
Xuan Ju 1* , Yiming Gao 1* , Zhaoyang Zhang 1*# , Ziyang Yuan 1 , Xintao Wang 1 , Ailing Zeng, Yu Xiong, Qiang Xu, Ying Shan 1
1 ARC Lab, Tencent PCG 2 Universidade Chinesa de Hong Kong * Contribuição Igualitária # Líder do Projeto
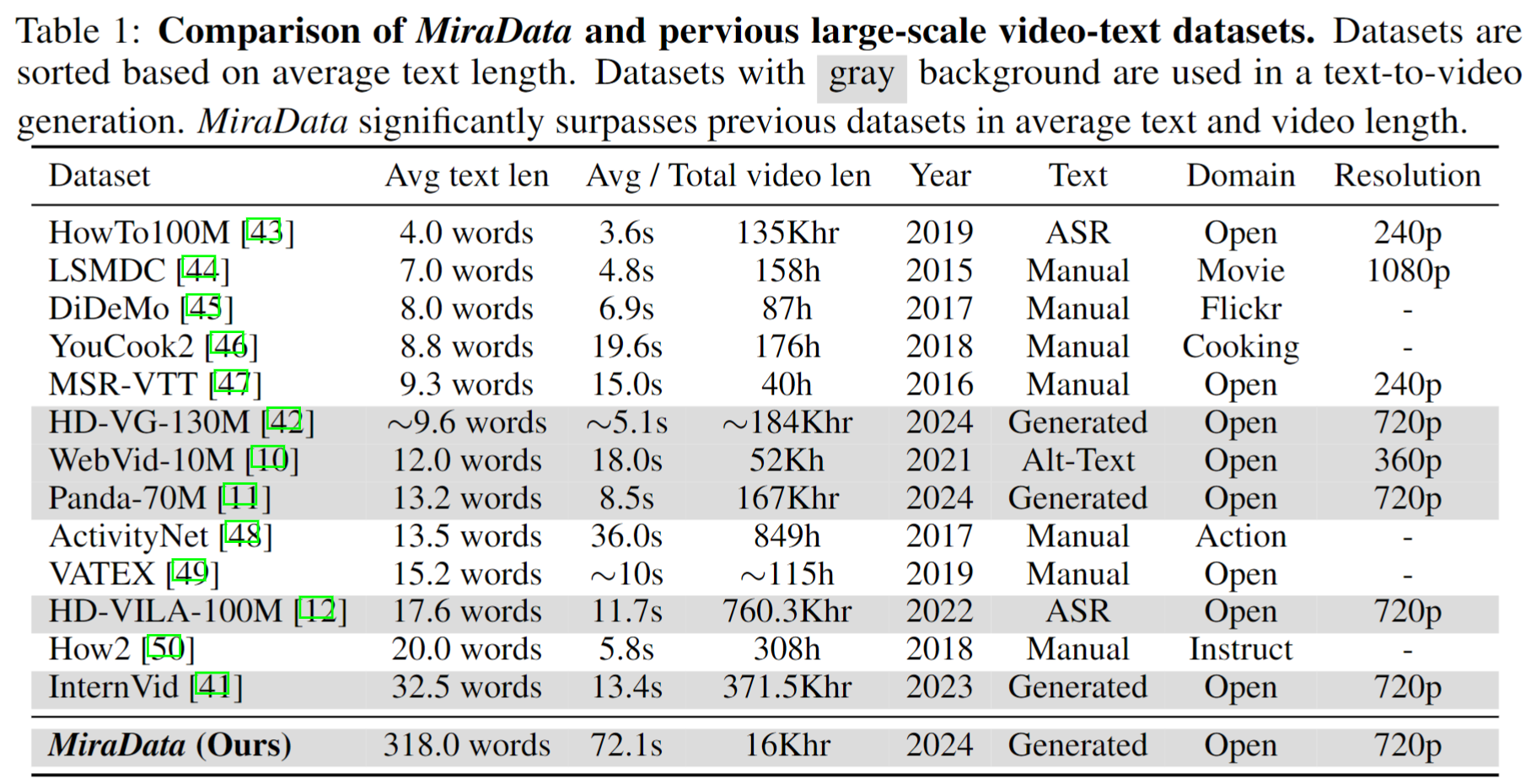
Os conjuntos de dados de vídeo desempenham um papel crucial na geração de vídeo, como o Sora. No entanto, os conjuntos de dados de texto-vídeo existentes muitas vezes são insuficientes quando se trata de lidar com longas sequências de vídeo e capturar transições de tomadas . Para resolver essas limitações, apresentamos o MiraData , um conjunto de dados de vídeo projetado especificamente para tarefas longas de geração de vídeo. Além disso, para avaliar melhor a consistência temporal e a intensidade do movimento na geração de vídeo, apresentamos o MiraBench , que aprimora os benchmarks existentes adicionando consistência 3D e métricas de força de movimento baseadas em rastreamento. Você pode encontrar mais detalhes em nosso artigo de pesquisa.
