system design 101
1.0.0
【 ??YouTube | ? Boletim informativo 】
Explique sistemas complexos usando recursos visuais e termos simples.
Esteja você se preparando para uma entrevista de design de sistema ou simplesmente queira entender como os sistemas funcionam abaixo da superfície, esperamos que este repositório o ajude a conseguir isso.
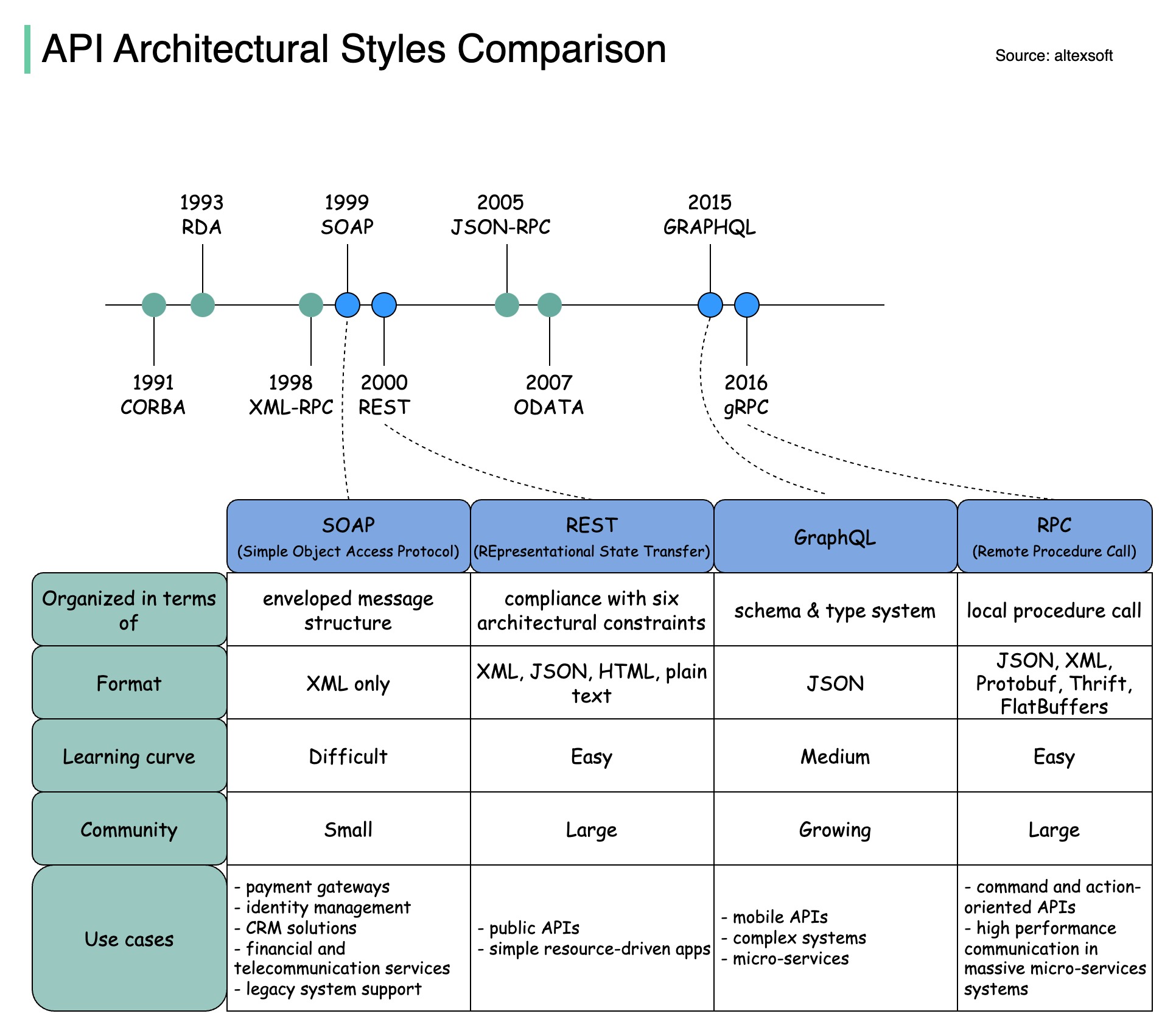
Os estilos de arquitetura definem como os diferentes componentes de uma interface de programação de aplicativos (API) interagem entre si. Como resultado, eles garantem eficiência, confiabilidade e facilidade de integração com outros sistemas, fornecendo uma abordagem padrão para projetar e construir APIs. Aqui estão os estilos mais usados:
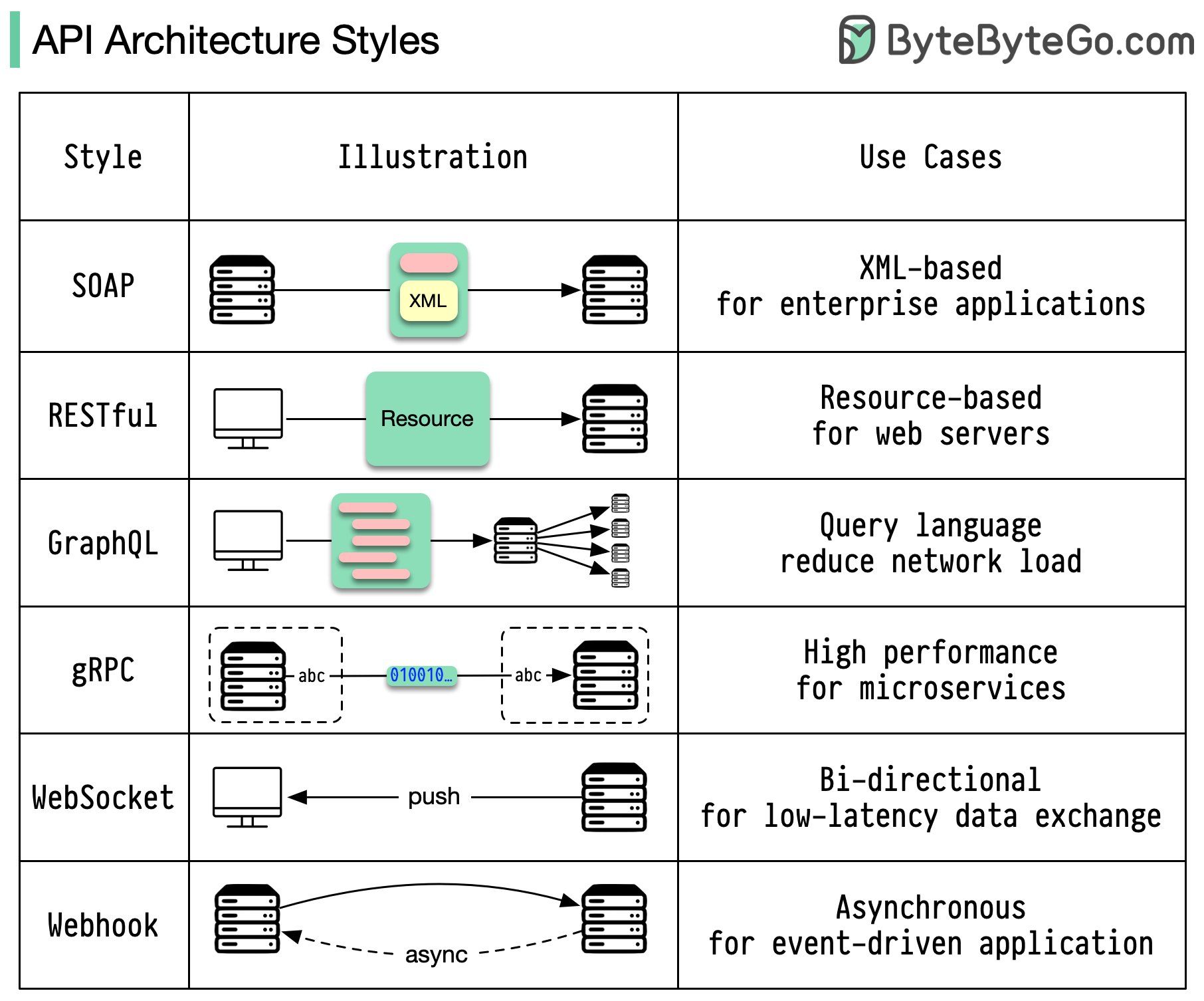
SABÃO:
Maduro, abrangente, baseado em XML
Melhor para aplicativos corporativos
Repousante:
Métodos HTTP populares e fáceis de implementar
Ideal para serviços web
GráficoQL:
Linguagem de consulta, solicite dados específicos
Reduz a sobrecarga da rede, respostas mais rápidas
gRPC:
Buffers de protocolo modernos e de alto desempenho
Adequado para arquiteturas de microsserviços
WebSocket:
Conexões persistentes, bidirecionais e em tempo real
Perfeito para troca de dados de baixa latência
Webhook:
Retornos de chamada HTTP orientados a eventos, assíncronos
Notifica os sistemas quando ocorrem eventos
Quando se trata de design de API, REST e GraphQL têm seus próprios pontos fortes e fracos.
O diagrama abaixo mostra uma comparação rápida entre REST e GraphQL.
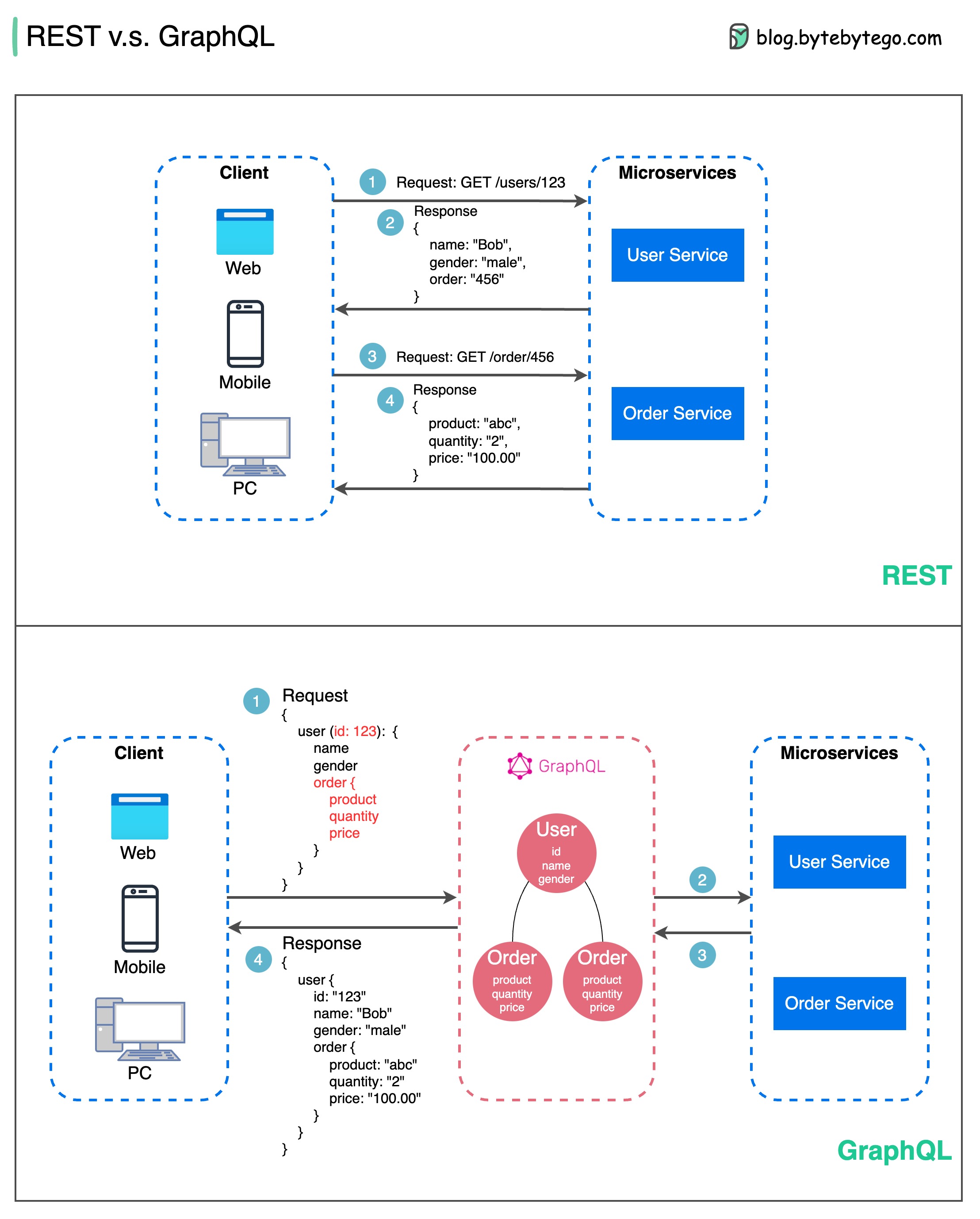
DESCANSAR
GráficoQL
A melhor escolha entre REST e GraphQL depende dos requisitos específicos da aplicação e da equipe de desenvolvimento. GraphQL é uma boa opção para necessidades de front-end complexas ou que mudam frequentemente, enquanto REST é adequado para aplicações onde contratos simples e consistentes são preferidos.
