hailuo free api
0.0.16
Suporta saída de streaming de alta velocidade, múltiplas rodadas de diálogo, síntese de fala, reconhecimento de fala, pesquisa na Internet, interpretação de documentos longos, análise de imagem, implantação de configuração zero, suporte a token multicanal e limpeza automática de rastreamentos de sessão.
Totalmente compatível com interface ChatGPT.
Há também as seguintes oito APIs gratuitas às quais você deve prestar atenção:
Interface Moonshot AI (Kimi.ai) para API kimi-free-api
Interface ZhipuAI (Zhipu Qingyan) para API glm-free-api
Interface StepChat para API step-free-api
Interface Alibaba Tongyi (Qwen) para API qwen-free-api
Interface Metaso AI (Metaso) para API metaso-free-api
Interface iFlytek Spark para API spark-free-api
Interface DeepSeek para API deepseek-free-api
Interface de Listening Intelligence (Emohaa) para API emohaa-free-api
A API reversa é instável. Recomenda-se acessar o MiniMax oficial https://www.minimaxi.com/platform para pagar para usar a API e evitar o risco de ser banido.
Esta organização e indivíduos não aceitam quaisquer doações ou transações financeiras. Este projeto é puramente para pesquisa, intercâmbio e aprendizagem!
É apenas para uso pessoal, sendo proibida a prestação de serviços externos ou uso comercial para evitar pressão sobre o serviço oficial, caso contrário é por sua conta e risco!
É apenas para uso pessoal, sendo proibida a prestação de serviços externos ou uso comercial para evitar pressão sobre o serviço oficial, caso contrário é por sua conta e risco!
É apenas para uso pessoal, sendo proibida a prestação de serviços externos ou uso comercial para evitar pressão sobre o serviço oficial, caso contrário é por sua conta e risco!
Este link é apenas uma função de teste temporária, com apenas uma simultaneidade. Se você encontrar uma exceção, tente novamente mais tarde. É recomendável implantá-lo você mesmo.
