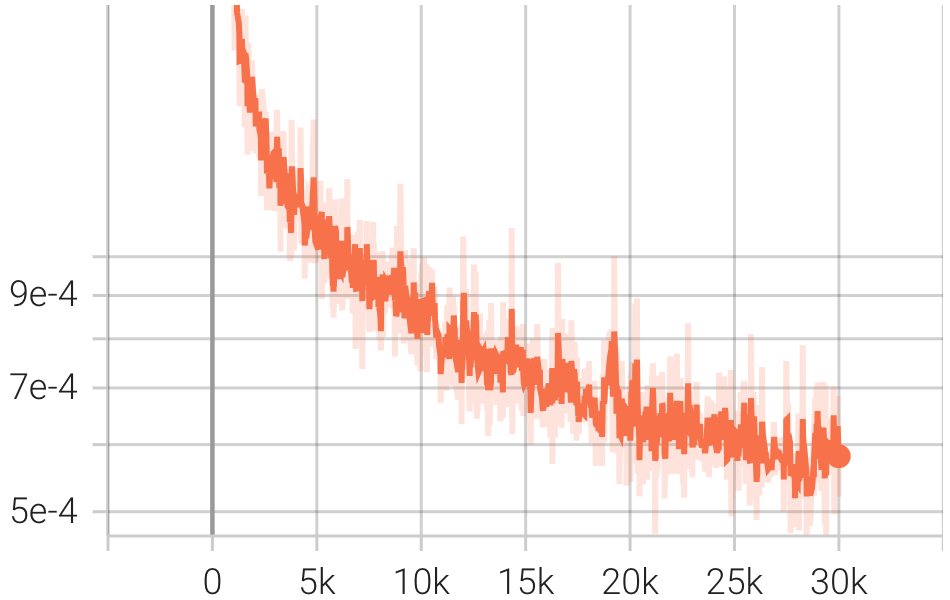 | 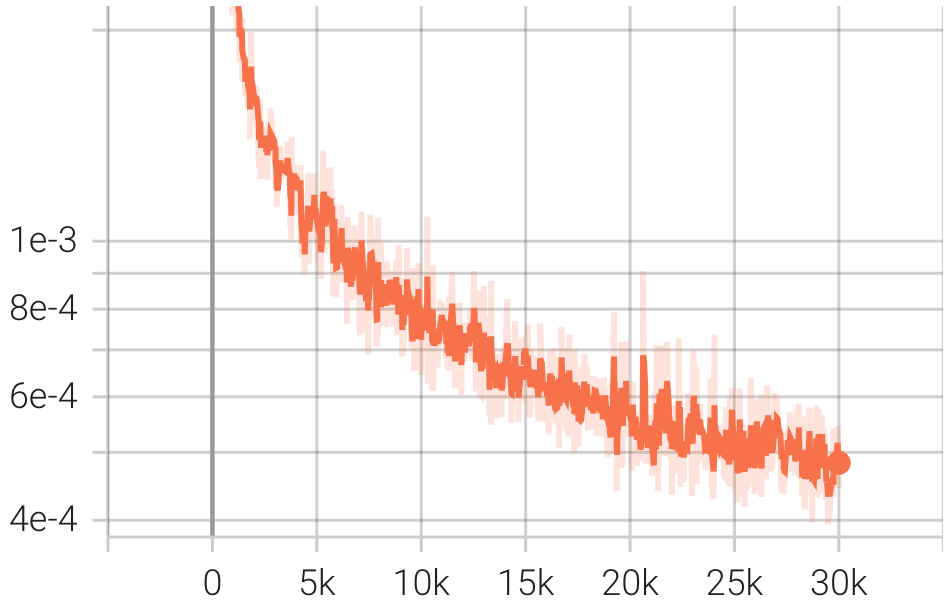 |
| resultado (rgb) | nerfacto_rgb.mp4 | nerfacto_tiny_rgb.mp4 | kanerf_rgb.mp4 |
| resultado (profundidade) | nerfacto_profundidade.mp4 | nerfacto_tiny_profundidade.mp4 | kanerf_profundidade.mp4 |
KAN tem potencial para otimização, principalmente no que diz respeito à aceleração de sua velocidade de inferência. Planejamos desenvolver uma versão do KAN acelerada por CUDA para melhorar ainda mais seu desempenho: D
@Manual {,
title = { Hands-On NeRF with KAN } ,
author = { Delin Qu, Qizhi Chen } ,
year = { 2024 } ,
url = { https://github.com/Tavish9/KANeRF } ,
}