Nenhuma das abordagens de API é uma solução mágica. Avaliar cuidadosamente os requisitos e as compensações é importante para escolher o estilo certo. Tanto REST quanto GraphQL são opções válidas para expor dados e potencializar aplicativos modernos.
RPC (Remote Procedure Call) é chamado de “ remoto ” porque permite comunicações entre serviços remotos quando os serviços são implantados em diferentes servidores sob arquitetura de microsserviços. Do ponto de vista do usuário, funciona como uma chamada de função local.
O diagrama abaixo ilustra o fluxo geral de dados para gRPC .
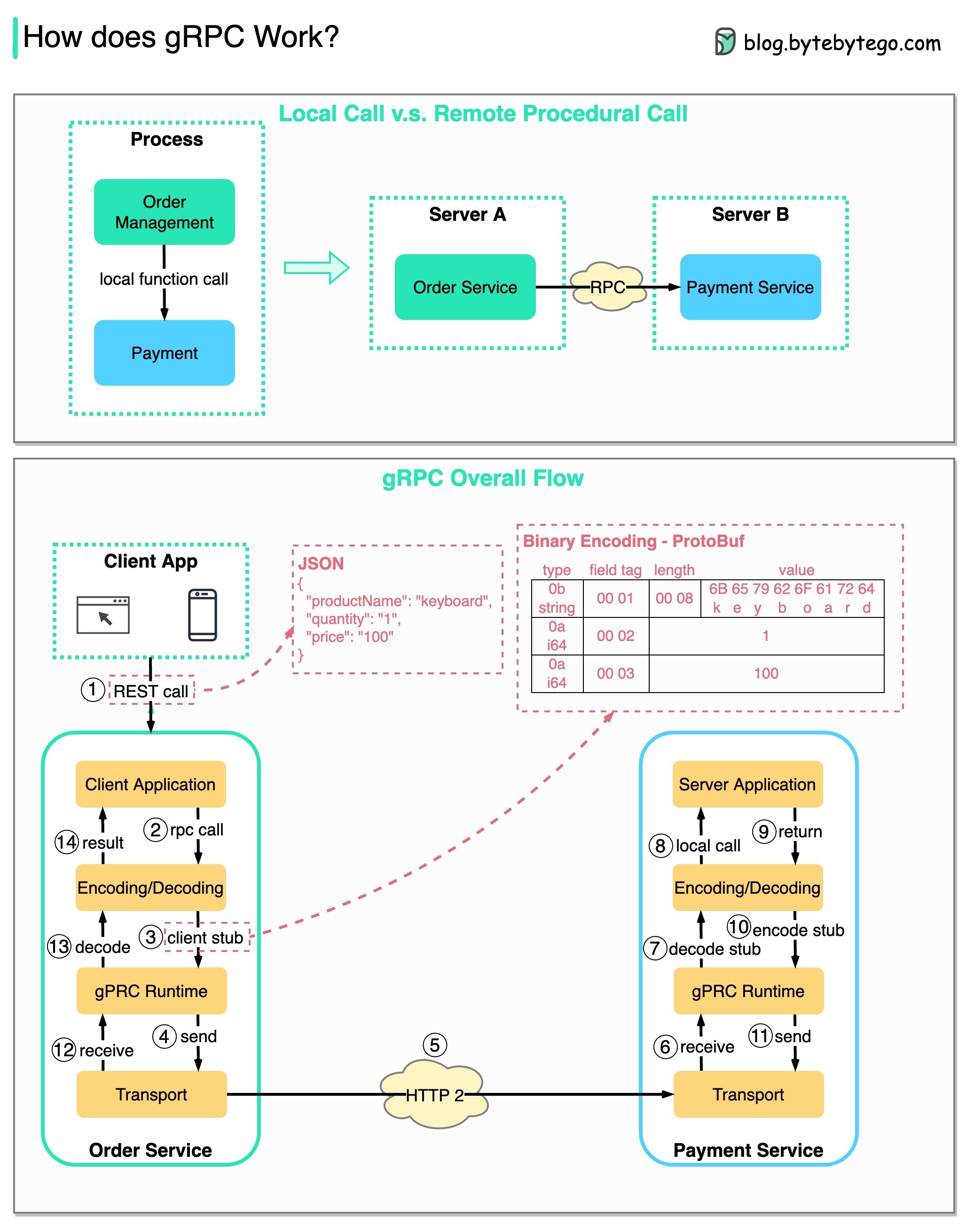
Etapa 1: uma chamada REST é feita no cliente. O corpo da solicitação geralmente está no formato JSON.
Etapas 2 a 4: O serviço de pedidos (cliente gRPC) recebe a chamada REST, transforma-a e faz uma chamada RPC para o serviço de pagamento. O gRPC codifica o stub do cliente em um formato binário e o envia para a camada de transporte de baixo nível.
Etapa 5: o gRPC envia os pacotes pela rede via HTTP2. Devido à codificação binária e às otimizações de rede, diz-se que o gRPC é 5 vezes mais rápido que o JSON.
Etapas 6 a 8: O serviço de pagamento (servidor gRPC) recebe os pacotes da rede, decodifica-os e invoca o aplicativo do servidor.
Etapas 9 a 11: O resultado é retornado da aplicação do servidor e é codificado e enviado para a camada de transporte.
Etapas 12 a 14: O serviço de pedido recebe os pacotes, decodifica-os e envia o resultado ao aplicativo cliente.
O diagrama abaixo mostra uma comparação entre polling e Webhook.
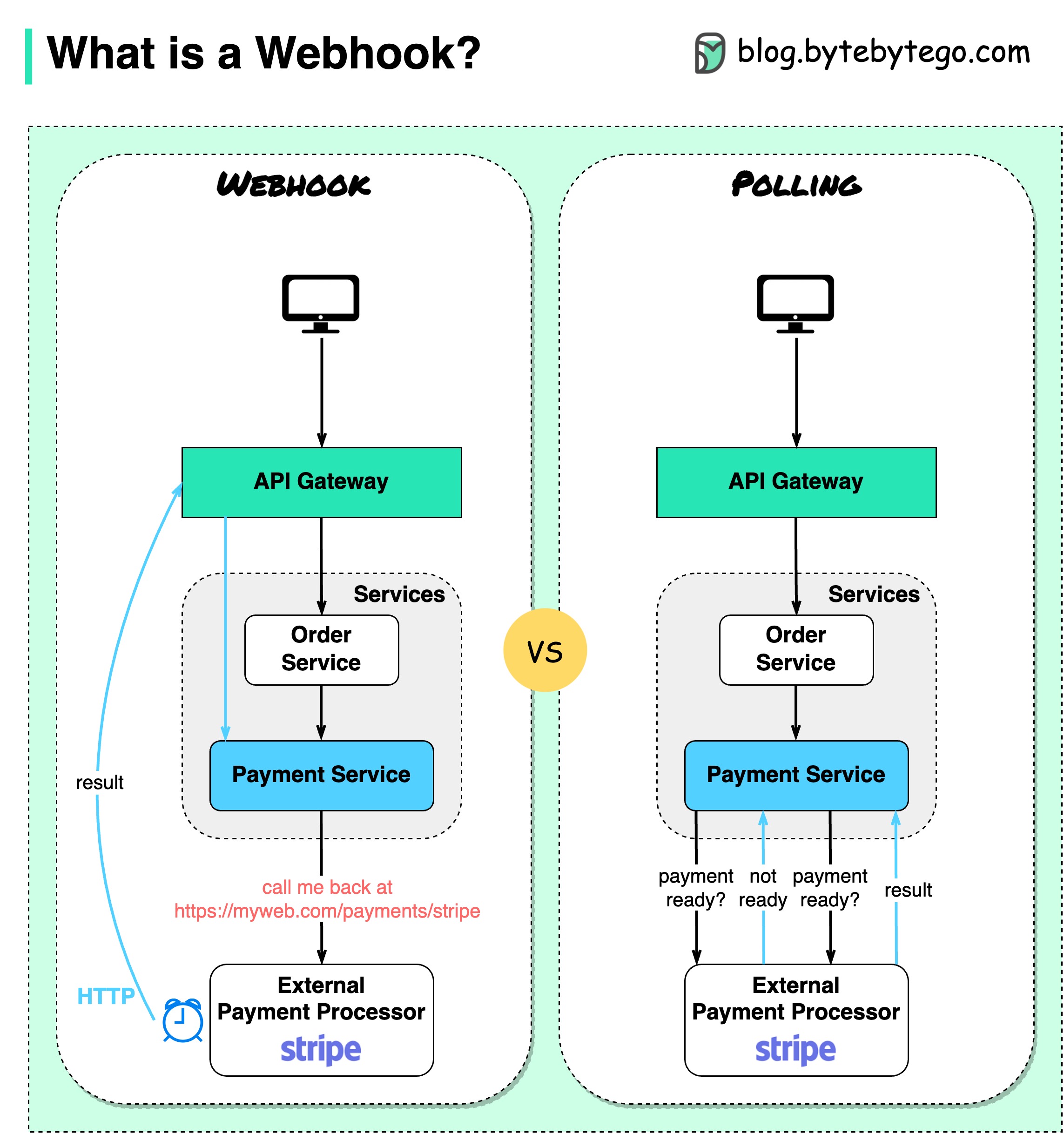
Suponha que tenhamos um site de comércio eletrônico. Os clientes enviam pedidos para o serviço de pedidos através do gateway API, que vai até o serviço de pagamento para transações de pagamento. O serviço de pagamento então conversa com um provedor de serviços de pagamento externo (PSP) para concluir as transações.
Existem duas maneiras de lidar com as comunicações com o PSP externo.
1. Pesquisa curta
Depois de enviar o pedido de pagamento ao PSP, o serviço de pagamento continua a perguntar ao PSP sobre o estado do pagamento. Após diversas rodadas, o PSP finalmente retorna com o status.
A pesquisa curta tem duas desvantagens:
2. Webhook
Podemos registrar um webhook no serviço externo. Significa: me ligue de volta em um determinado URL quando tiver atualizações sobre a solicitação. Quando o PSP concluir o processamento, irá invocar o pedido HTTP para atualizar o estado do pagamento.
Desta forma, o paradigma de programação é alterado e o serviço de pagamento não precisa mais desperdiçar recursos para consultar o status do pagamento.
E se o PSP nunca ligar de volta? Podemos configurar um trabalho de limpeza para verificar o status do pagamento a cada hora.
Webhooks são frequentemente chamados de APIs reversas ou APIs push porque o servidor envia solicitações HTTP ao cliente. Precisamos prestar atenção a três coisas ao usar um webhook:
O diagrama abaixo mostra 5 truques comuns para melhorar o desempenho da API.
