Página do Projeto | Papel | Modelo de cartão?
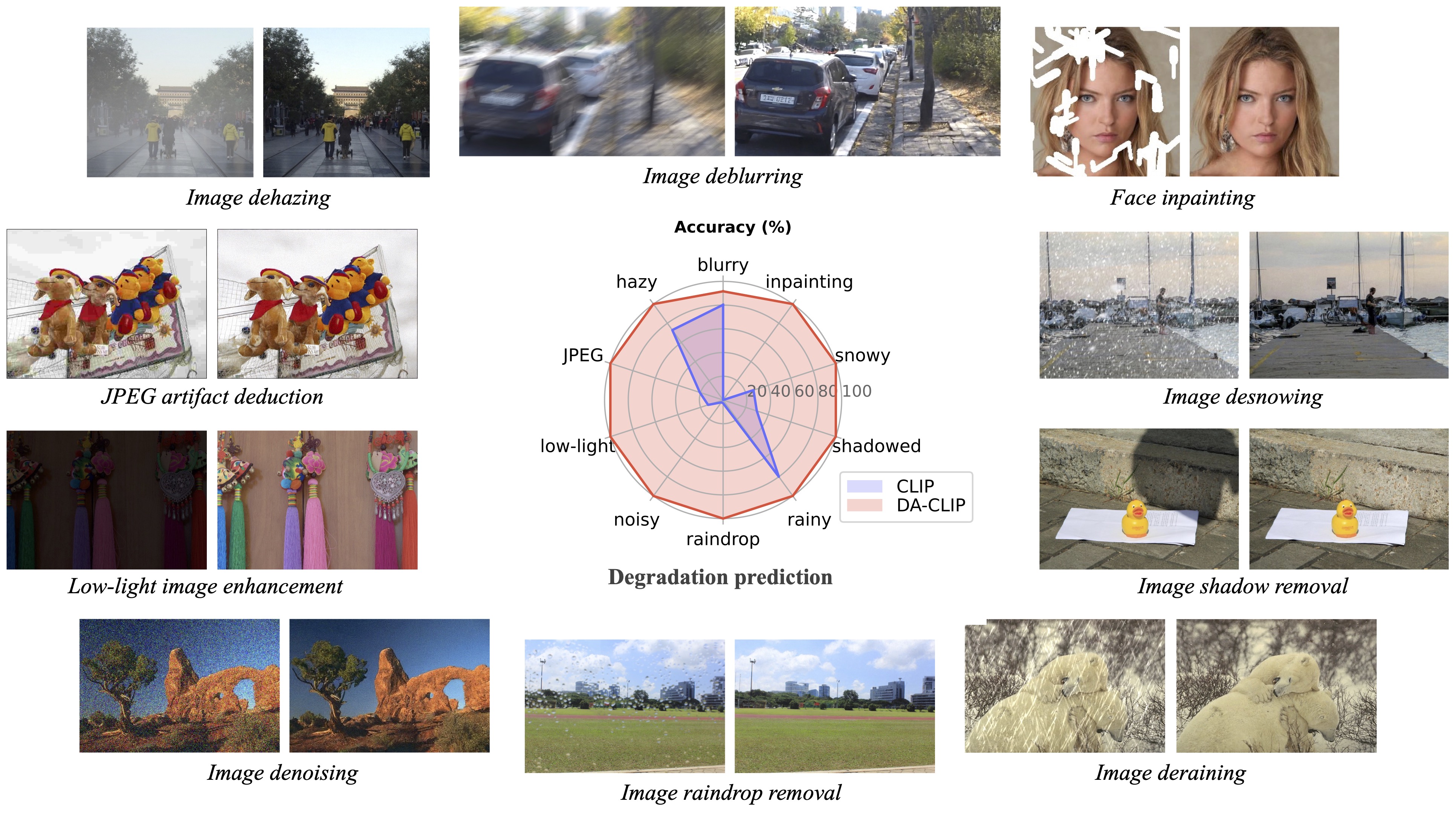
Nosso trabalho de acompanhamento, Restauração de imagem foto-realística na natureza com modelos de linguagem de visão controlada (CVPRW 2024) apresenta uma amostragem posterior para melhor geração de imagem e lida com imagens de degradação mista do mundo real semelhantes ao Real-ESRGAN.
[ 2024.04.16 ] Nosso artigo de acompanhamento "Restauração de imagens fotorrealísticas na natureza com modelos de linguagem de visão controlada" já está no ArXiv!
[ 2024.04.15 ] Atualizado um modelo IR selvagem para degradações do mundo real e amostragem posterior para melhor geração de imagens. Os pesos pré-treinados wild-ir.pth e wild-daclip_ViT-L-14.pt também são fornecidos para wild-ir.
