bulk
1.0.0
Bulk é uma ferramenta de desenvolvedor rápida para aplicar alguns rótulos em massa. Dado um conjunto de dados preparado com embeddings 2D, ele pode gerar uma interface que permite adicionar rapidamente algumas anotações em massa, embora menos precisas.
python -m pip install --upgrade pip
python -m pip install bulk
O futuro do bulk é oferecer widgets que possam te ajudar no notebook. No momento, o BaseTextExplorer é o widget principal suportado. Dados alguns dados pré-processados, você pode usar o explorador para vasculhar um UMAP 2D de incorporações de texto.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]Para usar o widget, você só precisa executar isto:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()Isso nos permitirá explorar rapidamente os clusters que aparecem em nossos dados. Você pode segurar o cursor do mouse para entrar no modo de seleção e, ao selecionar itens, verá um subconjunto aleatório aparecer à direita. Você pode reamostrar sua seleção clicando no botão reamostrar.
Ao fazer seleções, você pode ver o widget na atualização correta, mas também pode obter os dados de um atributo Python.
widget . selected_idx
widget . selected_texts
widget . selected_dataframeSer capaz de explorar esses clusters é legal, mas parece que poderemos explorar tudo mais facilmente se tivermos mais ferramentas à nossa disposição. Em particular, queremos ter um codificador disponível para que possamos usar consultas em nosso espaço incorporado. A IU abaixo nos permitirá explorar de forma muito mais interativa, atualizando as cores com um prompt de texto.
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()Graças a ferramentas como ipywidget e anywidget, podemos realmente começar a construir algumas ferramentas para manter o notebook no local ideal para suas necessidades de dados. Com alguns widgets adequados, você nunca será capaz de superar um notebook Jupyter!
O principal interesse deste projeto é trabalhar em ferramentas para qualidade de dados. Ser capaz de selecionar pontos de dados em massa parece um ótimo lugar para começar. Talvez você possa encontrar um subconjunto interessante para anotar primeiro, talvez fique surpreso ao ver dois clusters distintos que deveriam ser um. Todas essas coisas boas podem acontecer no notebook!
Bulk também vem com um pequeno aplicativo da web que usa Bokeh para fornecer interfaces de anotação baseadas em representações UMAP de embeddings. Oferece uma interface para texto. Esta interface foi a interface/recurso original deste projeto.
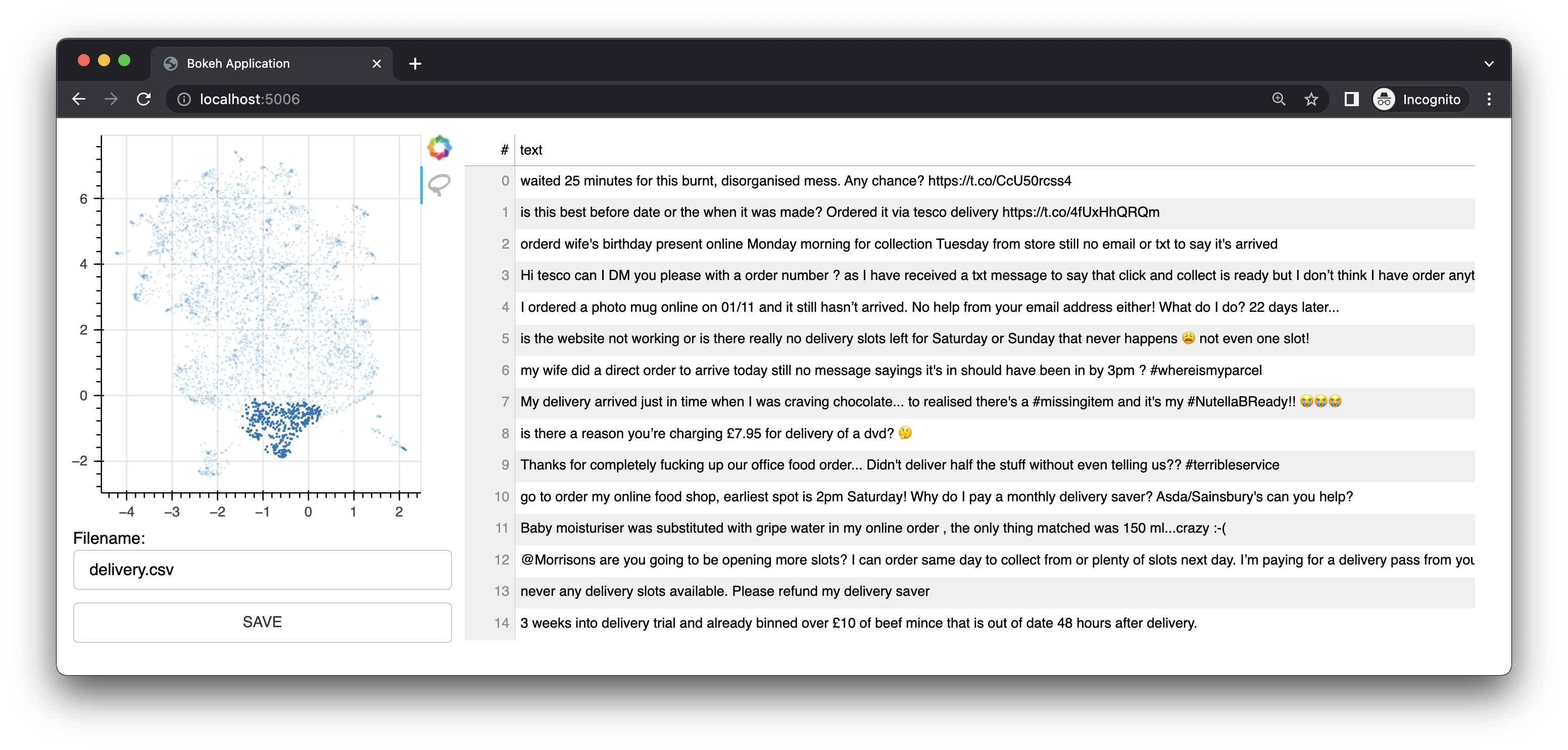
Ele também possui uma interface de imagem.