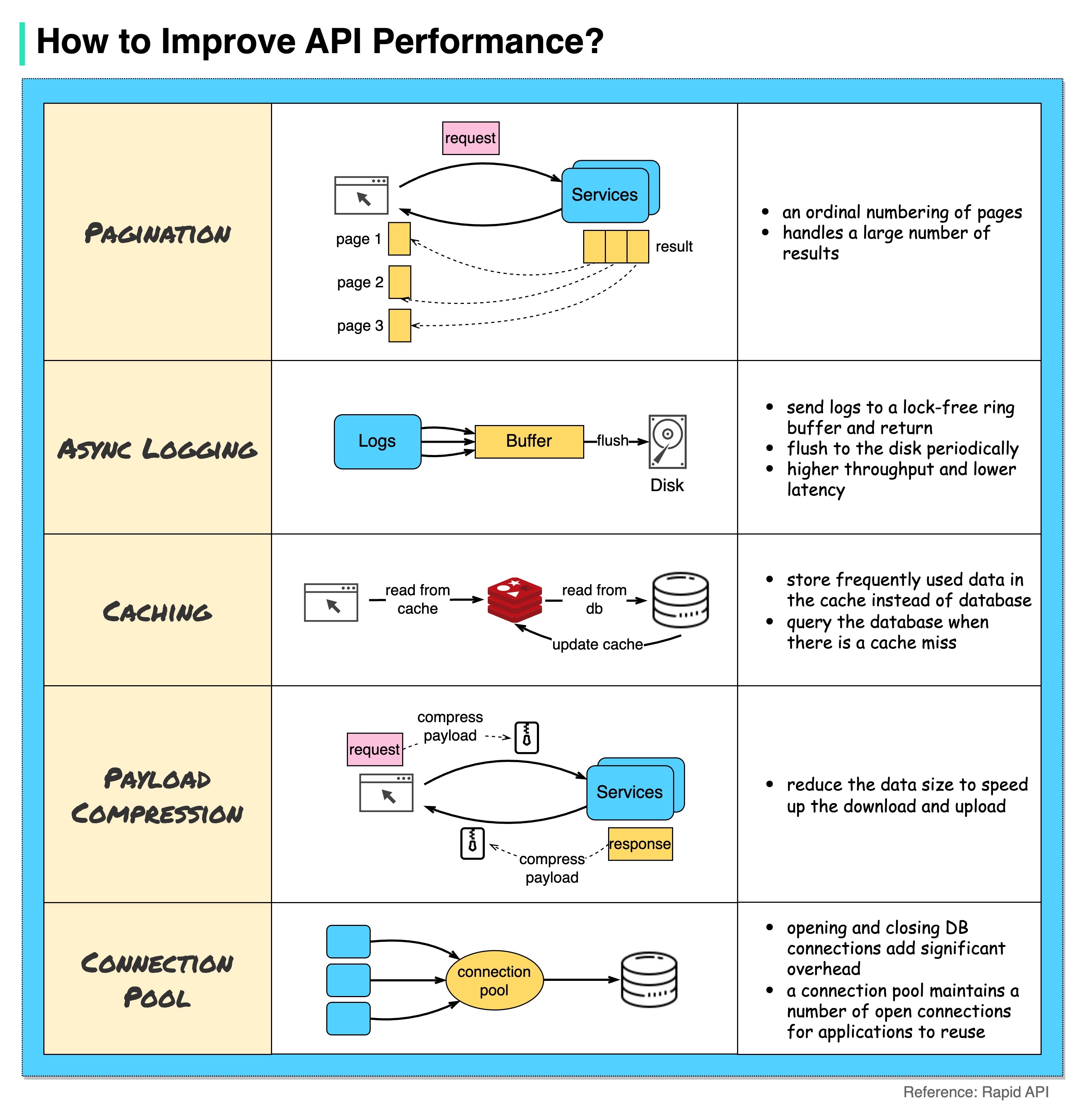
Paginação
Esta é uma otimização comum quando o tamanho do resultado é grande. Os resultados são transmitidos de volta ao cliente para melhorar a capacidade de resposta do serviço.
Registro assíncrono
O registro síncrono lida com o disco para cada chamada e pode tornar o sistema lento. O registro assíncrono envia primeiro os logs para um buffer sem bloqueio e retorna imediatamente. Os logs serão descarregados no disco periodicamente. Isso reduz significativamente a sobrecarga de E/S.
Cache
Podemos armazenar dados acessados com frequência em um cache. O cliente pode consultar primeiro o cache em vez de visitar diretamente o banco de dados. Se houver uma falta de cache, o cliente poderá consultar no banco de dados. Caches como o Redis armazenam dados na memória, portanto o acesso aos dados é muito mais rápido que o banco de dados.
Compressão de carga útil
As solicitações e respostas podem ser compactadas usando gzip etc. para que o tamanho dos dados transmitidos seja muito menor. Isso acelera o upload e o download.
Conjunto de conexões
Ao acessar recursos, muitas vezes precisamos carregar dados do banco de dados. Abrir as conexões de fechamento do banco de dados adiciona uma sobrecarga significativa. Portanto, devemos nos conectar ao banco de dados por meio de um conjunto de conexões abertas. O pool de conexões é responsável por gerenciar o ciclo de vida da conexão.
Que problema cada geração de HTTP resolve?
O diagrama abaixo ilustra os principais recursos.
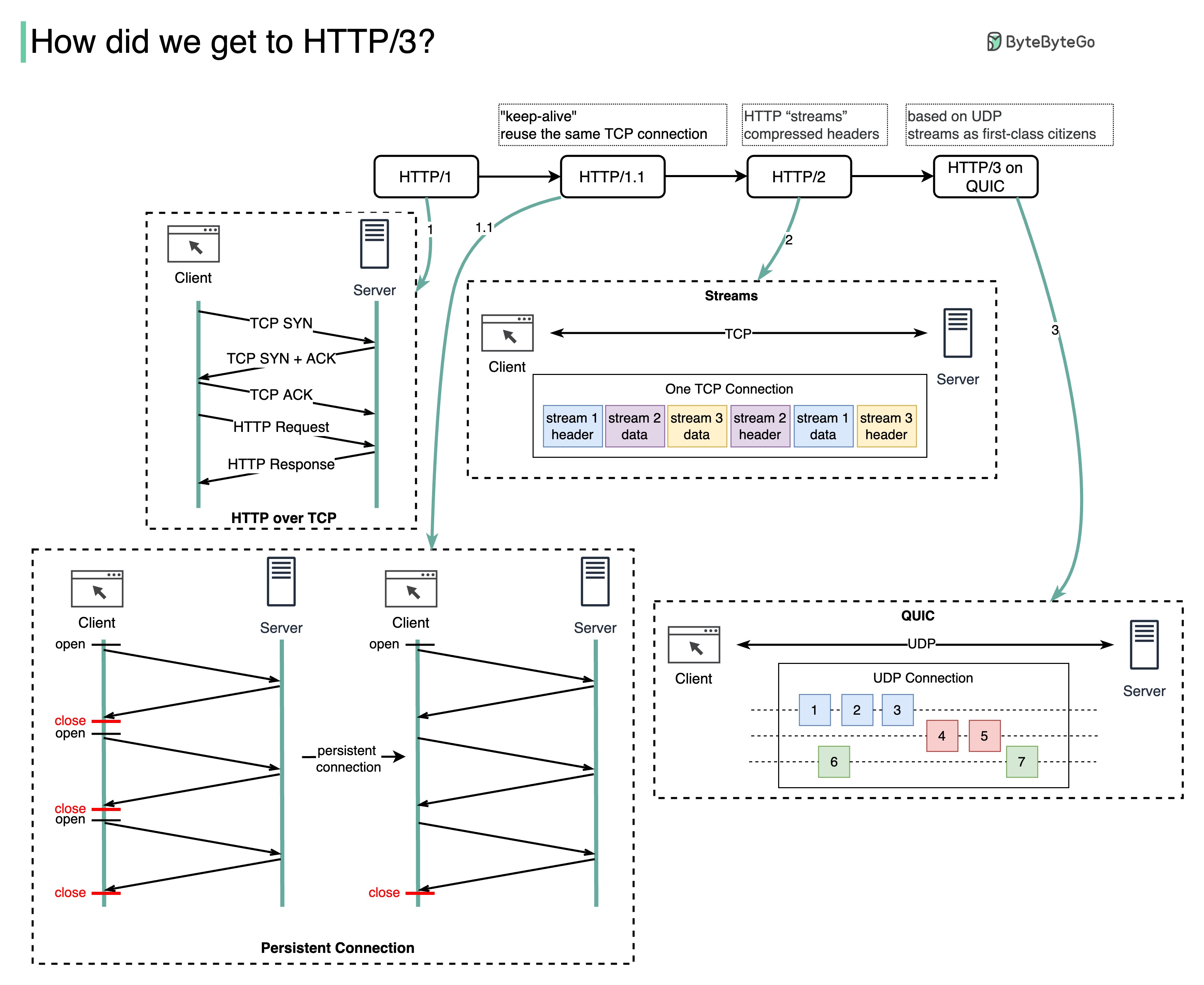
O HTTP 1.0 foi finalizado e totalmente documentado em 1996. Cada solicitação para o mesmo servidor requer uma conexão TCP separada.
O HTTP 1.1 foi publicado em 1997. Uma conexão TCP pode ser deixada aberta para reutilização (conexão persistente), mas não resolve o problema de bloqueio HOL (head-of-line).
Bloqueio HOL - quando o número de solicitações paralelas permitidas no navegador se esgota, as solicitações subsequentes precisam aguardar a conclusão das anteriores.
O HTTP 2.0 foi publicado em 2015. Ele aborda o problema do HOL por meio da multiplexação de solicitações, o que elimina o bloqueio do HOL na camada de aplicação, mas o HOL ainda existe na camada de transporte (TCP).
Como você pode ver no diagrama, o HTTP 2.0 introduziu o conceito de “streams” HTTP: uma abstração que permite multiplexar diferentes trocas HTTP na mesma conexão TCP. Cada fluxo não precisa ser enviado em ordem.
O primeiro rascunho do HTTP 3.0 foi publicado em 2020. É o sucessor proposto do HTTP 2.0. Ele usa QUIC em vez de TCP para o protocolo de transporte subjacente, removendo assim o bloqueio HOL na camada de transporte.
QUIC é baseado em UDP. Apresenta os fluxos como cidadãos de primeira classe na camada de transporte. Os fluxos QUIC compartilham a mesma conexão QUIC, portanto, nenhum handshake adicional e início lento são necessários para criar novos, mas os fluxos QUIC são entregues de forma independente, de modo que, na maioria dos casos, a perda de pacotes que afeta um fluxo não afeta outros.
O diagrama abaixo ilustra a linha do tempo da API e a comparação de estilos de API.
Com o tempo, diferentes estilos arquitetônicos de API são lançados. Cada um deles tem seus próprios padrões de padronização da troca de dados.
Você pode conferir os casos de uso de cada estilo no diagrama.
O diagrama abaixo mostra as diferenças entre o desenvolvimento que prioriza o código e o desenvolvimento que prioriza a API. Por que queremos considerar o primeiro design da API?
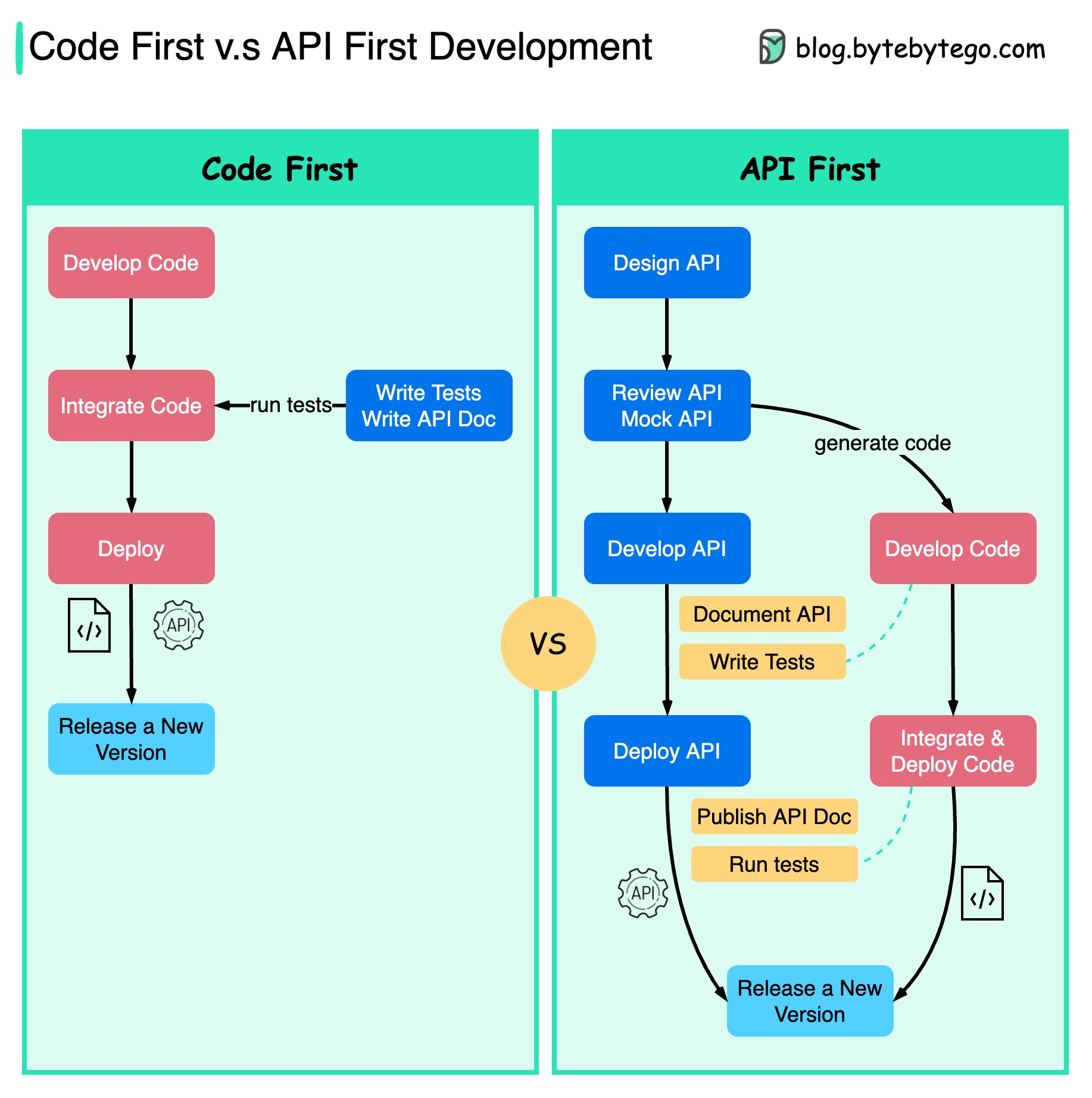
É melhor pensar na complexidade do sistema antes de escrever o código e definir cuidadosamente os limites dos serviços.
