Uma estrutura para treinar modelos de base multimodais de qualquer tipo.
Escalável. Código aberto. Em dezenas de modalidades e tarefas.
EPFL-maçã
Website | BibTeX | ? Demo
Implementação oficial e modelos pré-treinados para:
4M: Modelagem Massivamente Multimodal Mascarada , NeurIPS 2023 (Destaque)
David Mizrahi*, Roman Bachmann*, Oğuzhan Fatih Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, Amir Zamir
4M-21: Um modelo de visão qualquer para qualquer para dezenas de tarefas e modalidades , NeurIPS 2024
Roman Bachmann*, Oğuzhan Fatih Kar*, David Mizrahi*, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir
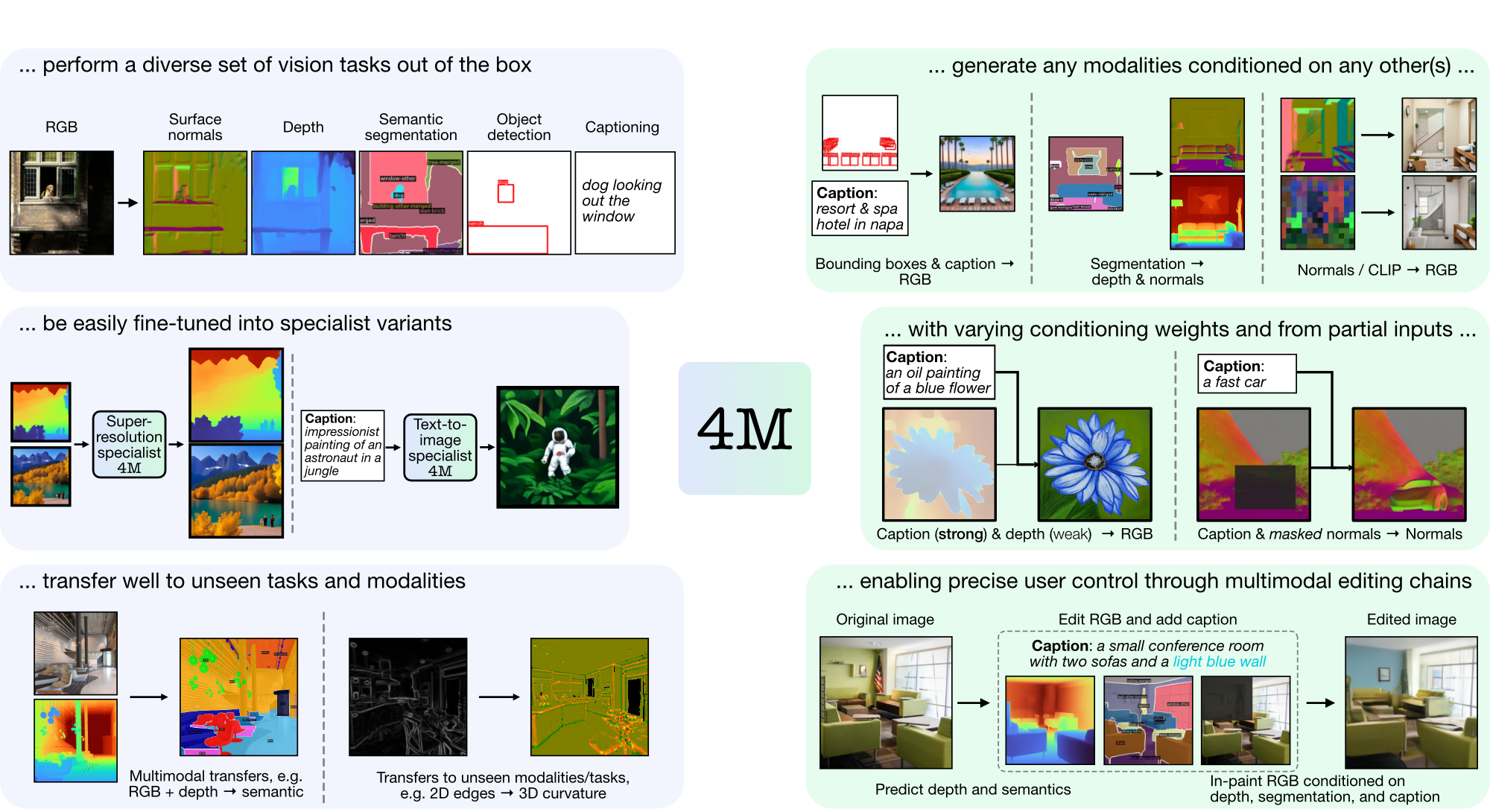
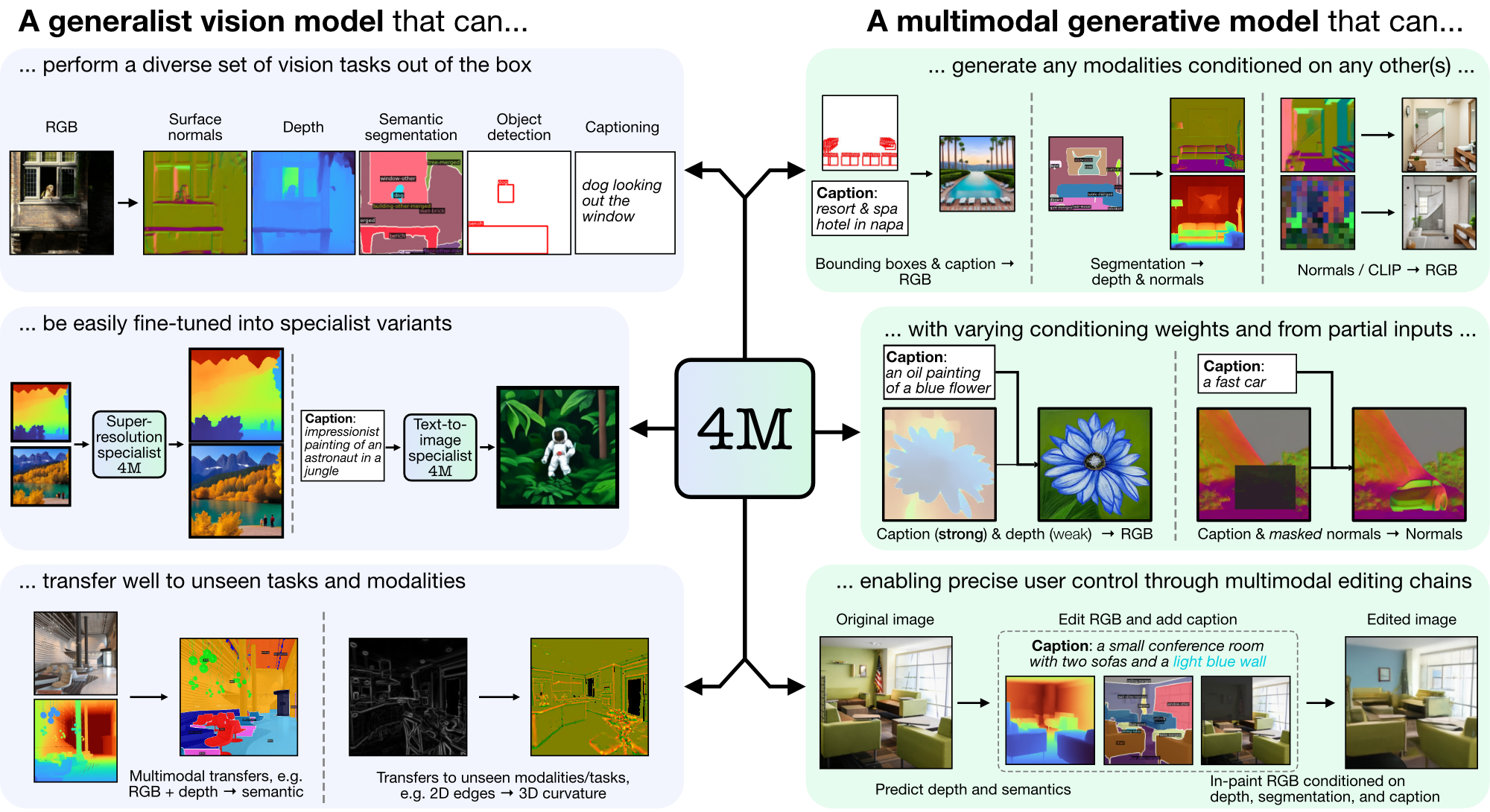
4M é uma estrutura para treinar modelos básicos "qualquer para qualquer", usando tokenização e mascaramento para escalar para diversas modalidades. Os modelos treinados usando 4M podem executar uma ampla gama de tarefas de visão, transferir-se bem para tarefas e modalidades invisíveis e são modelos generativos multimodais flexíveis e orientáveis. Estamos lançando código e modelos para "4M: Modelagem Massivamente Multimodal Mascarada" (aqui denotado 4M-7), bem como "4M-21: Um Modelo de Visão Any-to-Any para Dezenas de Tarefas e Modalidades" (aqui denotado 4M -21).
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
Se o CUDA não estiver disponível, considere reinstalar o PyTorch seguindo as instruções oficiais de instalação. Da mesma forma, se você deseja instalar xFormers (opcional, para tokenizadores mais rápidos), siga o README para garantir que a versão CUDA está correta.
Fornecemos um wrapper de demonstração para começar rapidamente a usar modelos 4M para tarefas de geração RGB para todos ou {legenda, caixas delimitadoras} para todos. Por exemplo, para gerar todas as modalidades de uma determinada entrada RGB, chame:
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )Você deve esperar ver uma saída como a seguinte:


Para realizar a geração de legenda para todos, você pode substituir a entrada do amostrador por: preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) . Para obter uma lista de modelos 4M disponíveis, consulte o zoológico de modelos abaixo e consulte README_GENERATION.md para obter mais instruções sobre geração.
Consulte README_DATA.md para obter instruções sobre como preparar conjuntos de dados multimodais alinhados.
Consulte README_TOKENIZATION.md para obter instruções sobre como treinar tokenizadores específicos da modalidade.