Lançamos quatro versões do MiraData, contendo dados de 330K, 93K, 42K, 9K.
O meta-arquivo para esta versão do MiraData é fornecido no Google Drive e no HuggingFace Dataset. Além disso, para uma melhor e mais rápida compreensão da composição do nosso meta-arquivo, amostramos aleatoriamente um conjunto de 100 videoclipes, que podem ser acessados aqui. O meta-arquivo contém as seguintes informações de índice:
{download_id}.{clip_id}Para baixar os vídeos e dividi-los em clipes, comece baixando os meta-arquivos do Google Drive ou do HuggingFace Dataset. Depois de obter os meta-arquivos, você pode usar os seguintes scripts para baixar as amostras de vídeo:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
Removeremos as amostras de vídeo de nosso conjunto de dados/Github/página do projeto enquanto você precisar. Entre em contato conosco para a solicitação.
Para coletar o MiraData, primeiro selecionamos manualmente canais do YouTube em diferentes cenários e incluímos vídeos de HD-VILA-100M, Videovo, Pixabay e Pexels. Em seguida, todos os vídeos nos canais correspondentes são baixados e divididos usando PySceneDetect. Em seguida, usamos vários modelos para unir os clipes curtos e filtrar vídeos de baixa qualidade. Em seguida, selecionamos videoclipes de longa duração. Por fim, legendamos todos os videoclipes usando GPT-4V.

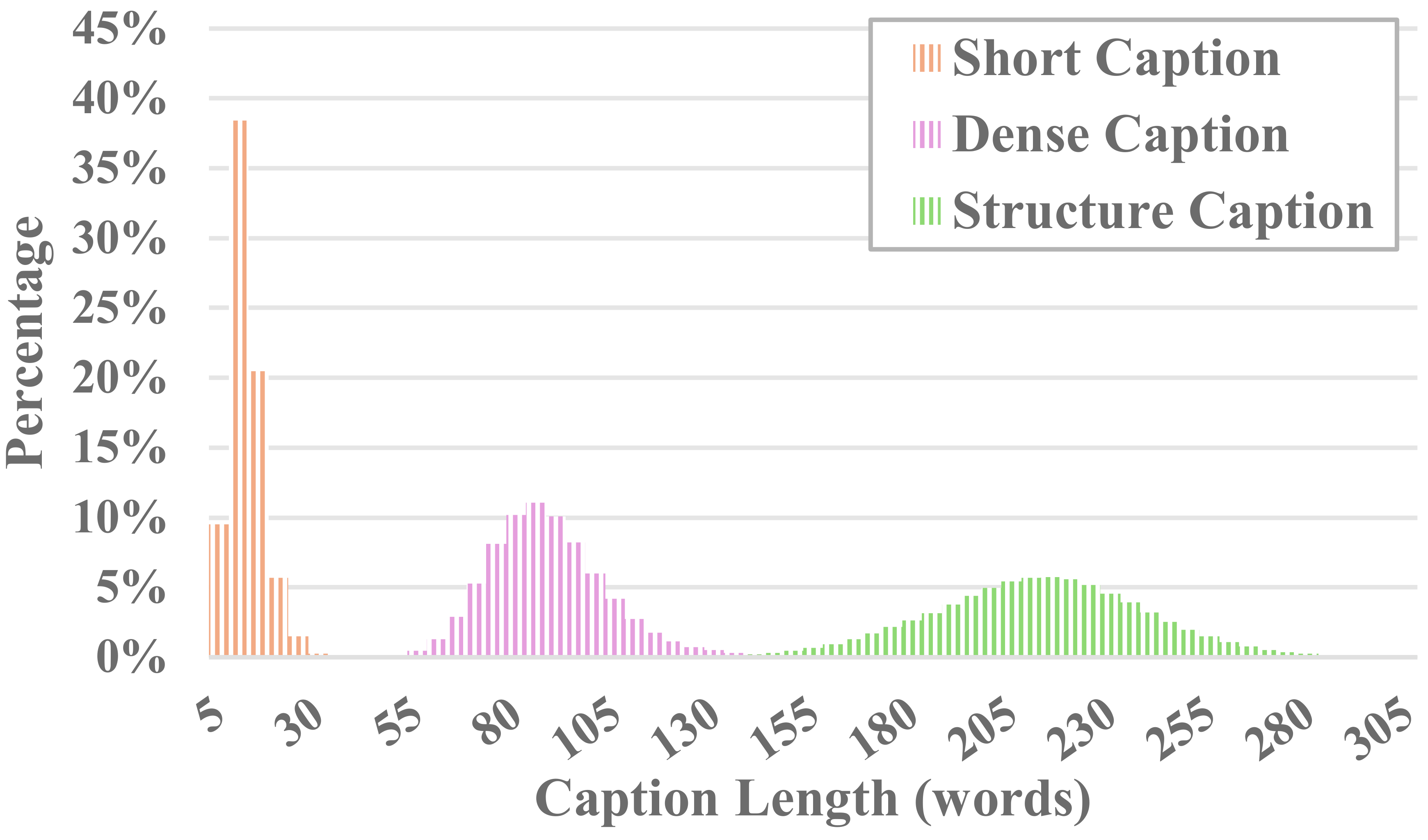
Cada vídeo no MiraData é acompanhado por legendas estruturadas. Essas legendas fornecem descrições detalhadas de diversas perspectivas, aumentando a riqueza do conjunto de dados.
Seis tipos de legendas
Testamos os métodos LLM visuais de código aberto existentes e o GPT-4V e descobrimos que as legendas do GPT-4V mostram melhor precisão e coerência na compreensão semântica em termos de sequência temporal.