Podemos simular solicitações e respostas para validar o design da API antes de escrever o código.
Os desenvolvedores também estão satisfeitos com o processo porque podem se concentrar no desenvolvimento funcional em vez de negociar mudanças repentinas.
A possibilidade de surpresas no final do ciclo de vida do projeto é reduzida.
Como projetamos a API primeiro, os testes podem ser projetados enquanto o código está sendo desenvolvido. De certa forma, também temos TDD (Test Driven Design) ao usar o desenvolvimento inicial da API.
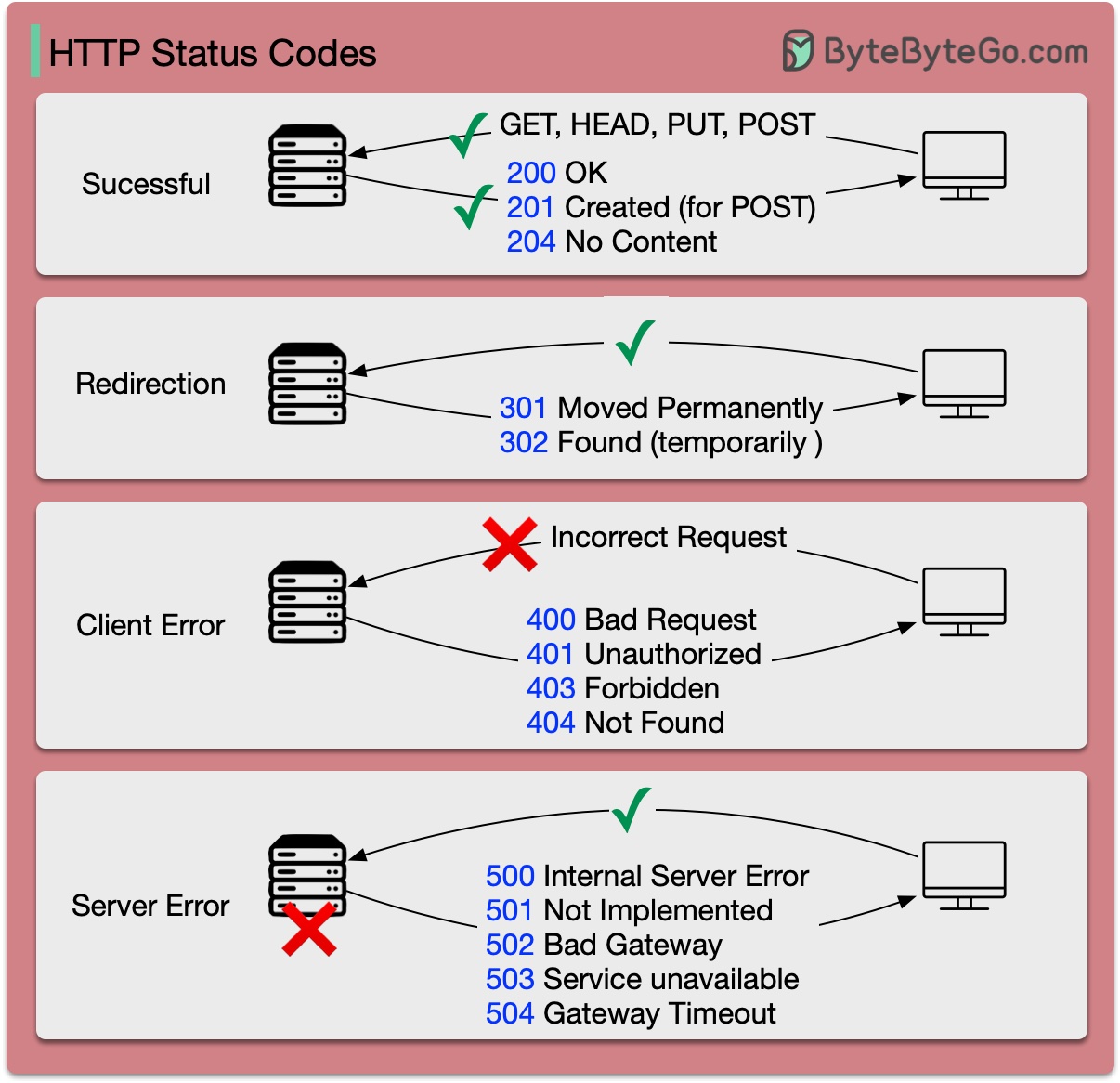
Os códigos de resposta para HTTP são divididos em cinco categorias:
Informativo (100-199) Sucesso (200-299) Redirecionamento (300-399) Erro do cliente (400-499) Erro do servidor (500-599)
O diagrama abaixo mostra os detalhes.
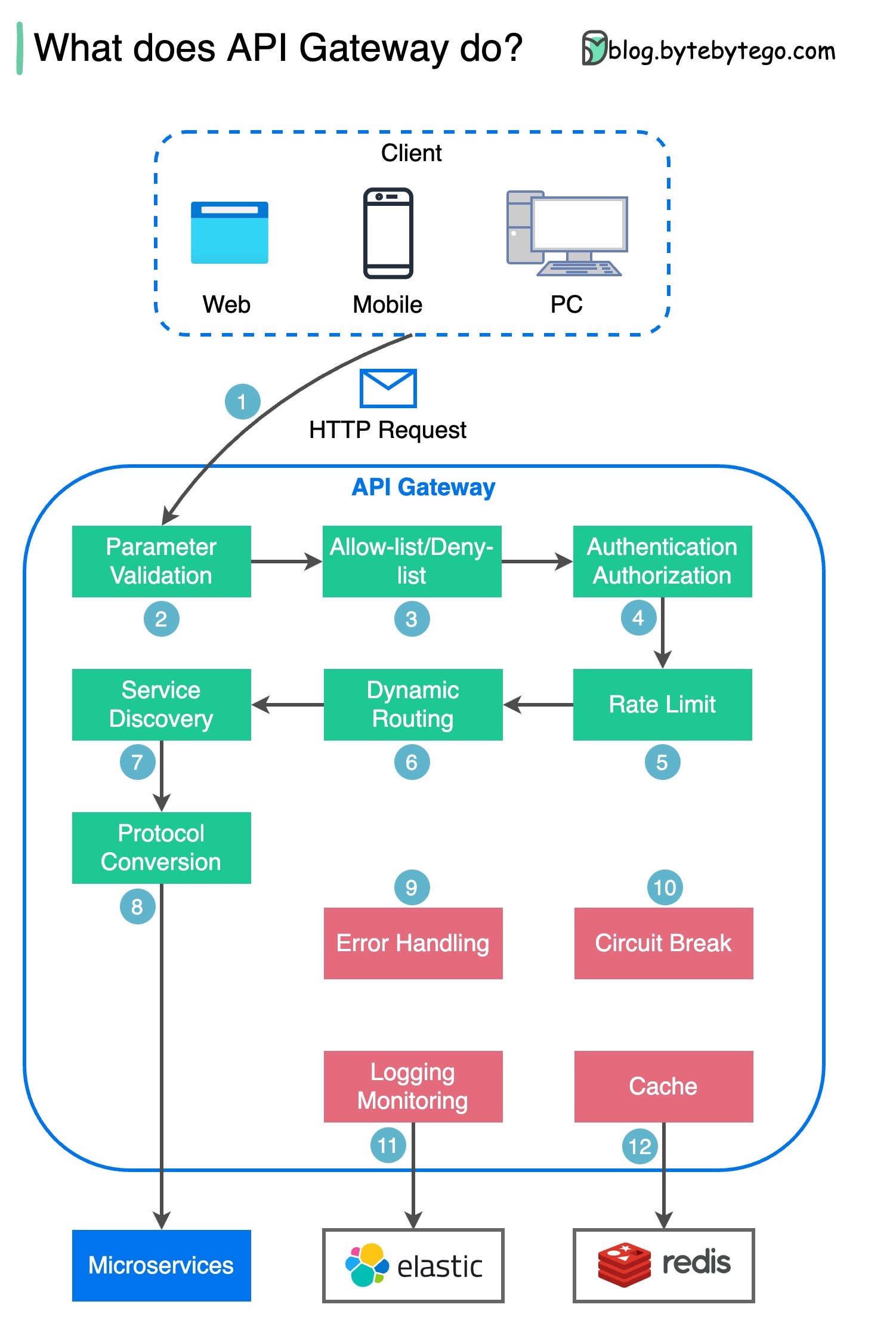
Etapa 1 – O cliente envia uma solicitação HTTP ao gateway de API.
Etapa 2 – O gateway de API analisa e valida os atributos na solicitação HTTP.
Etapa 3 - O gateway de API executa verificações de lista de permissões/lista de negações.
Etapa 4 – O gateway da API se comunica com um provedor de identidade para autenticação e autorização.
Passo 5 – As regras de limitação de taxa são aplicadas à solicitação. Se ultrapassar o limite, a solicitação será rejeitada.
Etapas 6 e 7 – Agora que a solicitação passou nas verificações básicas, o gateway de API encontra o serviço relevante para rotear por correspondência de caminho.
Etapa 8 – O gateway API transforma a solicitação no protocolo apropriado e a envia para microsserviços de backend.
Etapas 9 a 12: O gateway de API pode lidar com erros adequadamente e lidar com falhas se o erro demorar mais para ser recuperado (quebra de circuito). Ele também pode aproveitar a pilha ELK (Elastic-Logstash-Kibana) para registro e monitoramento. Às vezes, armazenamos dados em cache no gateway da API.
O diagrama abaixo mostra designs típicos de API com um exemplo de carrinho de compras.
