tempestade
v1.0.0 & EMNLP 2024 Paper Accepted!
| Prévia da pesquisa | Papel TEMPESTADE | Artigo Co-STORM | Site |
Últimas Notícias
[2024/09] A base de código Co-STORM foi lançada e integrada ao pacote Python v1.0.0 knowledge-storm . Execute pip install knowledge-storm --upgrade para verificar.
[2024/09] Apresentamos o STORM colaborativo (Co-STORM) para apoiar a curadoria de conhecimento colaborativo humano-IA! O artigo Co-STORM foi aceito na conferência principal EMNLP 2024.
[2024/07] Agora você pode instalar nosso pacote com pip install knowledge-storm !
[2024/07] Adicionamos VectorRM para apoiar o embasamento em documentos fornecidos pelo usuário, complementando o suporte existente de mecanismos de busca ( YouRM , BingSearch ). (confira #58)
[2024/07] Lançamos demo light para desenvolvedores, uma interface de usuário mínima construída com estrutura streamlit em Python, útil para desenvolvimento local e hospedagem de demonstração (checkout #54)
[2024/06] Apresentaremos STORM na NAACL 2024! Encontre-nos na Sessão de Pôsteres 2 no dia 17 de junho ou confira nosso material de apresentação.
[2024/05] Adicionamos suporte ao Bing Search em rm.py. Teste STORM com GPT-4o - agora configuramos a parte de geração de artigos em nossa demonstração usando o modelo GPT-4o .
[2024/04] Lançamos uma versão refatorada da base de código STORM! Definimos a interface para o pipeline STORM e reimplementamos o STORM-wiki (confira src/storm_wiki ) para demonstrar como instanciar o pipeline. Fornecemos API para oferecer suporte à personalização de diferentes modelos de linguagem e integração de recuperação/pesquisa.
Embora o sistema não possa produzir artigos prontos para publicação que muitas vezes exigem um número significativo de edições, editores experientes da Wikipédia consideraram-no útil na fase de pré-escrita.
Mais de 70.000 pessoas experimentaram nossa prévia da pesquisa ao vivo. Experimente para ver como o STORM pode ajudar em sua jornada de exploração de conhecimento e forneça feedback para nos ajudar a melhorar o sistema!
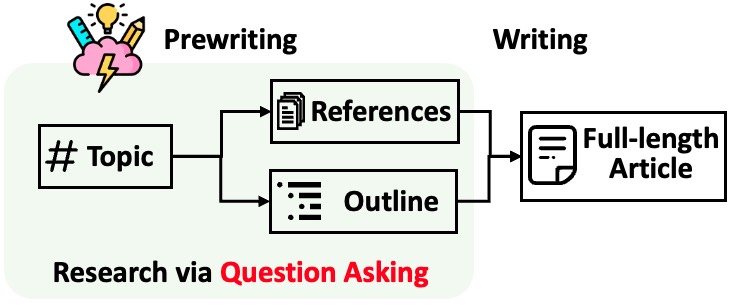