https://udify.app/chat/uqBly3aW1LTwzzb3

A síntese de fala está criando fala
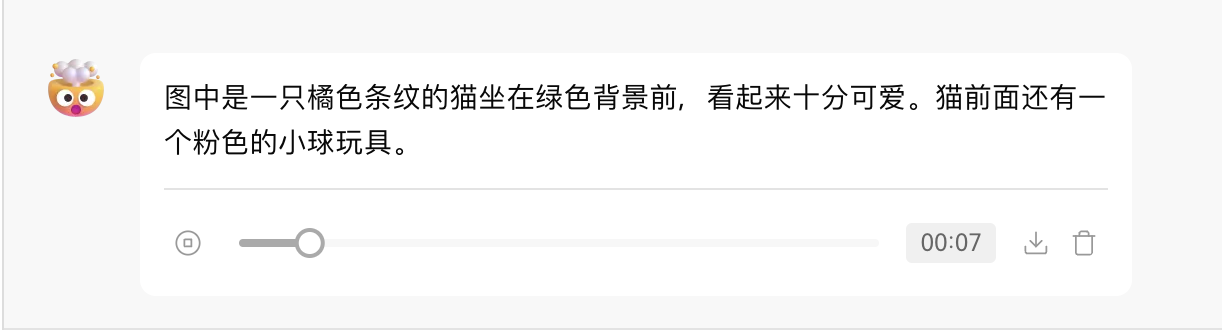
O reconhecimento de fala envolve a criação de transcrições




Obtenha token da Conch AI
Entre no Conch AI para iniciar uma conversa, em seguida, abra as ferramentas do desenvolvedor com F12 e encontre o valor de _token em Aplicativo> LocalStorage. Isso será usado como o valor do Bearer Token de Autorização: Authorization: Bearer TOKEN
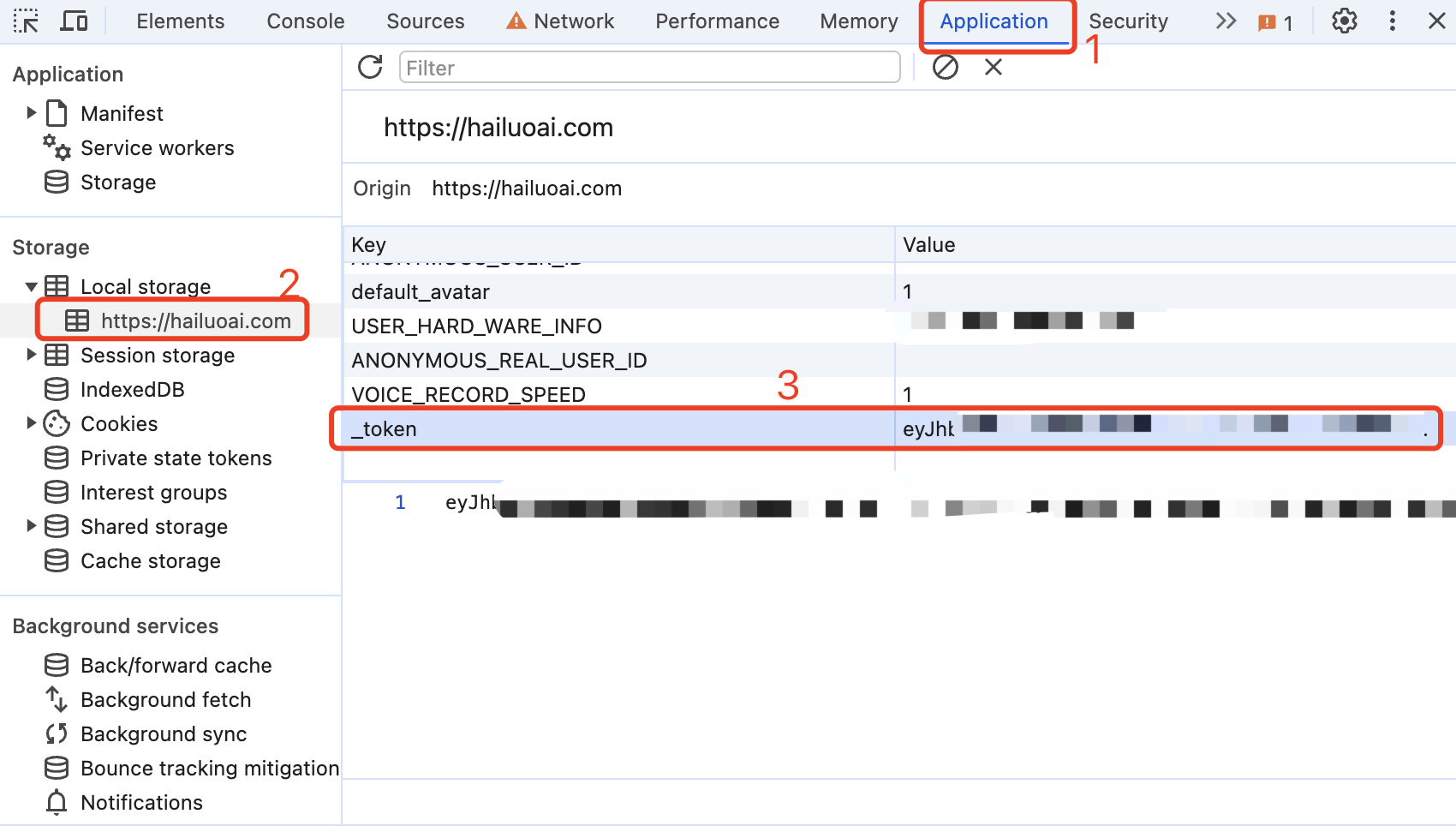
Atualmente, parece que a mesma conta só pode ter uma saída ao mesmo tempo. Você pode fornecer _tokens de várias contas e usá-los , o splicing fornece:
Authorization: Bearer TOKEN1,TOKEN2,TOKEN3
Um deles será selecionado cada vez que o serviço for solicitado.
Prepare um servidor com IP público e porta aberta 8000.
Extraia a imagem e inicie o serviço
docker run -it -d --init --name hailuo-free-api -p 8000:8000 -e TZ=Asia/Shanghai vinlic/hailuo-free-api:latestVisualize logs de serviço em tempo real
docker logs -f hailuo-free-apiReiniciar serviço
docker restart hailuo-free-apiInterromper serviço
docker stop hailuo-free-api version : ' 3 '
services :
hailuo-free-api :
container_name : hailuo-free-api
image : vinlic/hailuo-free-api:latest
restart : always
ports :
- " 8000:8000 "
environment :
- TZ=Asia/ShanghaiNota: Algumas áreas de implantação podem não conseguir se conectar ao Hailuo. Se o log do contêiner mostrar um tempo limite de solicitação ou não puder ser conectado, mude para outras áreas para implantação! Nota: A instância do contêiner da conta gratuita irá parar automaticamente de funcionar após um período de inatividade, o que causará um atraso de 50 segundos ou mais na próxima solicitação. É recomendado marcar Render container keep alive.
Bifurque este projeto para sua conta do github.
Visite Render e faça login em sua conta do github.