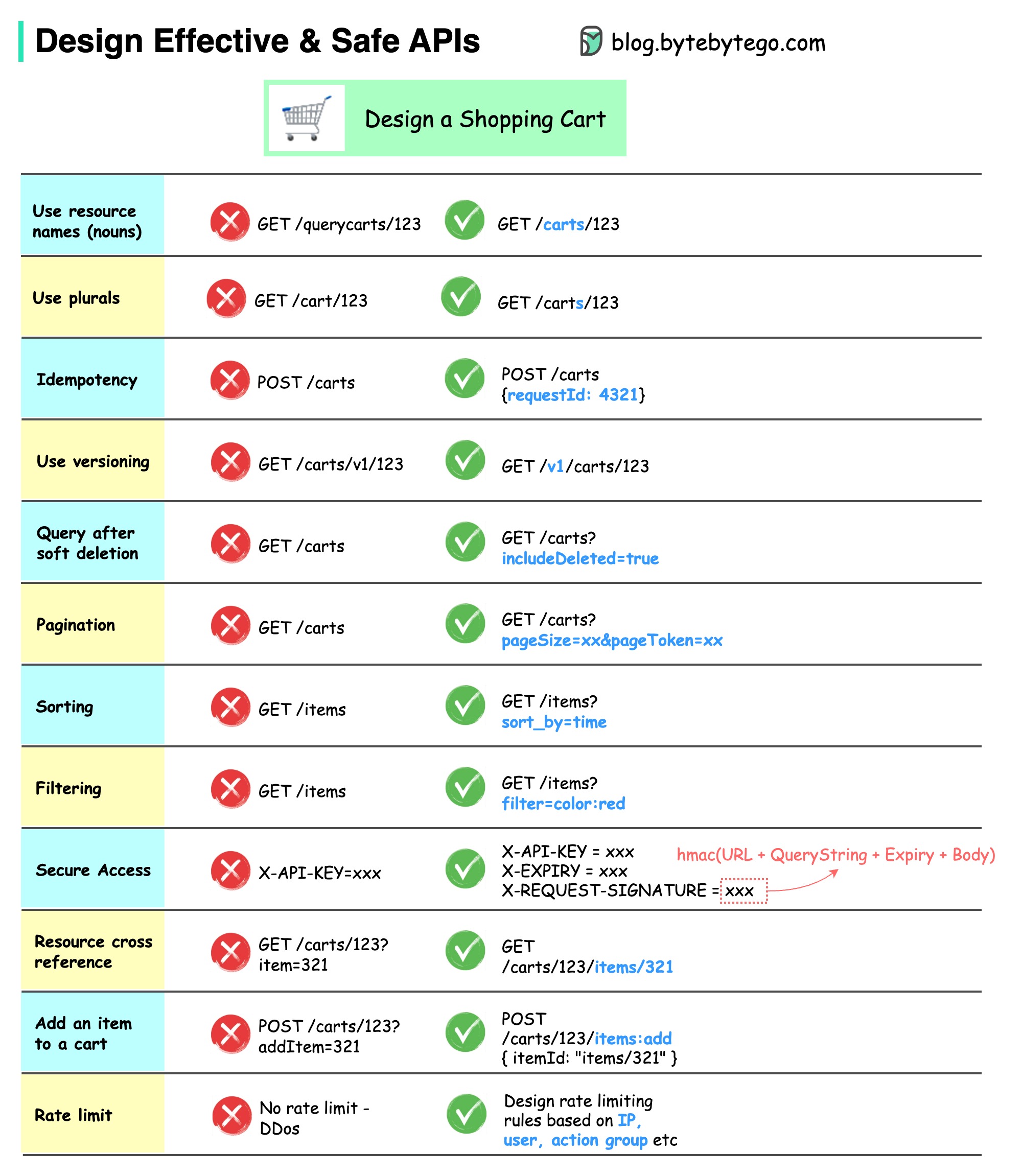
Observe que o design da API não é apenas o design do caminho da URL. Na maioria das vezes, precisamos escolher os nomes de recursos, identificadores e padrões de caminho adequados. É igualmente importante projetar campos de cabeçalho HTTP adequados ou criar regras eficazes de limitação de taxa no gateway da API.
Como os dados são enviados pela rede? Por que precisamos de tantas camadas no modelo OSI?
O diagrama abaixo mostra como os dados são encapsulados e desencapsulados durante a transmissão pela rede.
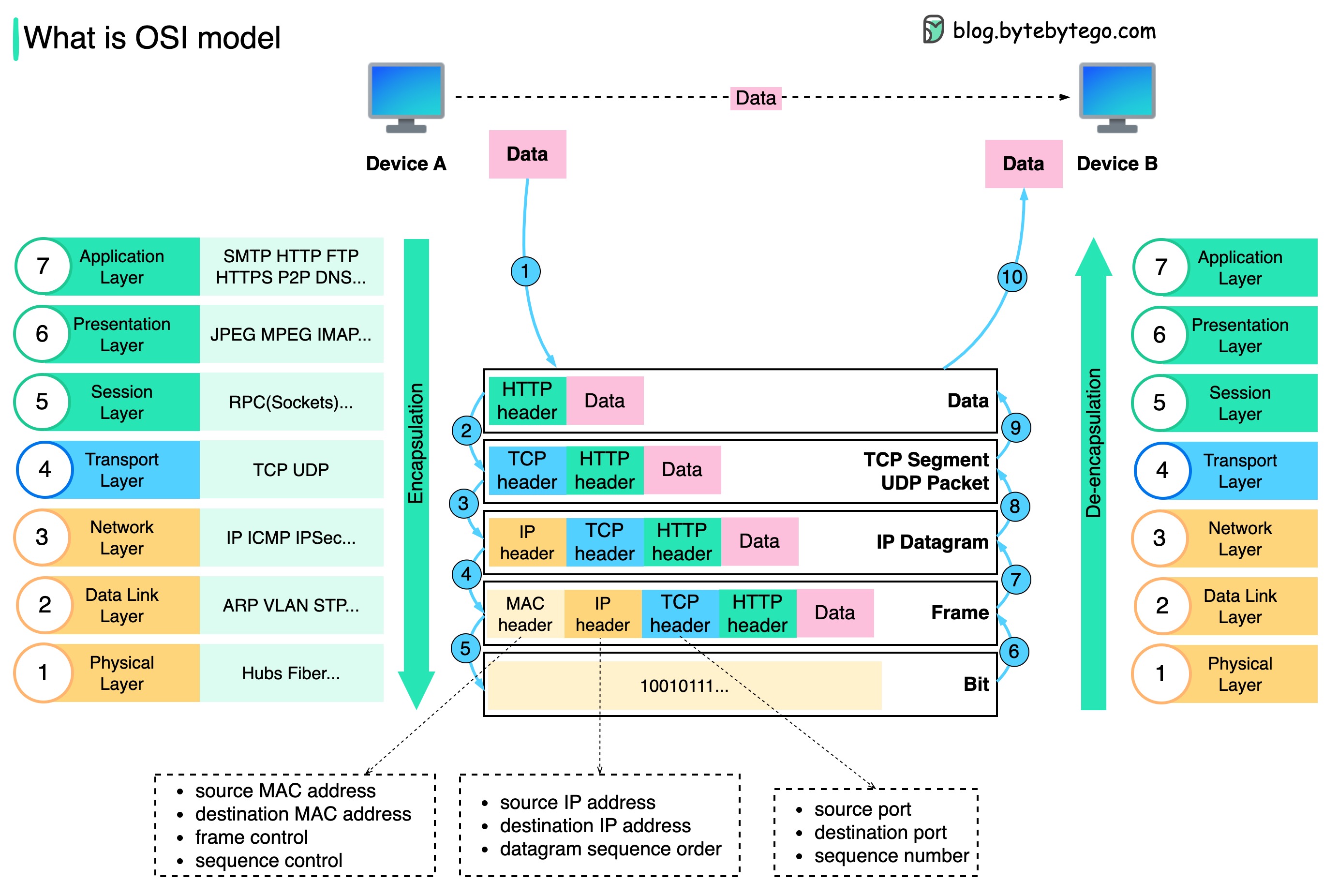
Etapa 1: quando o dispositivo A envia dados para o dispositivo B pela rede por meio do protocolo HTTP, primeiro é adicionado um cabeçalho HTTP na camada de aplicativo.
Etapa 2: Em seguida, um cabeçalho TCP ou UDP é adicionado aos dados. Ele é encapsulado em segmentos TCP na camada de transporte. O cabeçalho contém a porta de origem, a porta de destino e o número de sequência.
Etapa 3: Os segmentos são então encapsulados com um cabeçalho IP na camada de rede. O cabeçalho IP contém os endereços IP de origem/destino.
Etapa 4: O datagrama IP é adicionado a um cabeçalho MAC na camada de enlace de dados, com endereços MAC de origem/destino.
Etapa 5: Os quadros encapsulados são enviados para a camada física e enviados pela rede em bits binários.
Etapas 6 a 10: Quando o Dispositivo B recebe os bits da rede, ele executa o processo de desencapsulamento, que é um processamento reverso do processo de encapsulamento. Os cabeçalhos são removidos camada por camada e, eventualmente, o Dispositivo B pode ler os dados.
Precisamos de camadas no modelo de rede porque cada camada se concentra em suas próprias responsabilidades. Cada camada pode contar com os cabeçalhos para instruções de processamento e não precisa saber o significado dos dados da última camada.
O diagrama abaixo mostra as diferenças entre um ??????? ????? e um ??????? ?????.
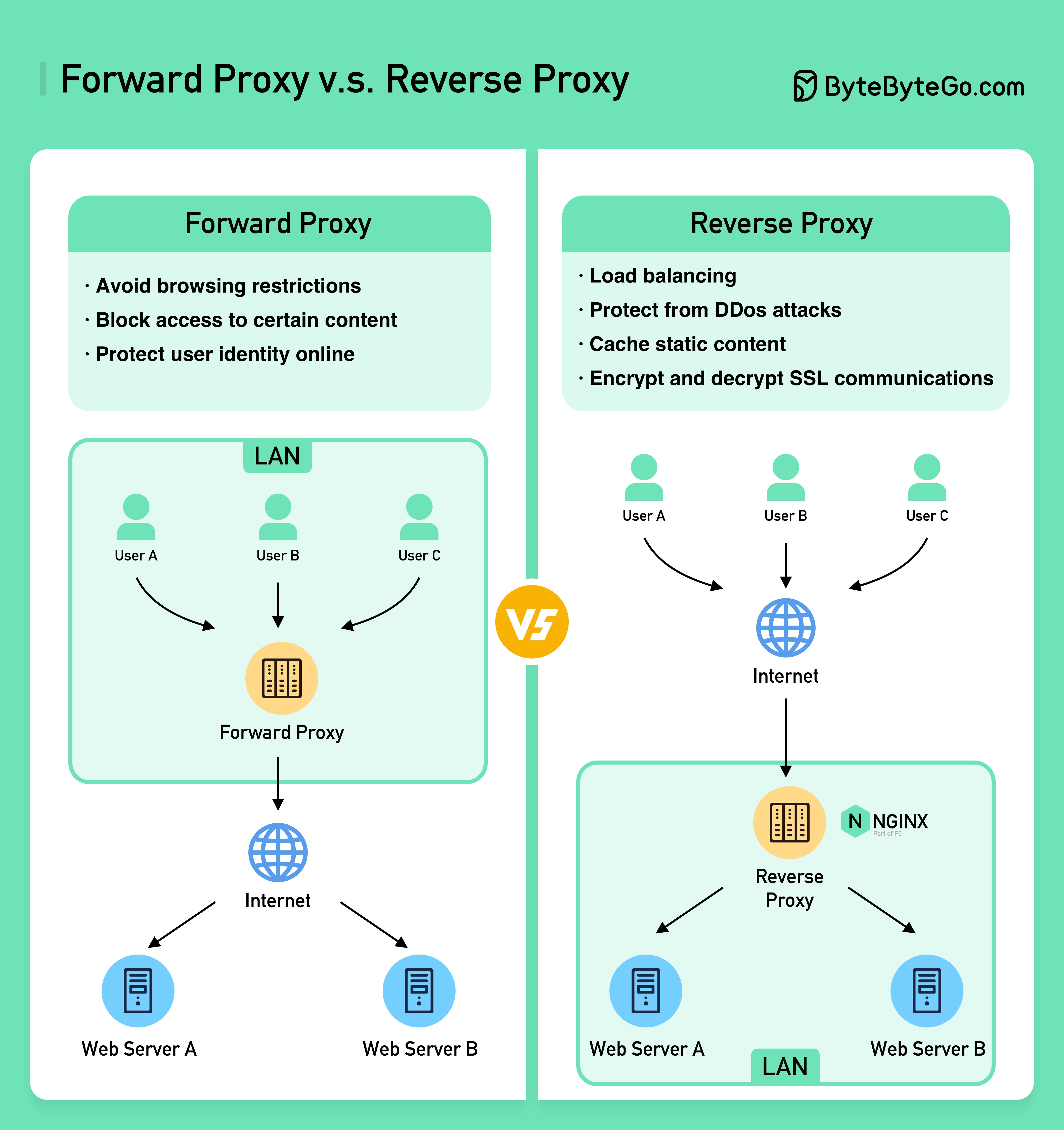
Um proxy de encaminhamento é um servidor localizado entre os dispositivos do usuário e a Internet.