STORM divide a geração de artigos longos com citações em duas etapas:
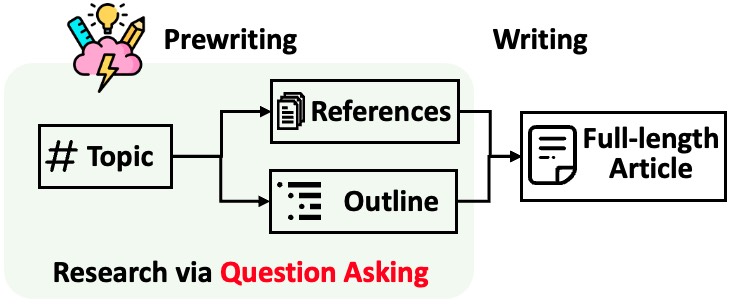
STORM identifica que o cerne da automação do processo de pesquisa é a criação automática de boas perguntas a serem feitas. Solicitar diretamente ao modelo de linguagem que faça perguntas não funciona bem. Para melhorar a profundidade e amplitude das questões, o STORM adota duas estratégias:
Co-STORM propõe um protocolo de discurso colaborativo que implementa uma política de gerenciamento de turnos para apoiar a colaboração tranquila entre
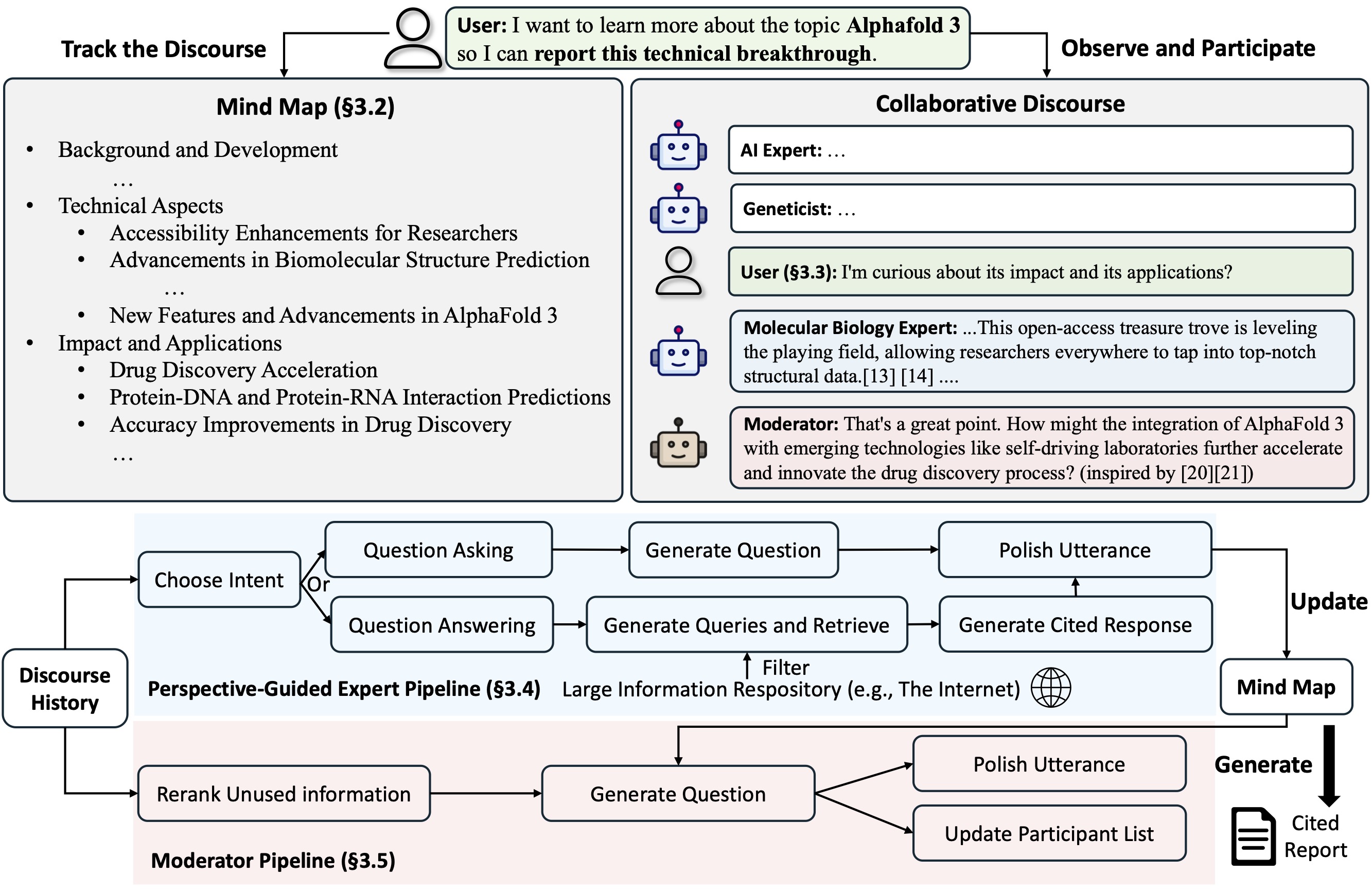
O Co-STORM também mantém um mapa mental atualizado e dinâmico, que organiza as informações coletadas em uma estrutura conceitual hierárquica, visando construir um espaço conceitual compartilhado entre o usuário humano e o sistema . Foi comprovado que o mapa mental ajuda a reduzir a carga mental quando o discurso é longo e profundo.
Tanto STORM quanto Co-STORM são implementados de forma altamente modular usando dspy.
Para instalar a biblioteca Knowledge Storm, use pip install knowledge-storm .
Você também pode instalar o código-fonte que permite modificar o comportamento do mecanismo STORM diretamente.
Clone o repositório git.
git clone https://github.com/stanford-oval/storm.git
cd stormInstale os pacotes necessários.
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txtAtualmente, nosso pacote suporta:
OpenAIModel , AzureOpenAIModel , ClaudeModel , VLLMClient , TGIClient , TogetherClient , OllamaClient , GoogleModel , DeepSeekModel , GroqModel como componentes do modelo de linguagemYouRM , BingSearch , VectorRM , SerperRM , BraveRM , SearXNG , DuckDuckGoSearchRM , TavilySearchRM , GoogleSearch e AzureAISearch como componentes do módulo de recuperação? PRs para integração de mais modelos de linguagem em Knowledge_storm/lm.py e mecanismos de pesquisa/retrievers em Knowledge_storm/rm.py são muito apreciados!
Tanto STORM quanto Co-STORM estão trabalhando na camada de curadoria de informações, você precisa configurar o módulo de recuperação de informações e o módulo de modelo de linguagem para criar suas classes Runner , respectivamente.