Consulte README_TRAINING.md para obter instruções sobre como treinar modelos 4M.
Consulte README_GENERATION.md para obter instruções sobre como usar modelos 4M para inferência/geração. Também fornecemos um caderno de geração que contém exemplos para inferência 4M, executando especificamente geração de imagens condicionais e tarefas de visão comuns (ou seja, RGB-to-All).
Fornecemos pontos de verificação 4M e tokenizer como tensores de segurança e também oferecemos carregamento fácil por meio do Hugging Face Hub.
| Modelo | # Mod. | Conjuntos de dados | # Parâmetros | Configuração | Pesos |
|---|---|---|---|---|---|
| 4MB-B | 7 | CC12M | 198 milhões | Configuração | Ponto de verificação / hub HF |
| 4MB-B | 7 | COYO700M | 198 milhões | Configuração | Ponto de verificação / hub HF |
| 4MB-B | 21 | CC12M+COYO700M+C4 | 198 milhões | Configuração | Ponto de verificação / hub HF |
| 4M-G | 7 | CC12M | 705 milhões | Configuração | Ponto de verificação / hub HF |
| 4M-G | 7 | COYO700M | 705 milhões | Configuração | Ponto de verificação / hub HF |
| 4M-G | 21 | CC12M+COYO700M+C4 | 705 milhões | Configuração | Ponto de verificação / hub HF |
| 4M-XL | 7 | CC12M | 2,8B | Configuração | Ponto de verificação / hub HF |
| 4M-XL | 7 | COYO700M | 2,8B | Configuração | Ponto de verificação / hub HF |
| 4M-XL | 21 | CC12M+COYO700M+C4 | 2,8B | Configuração | Ponto de verificação / hub HF |
Para carregar modelos do Hugging Face Hub:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )Para carregar os pontos de verificação manualmente, primeiro baixe os arquivos dos safetensors nos links acima e chame:
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )Esses modelos foram inicializados com os modelos padrão 4M-7 CC12M, mas continuaram o treinamento com uma mistura de modalidades fortemente voltada para entradas de texto. Eles ainda são capazes de executar todas as outras tarefas, mas apresentam melhor desempenho na geração de texto para imagem em comparação com os modelos não ajustados.
| Modelo | # Mod. | Conjuntos de dados | # Parâmetros | Configuração | Pesos |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198 milhões | Configuração | Ponto de verificação / hub HF |
| 4M-T2I-L | 7 | CC12M | 705 milhões | Configuração | Ponto de verificação / hub HF |
| 4M-T2I-XL | 7 | CC12M | 2,8B | Configuração | Ponto de verificação / hub HF |
Para carregar modelos do Hugging Face Hub:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )O carregamento manual a partir dos pontos de verificação é realizado da mesma forma acima para os modelos 4M básicos.
| Modelo | # Mod. | Conjuntos de dados | # Parâmetros | Configuração | Pesos |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198 milhões | Configuração | Ponto de verificação / hub HF |
Para carregar modelos do Hugging Face Hub:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )O carregamento manual a partir dos pontos de verificação é realizado da mesma forma acima para os modelos 4M básicos.
| Modalidade | Resolução | Número de tokens | Tamanho do livro de códigos | Decodificador de difusão | Pesos |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16k | ✓ | Ponto de verificação / hub HF |
| Profundidade | 224-448 | 196-784 | 8k | ✓ | Ponto de verificação / hub HF |
| Normais | 224-448 | 196-784 | 8k | ✓ | Ponto de verificação / hub HF |
| Bordas (Canny, SAM) | 224-512 | 196-1024 | 8k | ✓ | Ponto de verificação / hub HF |
| Segmentação semântica COCO | 224-448 | 196-784 | 4k | ✗ | Ponto de verificação / hub HF |
| CLIP-B/16 | 224-448 | 196-784 | 8k | ✗ | Ponto de verificação / hub HF |
| DINov2-B/14 | 224-448 | 256-1024 | 8k | ✗ | Ponto de verificação / hub HF |
| DINOv2-B/14 (global) | 224 | 16 | 8k | ✗ | Ponto de verificação / hub HF |
| ImageBind-H/14 | 224-448 | 256-1024 | 8k | ✗ | Ponto de verificação / hub HF |
| ImageBind-H/14 (global) | 224 | 16 | 8k | ✗ | Ponto de verificação / hub HF |
| Instâncias SAM | - | 64 | 1k | ✗ | Ponto de verificação / hub HF |
| Poses humanas 3D | - | 8 | 1k | ✗ | Ponto de verificação / hub HF |
Para carregar modelos do Hugging Face Hub:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )Para carregar os pontos de verificação manualmente, primeiro baixe os arquivos dos safetensors nos links acima e chame:
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )O código neste repositório é lançado sob a licença Apache 2.0 conforme encontrado no arquivo LICENSE.
Os pesos do modelo neste repositório são liberados sob a licença Sample Code conforme encontrado no arquivo LICENSE_WEIGHTS.
Se você achar este repositório útil, considere citar nosso trabalho:
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