Um proxy de encaminhamento é comumente usado para:
Um proxy reverso é um servidor que aceita uma solicitação do cliente, encaminha a solicitação para servidores web e retorna os resultados ao cliente como se o servidor proxy tivesse processado a solicitação.
Um proxy reverso é bom para:
O diagrama abaixo mostra 6 algoritmos comuns.
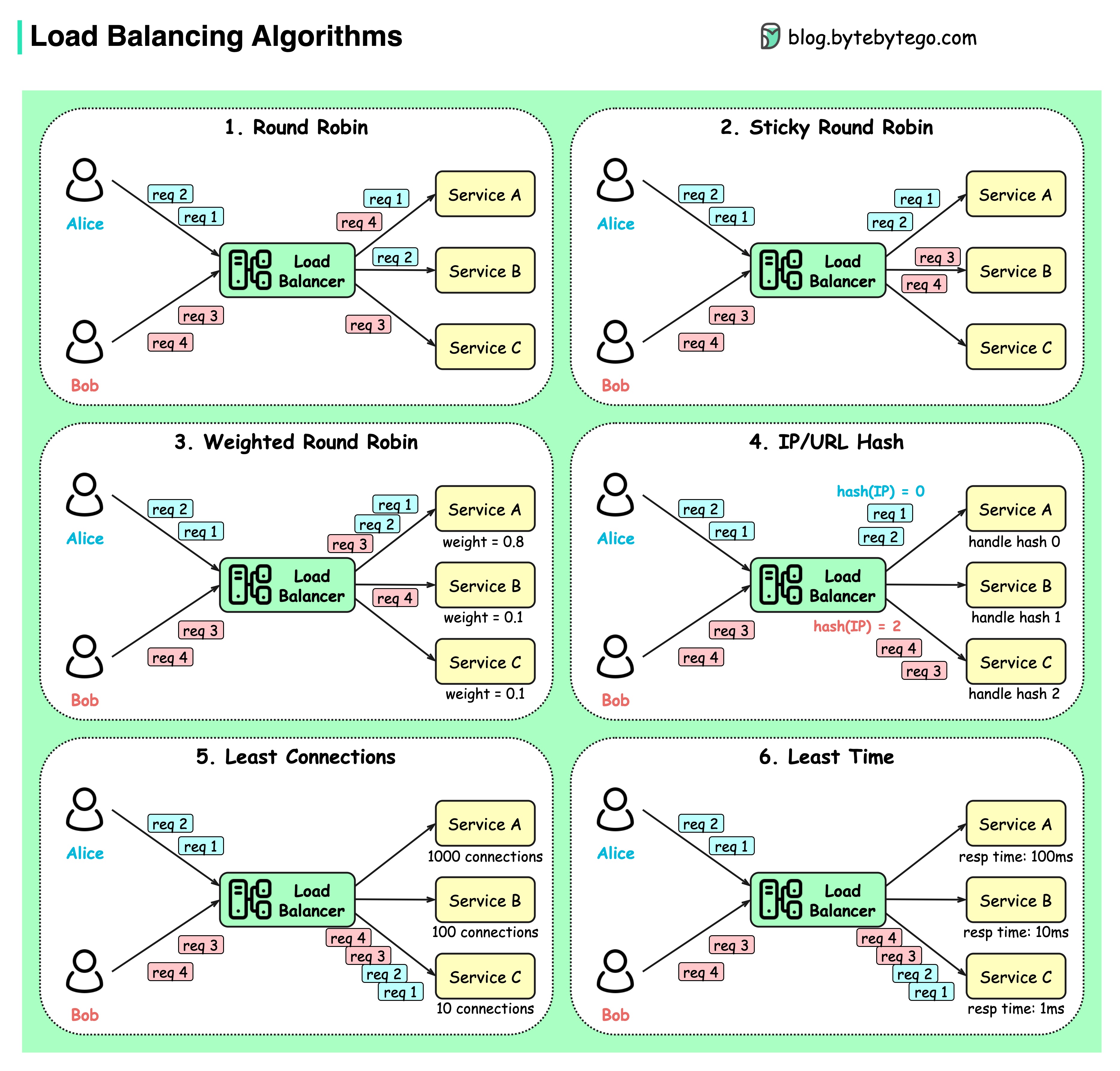
Rodada
As solicitações do cliente são enviadas para diferentes instâncias de serviço em ordem sequencial. Os serviços geralmente devem ser apátridas.
Rodada pegajosa
Esta é uma melhoria do algoritmo round-robin. Se a primeira solicitação de Alice for para o serviço A, as solicitações seguintes também irão para o serviço A.
Round-robin ponderado
O administrador pode especificar o peso de cada serviço. Aqueles com peso maior atendem mais solicitações do que outros.
Hash
Este algoritmo aplica uma função hash no IP ou URL das solicitações recebidas. As solicitações são roteadas para instâncias relevantes com base no resultado da função hash.
Menos conexões
Uma nova solicitação é enviada para a instância de serviço com menos conexões simultâneas.
Menor tempo de resposta
Uma nova solicitação é enviada à instância de serviço com o tempo de resposta mais rápido.
O diagrama abaixo mostra uma comparação de URL, URI e URN.
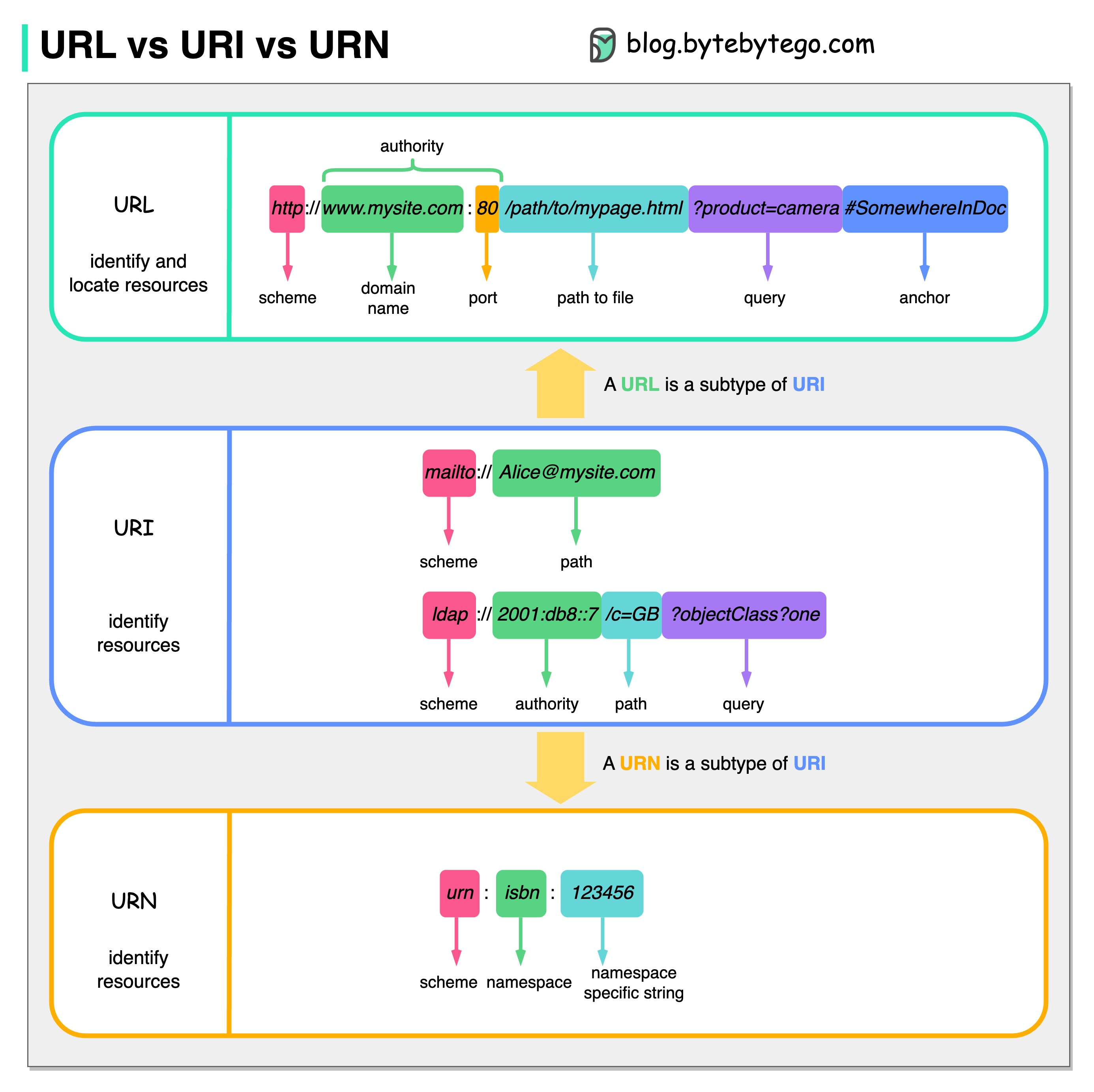
URI significa Identificador Uniforme de Recursos. Ele identifica um recurso lógico ou físico na web. URL e URN são subtipos de URI. URL localiza um recurso, enquanto URN nomeia um recurso.
Um URI é composto pelas seguintes partes: esquema:[//autoridade]caminho[?query][#fragment]
URL significa Uniform Resource Locator, o conceito-chave do HTTP. É o endereço de um recurso exclusivo na web. Pode ser usado com outros protocolos como FTP e JDBC.
URN significa Nome Uniforme de Recurso. Ele usa o esquema de urna. URNs não podem ser usados para localizar um recurso. Um exemplo simples dado no diagrama é composto por um namespace e uma string específica do namespace.
Se você quiser saber mais detalhes sobre o assunto, recomendo o esclarecimento do W3C.
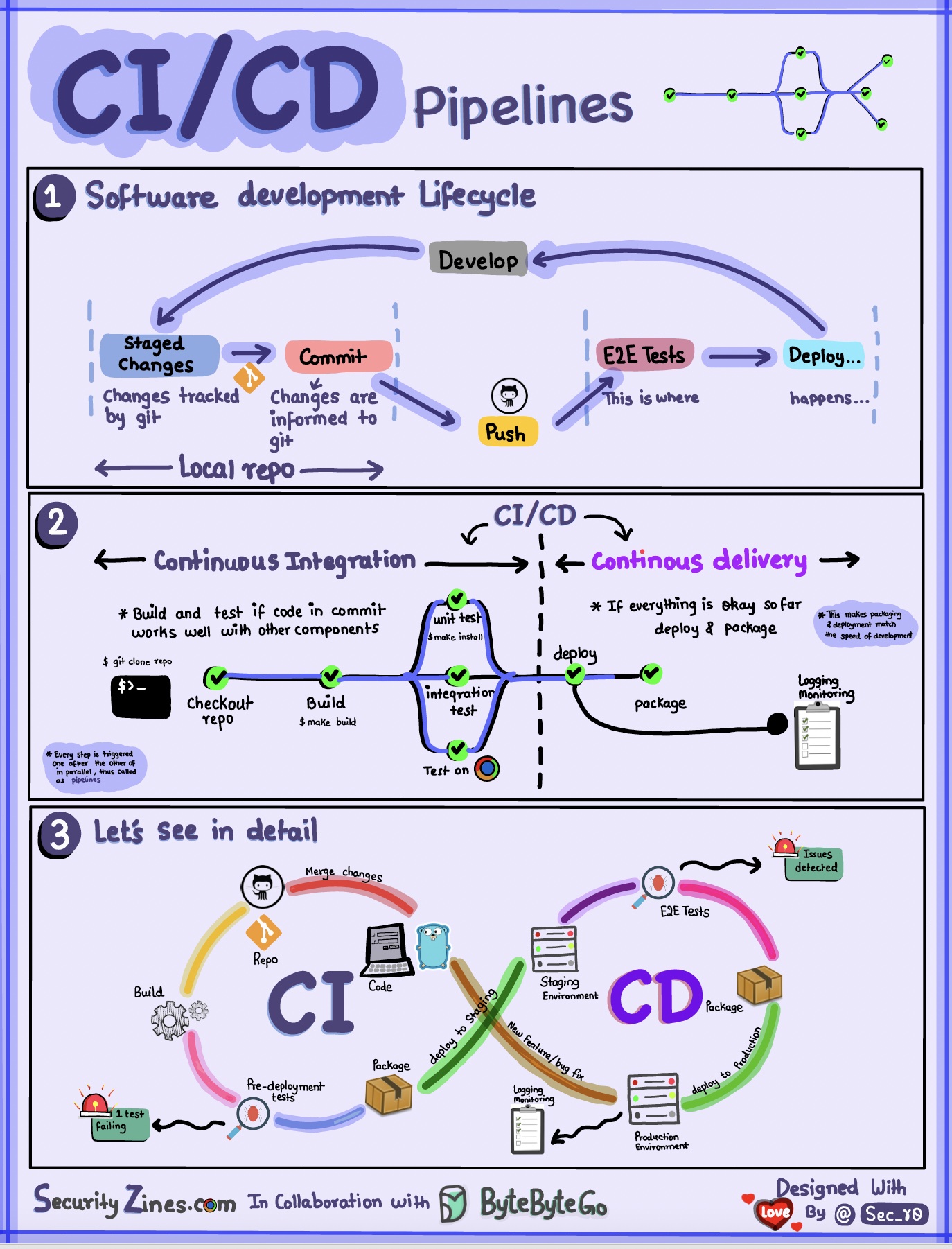
Seção 1 - SDLC com CI/CD
O ciclo de vida de desenvolvimento de software (SDLC) consiste em vários estágios principais: desenvolvimento, teste, implantação e manutenção. CI/CD automatiza e integra esses estágios para permitir lançamentos mais rápidos e confiáveis.