Para equilibrar os custos de anotação e a precisão da legenda, amostramos uniformemente 8 quadros para cada vídeo e os organizamos em uma grade 2x4 de uma imagem grande. Em seguida, usamos o modelo de legenda do Panda-70M para anotar cada vídeo com uma legenda de uma frase, que serve como uma dica para o conteúdo principal, e inseri-la em nosso prompt ajustado. Ao alimentar o prompt ajustado e uma imagem grande 2x4 para GPT-4V, podemos gerar legendas com eficiência para múltiplas dimensões em apenas uma rodada de conversa. O conteúdo específico do prompt pode ser encontrado em caption_gpt4v.py, e convidamos todos a contribuir com dados de texto e vídeo de mais alta qualidade. ?

Para avaliar a geração de vídeos longos, projetamos 17 métricas de avaliação no MiraBench a partir de 6 perspectivas, incluindo consistência temporal, força de movimento temporal, consistência 3D, qualidade visual, alinhamento texto-vídeo e consistência de distribuição. Essas métricas abrangem a maioria dos padrões de avaliação comuns usados em modelos de geração de vídeo anteriores e benchmarks de texto para vídeo.
Para avaliar os vídeos gerados, primeiro configure o ambiente python por meio de:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
Em seguida, execute a avaliação por meio de:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
Você pode seguir o exemplo em data/evaluation_example para avaliar seus próprios vídeos gerados.
Consulte LICENÇA.
Se você achar este projeto útil para sua pesquisa, cite nosso artigo. ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
Para qualquer dúvida, envie um e-mail para [email protected] .
MiraData está sob a licença GPL-v3 e é compatível para uso comercial. Se você precisar de uma licença comercial para MiraData, não hesite em nos contatar.