Crie seu serviço Web (Novo+ -> Construa e implante a partir de um repositório Git -> Conecte seu projeto bifurcado -> Selecione a área de implantação -> Selecione o tipo de instância como Gratuito -> Criar serviço Web).
Depois de aguardar a conclusão da construção, copie o nome de domínio atribuído e divida o URL para acesso.
Nota: O tempo limite de resposta da solicitação para contas gratuitas Vercel é de 10 segundos, mas a resposta da interface geralmente leva mais tempo e você pode encontrar um erro de tempo limite 504 retornado pelo Vercel!
Certifique-se de ter instalado o ambiente Node.js primeiro.
npm i -g vercel --registry http://registry.npmmirror.com
vercel login
git clone https://github.com/LLM-Red-Team/hailuo-free-api
cd hailuo-free-api
vercel --prodPrepare um servidor com IP público e porta aberta 8000.
Instale o ambiente Node.js e configure as variáveis de ambiente primeiro e confirme se o comando node está disponível.
Instalar dependências
npm iInstale PM2 para proteção de processo
npm i -g pm2Compile e construa. Quando você vir o diretório dist, a compilação estará concluída.
npm run buildIniciar serviço
pm2 start dist/index.js --name " hailuo-free-api "Visualize logs de serviço em tempo real
pm2 logs hailuo-free-apiReiniciar serviço
pm2 reload hailuo-free-apiInterromper serviço
pm2 stop hailuo-free-apiÉ mais rápido e fácil usar o seguinte cliente de desenvolvimento secundário para acessar os projetos da série free-api e suporta upload de documentos/imagens!
LobeChat desenvolvido por Clivia https://github.com/Yanyutin753/lobe-chat
ChatGPT Web https://github.com/SuYxh/chatgpt-web-sea desenvolvido por Guangguang@
Atualmente, a interface /v1/chat/completions compatível com openai é suportada. Você pode usar a interface de acesso do cliente compatível com openai ou outros clientes, ou usar serviços online como dify para acessá-la.
Interface de conclusão de conversa, compatível com chat-completions-api do openai.
POST /v1/chat/completions
header precisa definir o cabeçalho de autorização:
Authorization: Bearer [_token]
Dados da solicitação:
{
// model模型名称可以乱填
"model" : " hailuo " ,
"messages" : [
{
"role" : " user " ,
"content" : "你是谁? "
}
],
// 如果使用SSE流请设置为true,默认false
"stream" : false
}Dados de resposta:
{
"id" : " 242830597915504644 " ,
"model" : " hailuo " ,
"object" : " chat.completion " ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : " assistant " ,
"content" : "我是海螺AI,由上海稀宇科技有限公司(MiniMax)自主研发的AI助理。我可以帮助你回答各种问题,提供信息查询、生活建议、学习辅导等服务。如果你有任何问题,随时可以向我提问。 "
},
"finish_reason" : " stop "
}
],
"usage" : {
"prompt_tokens" : 1 ,
"completion_tokens" : 1 ,
"total_tokens" : 2
},
"created" : 1714751470
}Crie uma interface de voz, compatível com a API audio-create-speech-api da openai e suporte apenas saída no formato mp3.
male-botong 思远 [兼容 tts-1 alloy]
Podcast_girl 心悦 [兼容 tts-1 echo]
boyan_new_hailuo 子轩 [兼容 tts-1 fable]
female-shaonv 灵儿 [兼容 tts-1 onyx]
YaeMiko_hailuo 语嫣 [兼容 tts-1 nova]
xiaoyi_mix_hailuo 少泽 [兼容 tts-1 shimmer]
xiaomo_sft 芷溪 [兼容 tts-1-hd alloy]
cove_test2_hailuo 浩翔(英文)
scarlett_hailuo 雅涵(英文)
Leishen2_hailuo 模仿雷电将军 [兼容 tts-1-hd echo]
Zhongli_hailuo 模仿钟离 [兼容 tts-1-hd fable]
Paimeng_hailuo 模仿派蒙 [兼容 tts-1-hd onyx]
keli_hailuo 模仿可莉 [兼容 tts-1-hd nova]
Hutao_hailuo 模仿胡桃 [兼容 tts-1-hd shimmer]
Xionger_hailuo 模仿熊二
Haimian_hailuo 模仿海绵宝宝
Robot_hunter_hailuo 模仿变形金刚
Linzhiling_hailuo 小玲玲
huafei_hailuo 拽妃
lingfeng_hailuo 东北er
male_dongbei_hailuo 老铁
Beijing_hailuo 北京er
JayChou_hailuo JayJay
Daniel_hailuo 潇然
Bingjiao_zongcai_hailuo 沉韵
female-yaoyao-hd 瑶瑶
murong_sft 晨曦
shangshen_sft 沐珊
kongchen_sft 祁辰
shenteng2_hailuo 夏洛特
Guodegang_hailuo 郭嘚嘚
yueyue_hailuo 小月月
Encontre o próprio ID de voz do clone data.formInfo.userVoiceList da resposta da solicitação robot_custom_config da Rede F12, no formato de puv_****************** .