Quando o código é enviado para um repositório git, ele aciona um processo automatizado de construção e teste. Casos de teste ponta a ponta (e2e) são executados para validar o código. Se os testes forem aprovados, o código poderá ser implantado automaticamente na preparação/produção. Se forem encontrados problemas, o código será enviado de volta ao desenvolvimento para correção de bugs. Essa automação fornece feedback rápido aos desenvolvedores e reduz o risco de bugs na produção.
Seção 2 - Diferença entre CI e CD
A Integração Contínua (CI) automatiza o processo de construção, teste e mesclagem. Ele executa testes sempre que o código é confirmado para detectar problemas de integração antecipadamente. Isso incentiva commits frequentes de código e feedback rápido.
A Entrega Contínua (CD) automatiza processos de lançamento, como mudanças de infraestrutura e implantação. Ele garante que o software possa ser lançado de forma confiável a qualquer momento por meio de fluxos de trabalho automatizados. O CD também pode automatizar os testes manuais e as etapas de aprovação necessárias antes da implantação da produção.
Seção 3 - Pipeline CI/CD
Um pipeline de CI/CD típico tem vários estágios conectados:
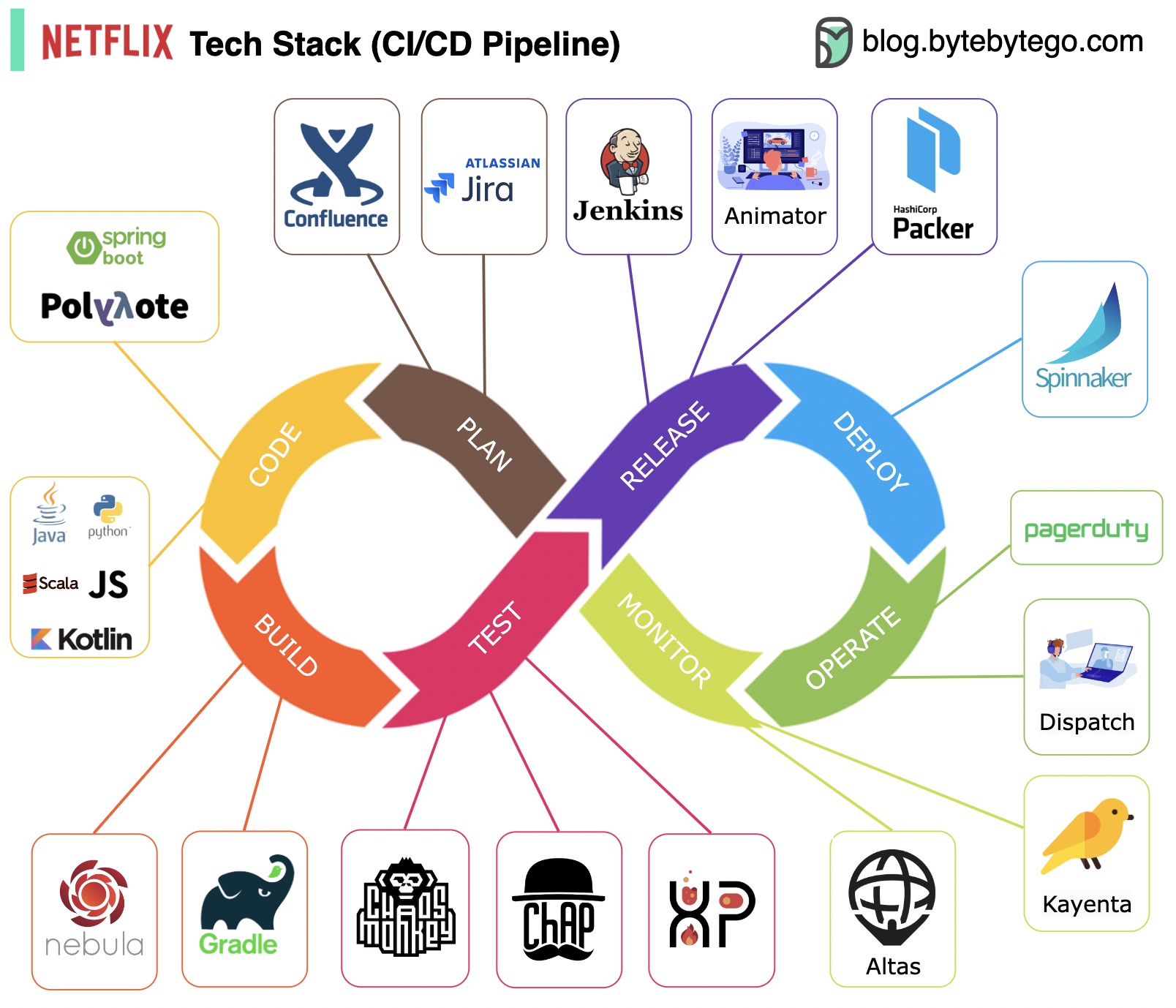
Planejamento: a Netflix Engineering usa JIRA para planejamento e Confluence para documentação.
Codificação: Java é a principal linguagem de programação para o serviço de back-end, enquanto outras linguagens são usadas para diferentes casos de uso.
Build: Gradle é usado principalmente para construção, e os plug-ins do Gradle são criados para oferecer suporte a vários casos de uso.
Pacote: o pacote e as dependências são compactados em uma Amazon Machine Image (AMI) para lançamento.
Teste: O teste enfatiza o foco da cultura de produção na construção de ferramentas para o caos.
Implantação: a Netflix usa seu Spinnaker autoconstruído para implantação canário.
Monitoramento: As métricas de monitoramento são centralizadas no Atlas e o Kayenta é usado para detectar anomalias.
Relatório de incidentes: os incidentes são despachados de acordo com a prioridade e o PagerDuty é usado para tratamento de incidentes.
Esses padrões de arquitetura estão entre os mais utilizados no desenvolvimento de aplicativos, seja em plataformas iOS ou Android. Os desenvolvedores os introduziram para superar as limitações dos padrões anteriores. Então, como eles diferem?
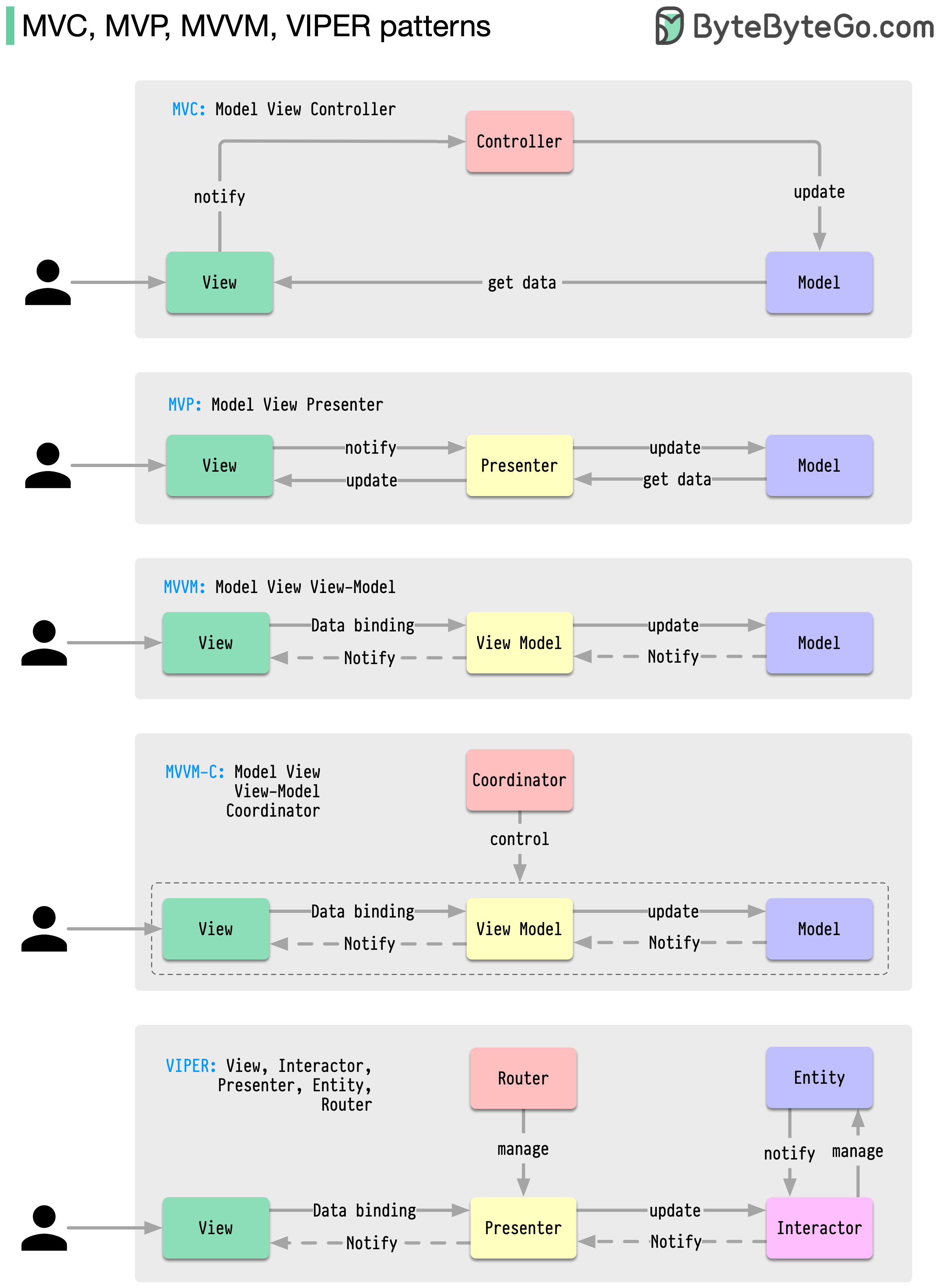
Os padrões são soluções reutilizáveis para problemas comuns de design, resultando em um processo de desenvolvimento mais suave e eficiente. Eles servem como modelo para a construção de melhores estruturas de software. Estes são alguns dos padrões mais populares:

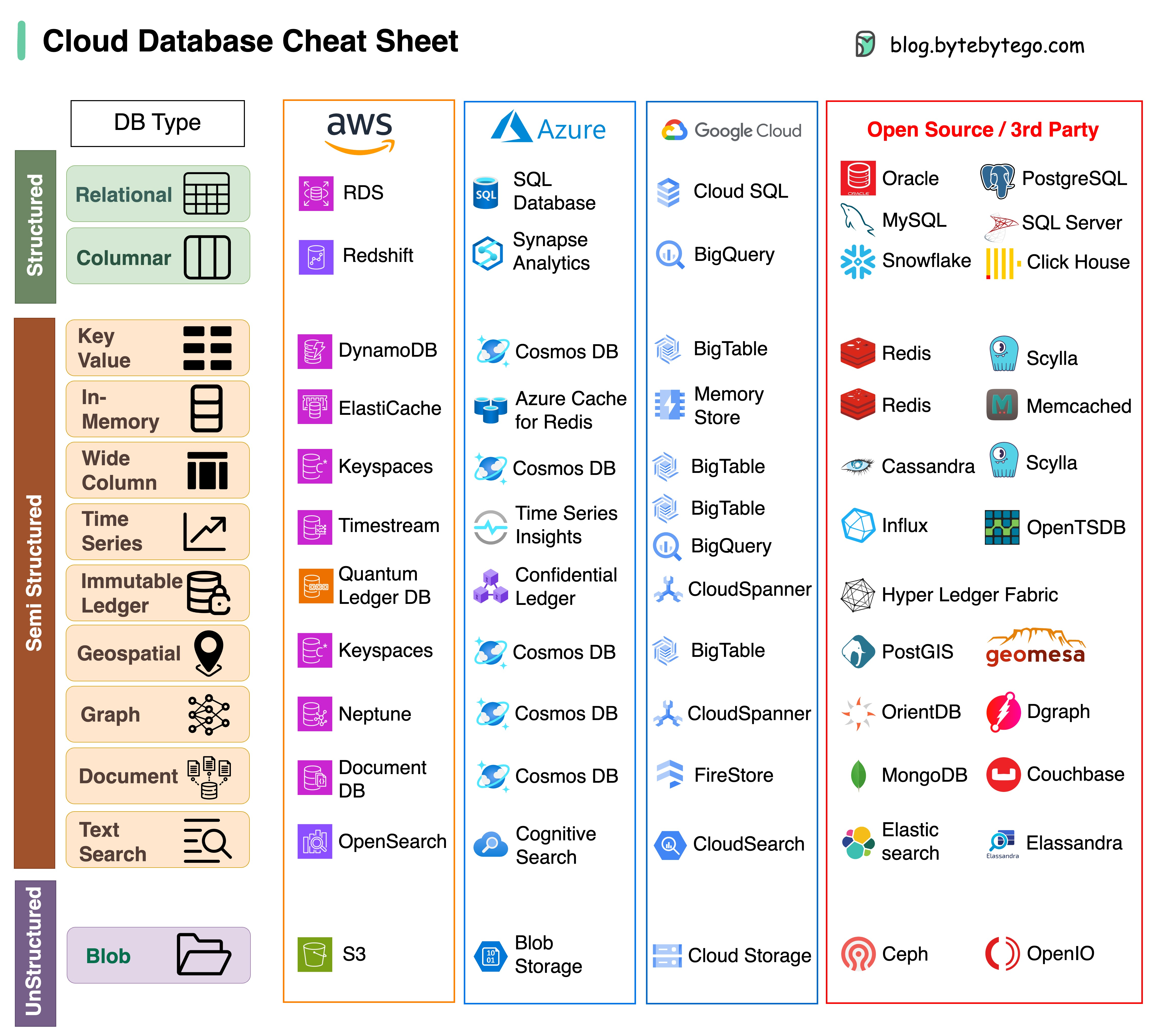
Escolher o banco de dados certo para o seu projeto é uma tarefa complexa. Muitas opções de banco de dados, cada uma adequada para casos de uso distintos, podem levar rapidamente ao cansaço das decisões.