[ 2024.01.20 ] ??? Nosso artigo DA-CLIP foi aceito pelo ICLR 2024 ??? Fornecemos ainda um modelo mais robusto no cartão de modelo.
[ 2023.10.25 ] Adicionados links de conjuntos de dados para treinamento e teste.
[ 2023.10.13 ] Adicionadas a demonstração e a API Replicate. Obrigado a @chenxwh!!! Atualizamos a demonstração Hugging Face e a demonstração online do Colab. Obrigado @fffiloni e @camenduru !!! Também fizemos um Cartão Modelo em Hugging Face ? e forneceu mais exemplos para teste.
[ 2023.10.09 ] Os pesos pré-treinados do DA-CLIP e do modelo Universal IR são liberados no link1 e link2, respectivamente. Além disso, também fornecemos um arquivo do aplicativo Gradio para o caso de você desejar testar suas próprias imagens.
SO: Ubuntu 20.04
nvidia:
cuda: 11,4
píton 3.8
Aconselhamos você primeiro a criar um ambiente virtual com:
python3 -m venv .envsource .env/bin/ativar pip instalar -U pip pip instalar -r requisitos.txt
Entre no diretório universal-image-restoration e execute:
importar tocha do PIL importar Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32 ')imagem = pré-processo(Image.open("haze_01.png")).unsqueeze(0)degradações = ['motion-blurry','hazy','jpeg-compressed','pouca luz','barulhento','gota de chuva' ,'chuvoso','sombreado','nevado','incompleto']text = tokenizer(degradações)com torch.no_grad(), torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, keepdim=True)text_features / = text_features.norm(dim=-1, keepdim=True)text_probs= (100,0 * degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])print(f"Tarefa: {nome_da_tarefa}: {degradações[índice]} - {text_probs[0] [índice]}")Preparando os conjuntos de dados de treinamento e teste seguindo nossa seção de construção de conjuntos de dados em papel como:
#### para conjunto de dados de treinamento ######## (incompleto significa pintura interna) ####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--hazy|--jpeg-compressed|--pouca luz|--ruidoso|--gota de chuva|--chuvoso|--sombreado|--nevado|--incompleto## ## para testar o conjunto de dados ######## (a mesma estrutura do trem) ####datasets/universal/val ...#### para legendas limpas ####datasets/universal/daclip_train.csv conjuntos de dados/universal/daclip_val.csv
Em seguida, entre no diretório universal-image-restoration/config/daclip-sde e modifique os caminhos do conjunto de dados nos arquivos de opções em options/train.yml e options/test.yml .
Você pode adicionar mais tarefas ou conjuntos de dados aos diretórios train e val e adicionar a palavra de degradação à distortion .
| Degradação | desfocado | nebuloso | compactado em jpeg* | pouca luz | barulhento* (igual ao jpeg) |
|---|---|---|---|---|---|
| Conjuntos de dados | GoPro | RESIDE-6k | DIV2K+Flickr2K | LOL | DIV2K+Flickr2K |
| Degradação | gota de chuva | chuvoso | sombreado | nevado | incompleto |
|---|---|---|---|---|---|
| Conjuntos de dados | Gota de chuva | Rain100H: treinar, testar | SRD | Neve100K | CelebaHQ-256 |
Você só deve extrair os conjuntos de dados de treinamento para treinamento , e todos os conjuntos de dados de validação podem ser baixados no Google Drive. Para conjuntos de dados jpeg e barulhentos, você pode gerar imagens LQ usando este script.
Consulte DA-CLIP.md para obter detalhes.
O código principal para treinamento está em universal-image-restoration/config/daclip-sde e a rede principal para DA-CLIP está em universal-image-restoration/open_clip/daclip_model.py .
Coloque os pesos DA-CLIP pré-treinados no diretório pretrained e verifique o caminho daclip .
Você pode então treinar o modelo seguindo os scripts bash abaixo:
cd universal-image-restoration/config/daclip-sde# Para GPU única:python3 train.py -opt=options/train.yml# Para treinamento distribuído, é necessário alterar os gpu_ids na opção filepython3 -m torch.distributed.launch - -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorch
Os modelos e logs de treinamento serão salvos em log/universal-ir . Você pode imprimir seu log a qualquer momento executando tail -f log/universal-ir/train_universal-ir_***.log -n 100 .