O mecanismo de curadoria de conhecimento STORM é definido como uma classe simples Python STORMWikiRunner . Aqui está um exemplo de uso do mecanismo de pesquisa You.com e dos modelos OpenAI.
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) A instância STORMWikiRunner pode ser evocada com o método run simples:
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : se True, simula conversas com diferentes perspectivas para coletar informações sobre o tema; caso contrário, carregue os resultados.do_generate_outline : se True, gera um esboço para o tópico; caso contrário, carregue os resultados.do_generate_article : se True, gera um artigo para o tema com base no esboço e nas informações coletadas; caso contrário, carregue os resultados.do_polish_article : se True, aprimora o artigo adicionando uma seção de resumo e (opcionalmente) removendo conteúdo duplicado; caso contrário, carregue os resultados. O mecanismo de curadoria de conhecimento Co-STORM é definido como uma classe Python CoStormRunner simples. Aqui está um exemplo de uso do mecanismo de pesquisa Bing e modelos OpenAI.
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) A instância CoStormRunner pode ser evocada com os métodos warmstart() e step(...) .
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )Fornecemos scripts em nossa pasta de exemplos como um início rápido para executar STORM e Co-STORM com configurações diferentes.
Sugerimos usar secrets.toml para configurar as chaves de API. Crie um arquivo secrets.toml no diretório raiz e adicione o seguinte conteúdo:
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " Para executar o STORM com modelos da família gpt com configurações padrão:
Execute o seguinte comando.
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articlePara executar o STORM usando seus modelos de linguagem favoritos ou com base em seu próprio corpus: Confira exemplos/storm_examples/README.md.
Para executar o Co-STORM com modelos da família gpt com configurações padrão,
BING_SEARCH_API_KEY="xxx" e ENCODER_API_TYPE="xxx" a secrets.tomlpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingSe você instalou o código-fonte, poderá personalizar o STORM com base em seu próprio caso de uso. O motor STORM consiste em 4 módulos:
A interface de cada módulo é definida em knowledge_storm/interface.py , enquanto suas implementações são instanciadas em knowledge_storm/storm_wiki/modules/* . Esses módulos podem ser personalizados de acordo com suas necessidades específicas (por exemplo, gerando seções em formato de marcadores em vez de parágrafos completos).
Se você instalou o código-fonte, poderá personalizar o Co-STORM com base em seu próprio caso de uso
knowledge_storm/interface.py , enquanto sua implementação é instanciada em knowledge_storm/collaborative_storm/modules/co_storm_agents.py . Diferentes políticas de agente LLM podem ser personalizadas.DiscourseManager em knowledge_storm/collaborative_storm/engine.py . Ele pode ser personalizado e melhorado ainda mais. Para facilitar o estudo da curadoria automática de conhecimento e da busca complexa de informações, nosso projeto lança os seguintes conjuntos de dados:
O conjunto de dados FreshWiki é uma coleção de 100 artigos da Wikipedia de alta qualidade com foco nas páginas mais editadas de fevereiro de 2022 a setembro de 2023. Consulte a Seção 2.1 do artigo STORM para obter mais detalhes.
Você pode baixar o conjunto de dados diretamente do huggingface. Para amenizar o problema de contaminação de dados, arquivamos o código-fonte do pipeline de construção de dados que pode ser repetido em datas futuras.
Para estudar os interesses dos usuários em tarefas complexas de busca de informações, utilizamos dados coletados da visualização de pesquisa na web para criar o conjunto de dados WildSeek. Reduzimos a amostragem dos dados para garantir a diversidade dos tópicos e a qualidade dos dados. Cada ponto de dados é um par que compreende um tópico e o objetivo do usuário para realizar uma pesquisa profunda sobre o tópico. Para obter mais detalhes, consulte a Seção 2.2 e o Apêndice A do documento Co-STORM.
O conjunto de dados WildSeek está disponível aqui.
Para experimentos em papel STORM, mude para o branch NAACL-2024-code-backup aqui.
Para experimentos em papel Co-STORM, mude para o branch EMNLP-2024-code-backup (espaço reservado por enquanto, será atualizado em breve).
Nossa equipe está trabalhando ativamente em:
Se você tiver alguma dúvida ou sugestão, sinta-se à vontade para abrir um problema ou solicitar pull. Agradecemos contribuições para melhorar o sistema e a base de código!
Pessoa de contato: Yijia Shao e Yucheng Jiang
Gostaríamos de agradecer à Wikipedia pelo seu excelente conteúdo de código aberto. O conjunto de dados FreshWiki é proveniente da Wikipedia, licenciado sob a licença Creative Commons Attribution-ShareAlike (CC BY-SA).
Somos muito gratos a Michelle Lam por desenhar o logotipo deste projeto e a Dekun Ma por liderar o desenvolvimento da UI.
Por favor, cite nosso artigo se você usar este código ou parte dele em seu trabalho:
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}