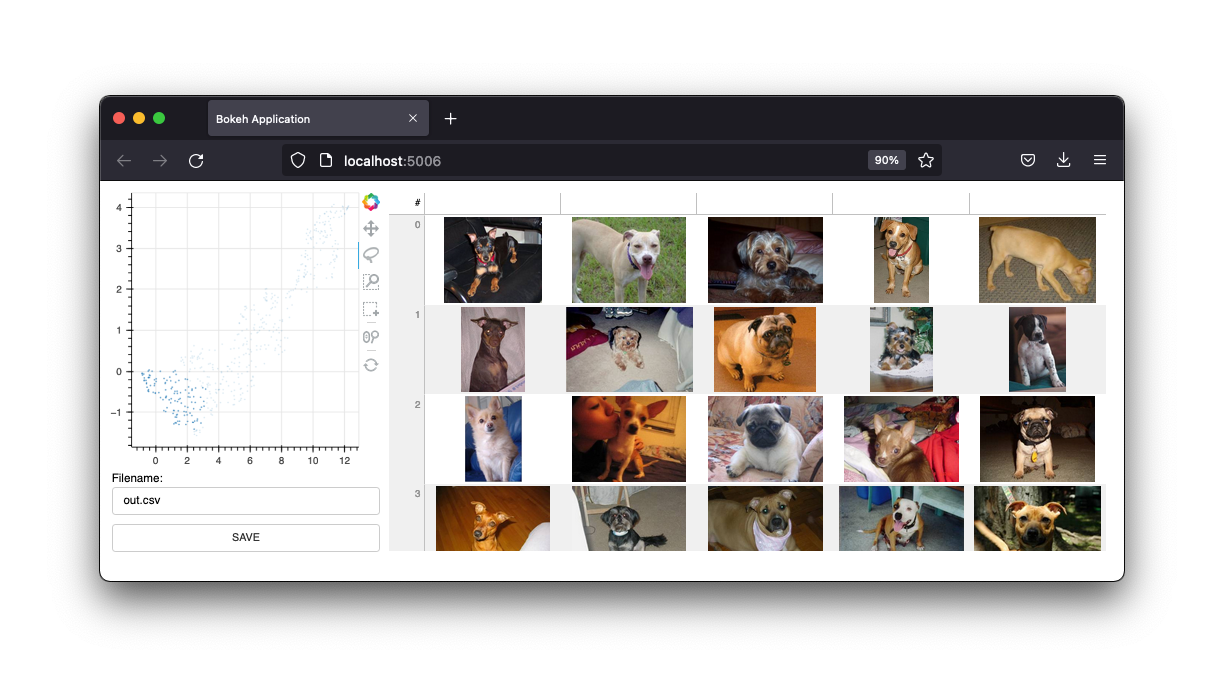
Manteremos essas interfaces, mas o futuro deste projeto serão os widgets de um notebook Jupyter. No entanto, o webapp certamente ainda é útil.
Se você estiver curioso para saber mais, pode gostar deste vídeo no YouTube para texto e deste vídeo no YouTube para visão computacional.
Para usar em massa para texto, primeiro você precisa preparar um arquivo csv.
Observação
O exemplo abaixo usa embetter para gerar os embeddings e umap para reduzir as dimensões. Mas você é totalmente livre para usar qualquer ferramenta de incorporação de texto que desejar. Você precisará instalar essas ferramentas separadamente. Observe que o embetter usa transformadores de frases nos bastidores.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) Agora você pode usar este arquivo ready.csv para aplicar alguma rotulagem em massa.
python -m bulk text ready.csv
Se você estiver procurando um arquivo de exemplo para brincar, você pode baixar o arquivo de demonstração .csv neste repositório. Este conjunto de dados contém um subconjunto de um conjunto de dados encontrado no Kaggle. Você pode encontrar o original aqui.
Você também pode passar uma coluna extra para o seu arquivo csv chamada "color". Esta coluna será então usada para colorir os pontos na interface.
Você também pode passar --keywords para o aplicativo de linha de comando para destacar elementos que contêm palavras-chave específicas.
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
O exemplo abaixo usa a biblioteca embetter para criar um conjunto de dados para rotular imagens em massa.
Observação
O exemplo abaixo usa embetter para gerar os embeddings e umap para reduzir as dimensões. Mas você é totalmente livre para usar qualquer ferramenta de incorporação de texto que desejar. Você precisará instalar essas ferramentas separadamente. Observe que o embetter usa TIMM nos bastidores.
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )Isso gera um arquivo csv que pode ser carregado em massa via;
python -m bulk image ready.csv
Você também pode gerar um conjunto de miniaturas para suas imagens. Isso pode ser útil se você estiver trabalhando com um grande conjunto de dados.
python -m bulk util resize ready.csv ready2.csv temp
Isso criará uma pasta chamada temp com todas as imagens redimensionadas. Você pode então usar esta pasta como o argumento --thumbnail-path .
python -m bulk image ready2.csv --thumbnail-path temp
Você também pode usar o volume para baixar alguns conjuntos de dados para brincar. Para mais informações:
python -m bulk download --help
A interface pode ajudá-lo a rotular muito rapidamente, mas os rótulos em si podem ser bastante barulhentos. O caso de uso pretendido para esta ferramenta é preparar subconjuntos interessantes para serem usados posteriormente no prodi.gy.