Configure a variável de ambiente REPLACE_AUDIO_MODEL na inicialização do docker ou no sistema para mapear alto , falantes personalizados para o modelo de alto-falante do openai.
A ordem do mapeamento é: liga, eco, fábula, ônix, nova, brilho Atualmente, 6 mapeamentos podem ser definidos.
Exemplo de mapeamento:
Podcast_girl -> liga
yueyue_hailuo -> eco
keli_hailuo -> fábula
A configuração do ambiente para o relacionamento de mapeamento acima é a seguinte:
REPLACE_AUDIO_MODEL="Podcast_girl,yueyue_hailuo,keli_hailuo";
POST /v1/áudio/fala
header precisa definir o cabeçalho de autorização:
Authorization: Bearer [_token]
Dados da solicitação:
{
// model模型名称可以乱填
"model" : " hailuo " ,
// 语音内容,尽量不要包含指令(否则可能导致模型回答你的问题)
"input" : "你在做什么? " ,
// 发音人ID,可以使用官方或者自己克隆的音色
"voice" : " Podcast_girl "
}Dados de resposta:
fluxo de dados binários de áudio/mpeg (arquivo mp3)
Crie uma interface de transcrição, compatível com a API de criação de transcrição de áudio da openai.
POST /v1/áudio/transcrições
header precisa definir o cabeçalho de autorização:
Authorization: Bearer [_token]
Dados de solicitação (multipart/form-data):
file 要转录的音频文件对象(不是文件名),格式为:wav、mp3、mpeg、mpga、m4a、ogg、flac。
model 模型名称,可以乱填
response_format 仅支持json或text
Dados de resposta:
{
"text": "嗯,多年前呢我是个穷小子,我有一个喜欢的女孩,他有一双会说话的眼睛,他偏爱雏菊般的淡黄色。我我每天都骑自行车送他上下学专挑那个坑坑洼洼的路走。然后编的时候,我就能感觉到他用双手在后边用力的拽我的衣服,我好开心哪。然后回家以后,我才发现我唯一的一件衬衣变成了燕尾服。我每天中午会把我妈妈给我带的荷包蛋,我给她吃,他只吃蛋白,他把蛋蛋黄留给我,我我真的我好感动啊。呃,到后来我我知道呃,吃蛋黄反腹唇口,呃,我们同窗三年,我给他写了一百多封信,跟你联系我我我我我我每一封信我都换一个笔记,我怕他认出来,我那我很不好意思。所以说长此以往的练习,我在书法大赛获得了一等奖。直到有一天,他准备坐火车去省城上学的时候,我也没有把我自己的话跟他说出来。哎,我去那天也是像今天一样下着雨,他也带着那条漂亮的黄丝巾,我递给他一篮子鸡蛋,他没接,他反问我说有多少个鸡蛋,我说有一百个,他说他一天吃一个,一百天就吃完了再想吃,还有吗?这个其实我知道他懂我那句话,可是我当时就像被雷击中了一样无果果主人我什么话我都说不出来。当我缓过神儿来的时候,他已经上车了,车已经开了,车已经开出一段距离了。那个时候我只要大声的喊,他一定能够听到我张嘴了,没声儿。从那一刻起,我就生了病,预言是癌症,没当下雨或者是重要场合,我者无法说话。其实这么多年我一直想找一个机会,我希望他能够重新出现在我眼前。今天这个机会来了,此时此刻他就坐在离我三米半远的地方。我要把我二十年前要跟你说的话,大声的告诉你,哇,李丽,你你只要愿意跟我在一起鸡蛋,我给你带一辈子,有的是。"
}Forneça um URL de arquivo acessível ou BASE64_URL para analisar.