As mesmas etapas de treinamento podem ser usadas para restauração de imagens em estado selvagem (wild-ir).
| Nome do modelo | Descrição | Google Drive | Abraçando o rosto |
|---|---|---|---|
| DA-CLIP | Modelo CLIP com reconhecimento de degradação | download | download |
| Universal-IR | Modelo de restauração de imagem universal baseado em DA-CLIP | download | download |
| DA-CLIP-mix | Modelo CLIP com reconhecimento de degradação (adicionar desfoque gaussiano + pintura facial e desfoque gaussiano + chuvoso) | download | download |
| Mistura IR universal | Modelo de restauração de imagem universal baseado em DA-CLIP (adiciona treinamento robusto e degradações mistas) | download | download |
| Selvagem-DA-CLIP | Modelo CLIP com reconhecimento de degradação em estado selvagem (ViT-L-14) | download | download |
| Selvagem-IR | Modelo de restauração de imagem baseado em DA-CLIP em estado selvagem | download | download |
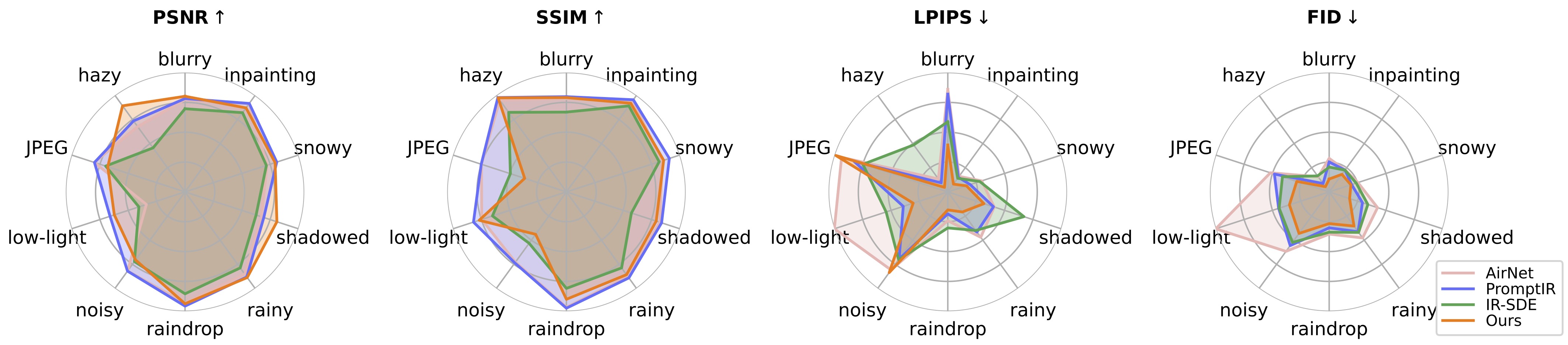
Para avaliar nosso método de restauração de imagem, modifique o caminho do benchmark e o caminho do modelo e execute
cd restauração de imagem universal/config/universal-ir python test.py -opt = opções/test.yml
Aqui fornecemos um arquivo app.py para testar suas próprias imagens. Antes disso, você precisa baixar os pesos pré-treinados (DA-CLIP e UIR) e modificar o caminho do modelo em options/test.yml . Então, simplesmente executando python app.py , você pode abrir http://localhost:7860 para testar o modelo. (Também fornecemos várias imagens com diferentes degradações no diretório images ). Também fornecemos mais exemplos de nosso conjunto de dados de teste no Google Drive.
As mesmas etapas podem ser usadas para restauração de imagens em estado selvagem (wild-ir).



? Nos testes, descobrimos que o modelo pré-treinado atual ainda é difícil de processar algumas imagens do mundo real que podem ter mudanças de distribuição com nosso conjunto de dados de treinamento (capturados de diferentes dispositivos ou com diferentes resoluções ou degradações). Consideramos isso como um trabalho futuro e tentaremos tornar nosso modelo mais prático! Também incentivamos os usuários interessados em nosso trabalho a treinar seus próprios modelos com conjuntos de dados maiores e mais tipos de degradação.
? Aliás, também descobrimos que o redimensionamento direto das imagens de entrada resultará em um desempenho ruim para a maioria das tarefas . Poderíamos tentar adicionar a etapa de redimensionamento ao treinamento, mas isso sempre destrói a qualidade da imagem devido à interpolação.
? Para a tarefa de pintura interna, nosso modelo atual suporta apenas pintura facial devido à limitação do conjunto de dados. Fornecemos nossos exemplos de máscaras e você pode usar o script generate_masked_face para gerar faces incompletas.
Reconhecimento: Nosso DA-CLIP é baseado em IR-SDE e open_clip. Obrigado pelo código deles!
Se você tiver alguma dúvida, entre em contato: [email protected]
Se nosso código ajudar sua pesquisa ou trabalho, considere citar nosso artigo. A seguir estão as referências do BibTeX:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