POST /v1/chat/completions
header precisa definir o cabeçalho de autorização:
Authorization: Bearer [_token]
Dados da solicitação:
{
// model模型名称可以乱填
"model" : " hailuo " ,
"messages" : [
{
"role" : " user " ,
"content" : [
{
"type" : " file " ,
"file_url" : {
"url" : " https://mj101-1317487292.cos.ap-shanghai.myqcloud.com/ai/test.pdf "
}
},
{
"type" : " text " ,
"text" : "文档里说了什么? "
}
]
}
],
// 如果使用SSE流请设置为true,默认false
"stream" : false
}Dados de resposta:
{
"id" : " 242835041910616068 " ,
"model" : " hailuo " ,
"object" : " chat.completion " ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : " assistant " ,
"content": "文档中包含了一系列的古代魔法仪式和咒语,这些内容似乎源自古希腊罗马时期的魔法文献,如《希腊魔法纸莎草纸》(PGM,全称为Papyri Graecae Magicae)。以下是每个文档内容的简要概述:nn1. 文档1中描述了一个仪式,其中包括将面包分成七小块,然后在那些被暴力杀害的地方留下这些面包块,并念诵一段咒语。这个仪式的目的是为了吸引一个特定女性的注意,让她对施法者产生强烈的感情和欲望。nn2. 文档2中包含了一个咒语,要求一个名为Didymos的施法者召唤一个名为Tereous的女性,通过念诵一系列的魔法名字和咒语,使她感到痛苦和渴望,直到她来到施法者身边。nn3. 文档3中提供了一个简单的仪式,施法者需要保持三天的纯洁,并献上乳香作为祭品,念诵一个特定的名字(NEPHERIRI),以此来吸引一个美丽的女性。nn4. 文档4中描述了一个使用没药的仪式,施法者在献上没药的同时念诵一段咒语,目的是让一个特定的女性对施法者产生强烈的爱慕之情,即使她正在做其他事情,也会被这种强烈的感情所占据。nn这些文档内容反映了古代人们对于魔法和咒语的信仰,以及他们试图通过这些仪式来影响他人情感和行为的愿望。需要注意的是,这些内容仅供学术研究和了解历史之用,现代社会中不应使用这些仪式或咒语来干预他人的自由意志。"
},
"finish_reason" : " stop "
}
],
"usage" : {
"prompt_tokens" : 1 ,
"completion_tokens" : 1 ,
"total_tokens" : 2
},
"created" : 1714752530
}Forneça um URL de imagem acessível ou BASE64_URL para analisar.
Este formato é compatível com o formato API gpt-4-vision-preview e você também pode usar esse formato para transmitir documentos para análise.
POST /v1/chat/completions
header precisa definir o cabeçalho de autorização:
Authorization: Bearer [_token]
Dados da solicitação:
{
"model" : " hailuo " ,
"messages" : [
{
"role" : " user " ,
"content" : [
{
"type" : " image_url " ,
"image_url" : {
"url" : " https://ecmb.bdimg.com/tam-ogel/-1384175475_-1668929744_259_194.jpg "
}
},
{
"type" : " text " ,
"text" : "图里是什么? "
}
]
}
],
// 如果使用SSE流请设置为true,默认false
"stream" : false
}Dados de resposta:
{
"id" : " 242835404705341445 " ,
"model" : " hailuo " ,
"object" : " chat.completion " ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : " assistant " ,
"content" : "图里是“海螺AI”的标识。 "
},
"finish_reason" : " stop "
}
],
"usage" : {
"prompt_tokens" : 1 ,
"completion_tokens" : 1 ,
"total_tokens" : 2
},
"created" : 1714752616
}Verifique se _token está ativo. Se live não for verdadeiro, caso contrário, é falso. Por favor, não chame esta interface com frequência (menos de 10 minutos).
POST /token/cheque
Dados da solicitação:
{
"token" : " eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9... "
}Dados de resposta:
{
"live" : true
}Se você estiver usando o proxy reverso Nginx hailuo-free-api, adicione os seguintes itens de configuração para otimizar o efeito de saída do fluxo e otimizar a experiência.
# 关闭代理缓冲。当设置为off时,Nginx会立即将客户端请求发送到后端服务器,并立即将从后端服务器接收到的响应发送回客户端。
proxy_buffering off ;
# 启用分块传输编码。分块传输编码允许服务器为动态生成的内容分块发送数据,而不需要预先知道内容的大小。
chunked_transfer_encoding on ;
# 开启TCP_NOPUSH,这告诉Nginx在数据包发送到客户端之前,尽可能地发送数据。这通常在sendfile使用时配合使用,可以提高网络效率。
tcp_nopush on ;
# 开启TCP_NODELAY,这告诉Nginx不延迟发送数据,立即发送小数据包。在某些情况下,这可以减少网络的延迟。
tcp_nodelay on ;
# 设置保持连接的超时时间,这里设置为120秒。如果在这段时间内,客户端和服务器之间没有进一步的通信,连接将被关闭。
keepalive_timeout 120 ;Como o lado da inferência não está em hailuo-free-api, o token não pode ser contado e será retornado como um número fixo.