Esperamos que esta folha de dicas forneça orientações de alto nível para identificar o serviço certo que se alinha às necessidades do seu projeto e evitar possíveis armadilhas.
Observação: o Google possui documentação limitada para seus casos de uso de banco de dados. Embora tenhamos feito o possível para ver o que estava disponível e chegado à melhor opção, algumas das entradas podem precisar ser mais precisas.
A resposta irá variar dependendo do seu caso de uso. Os dados podem ser indexados na memória ou no disco. Da mesma forma, os formatos de dados variam, como números, strings, coordenadas geográficas, etc. O sistema pode ter muita gravação ou leitura. Todos esses fatores afetam a escolha do formato de índice do banco de dados.
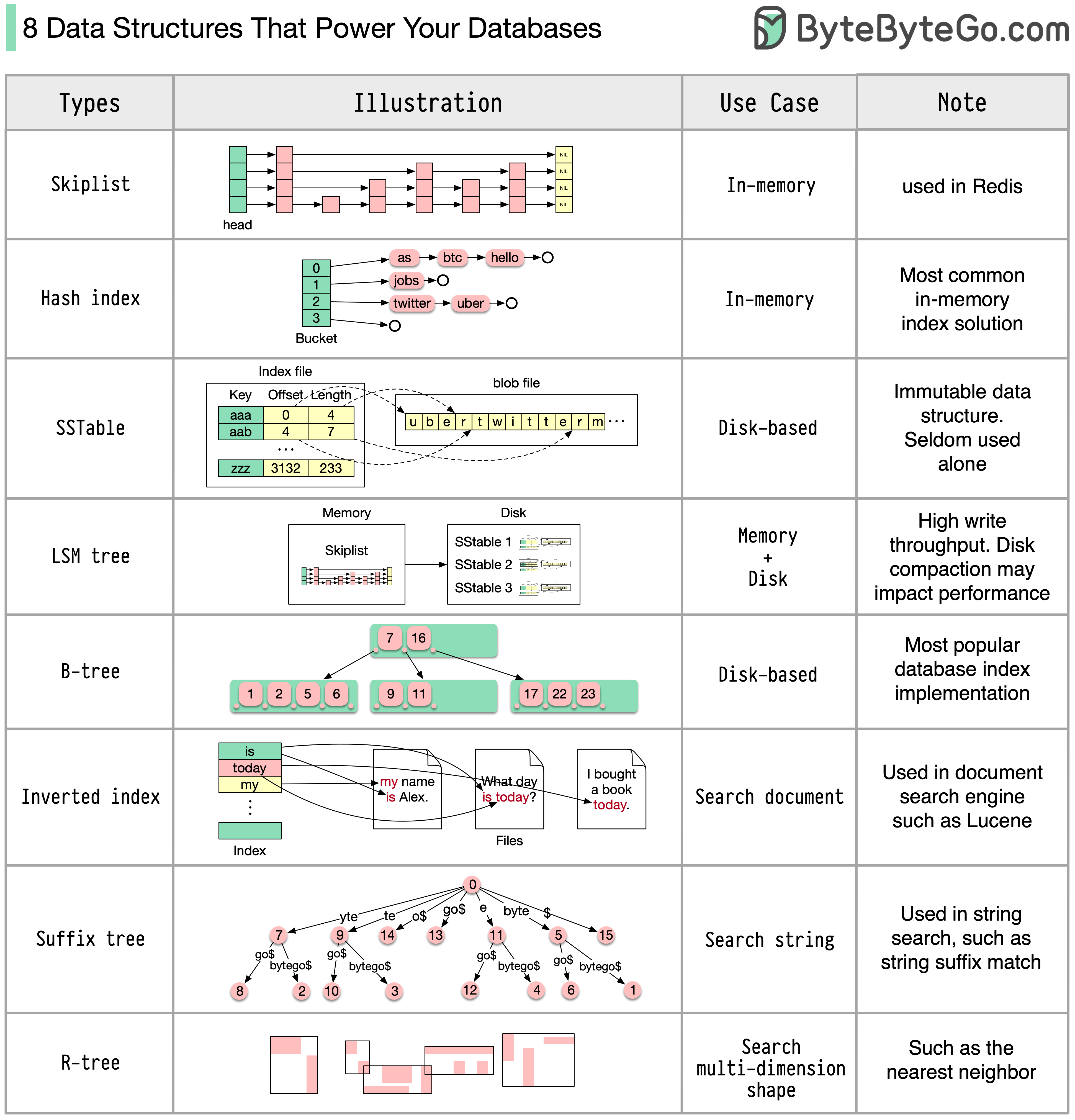
A seguir estão algumas das estruturas de dados mais populares usadas para indexação de dados:
O diagrama abaixo mostra o processo. Observe que as arquiteturas para diferentes bancos de dados são diferentes. O diagrama demonstra alguns designs comuns.
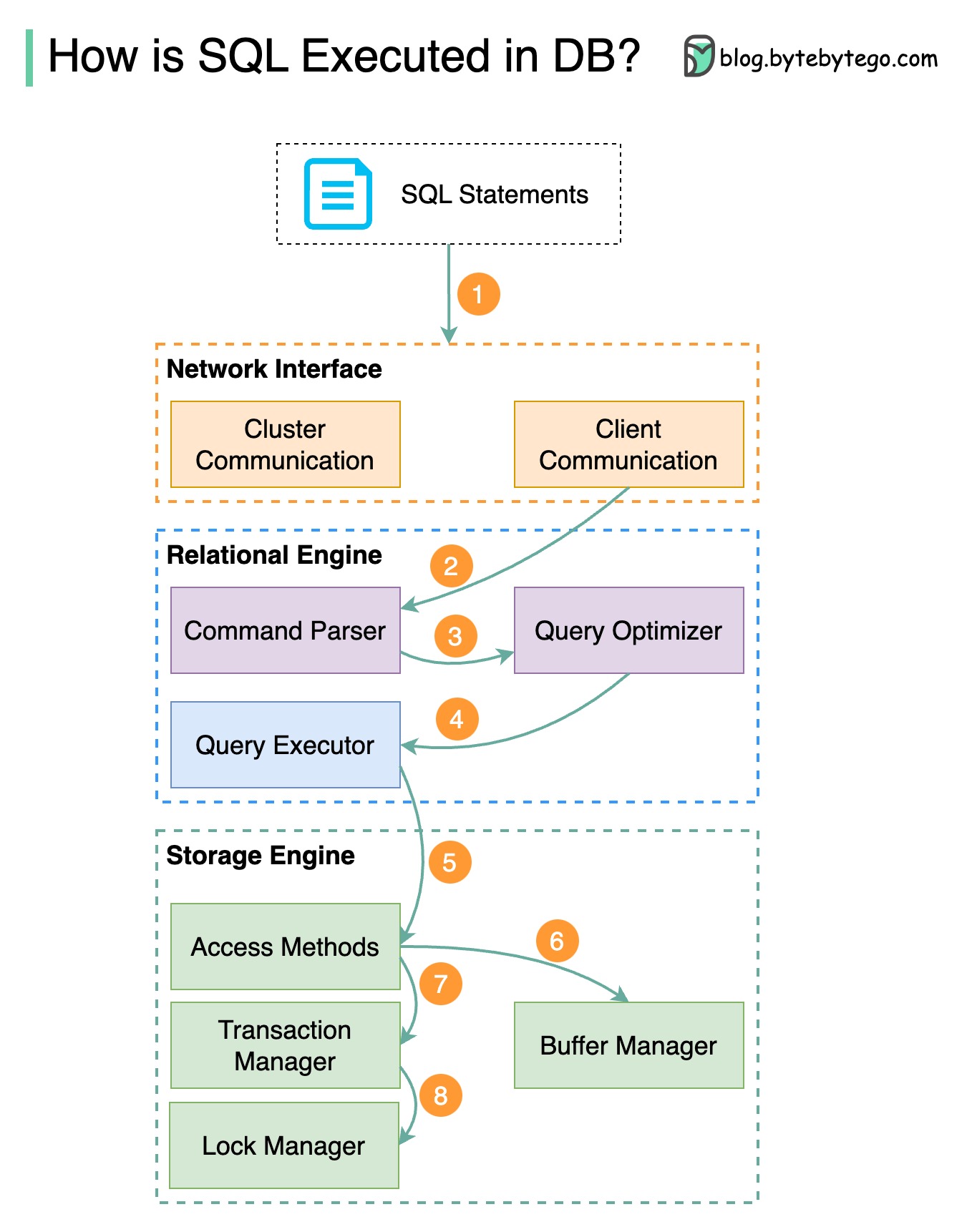
Passo 1 - Uma instrução SQL é enviada ao banco de dados através de um protocolo de camada de transporte (por exemplo, TCP).
Passo 2 - A instrução SQL é enviada ao analisador de comandos, onde passa por análise sintática e semântica, e posteriormente é gerada uma árvore de consulta.
Passo 3 – A árvore de consulta é enviada ao otimizador. O otimizador cria um plano de execução.
Passo 4 – O plano de execução é enviado ao executor. O executor recupera dados da execução.
Passo 5 - Os métodos de acesso fornecem a lógica de busca de dados necessária para a execução, recuperando os dados do mecanismo de armazenamento.
Etapa 6 – Os métodos de acesso decidem se a instrução SQL é somente leitura. Se a consulta for somente leitura (instrução SELECT), ela será passada ao gerenciador de buffer para processamento adicional. O gerenciador de buffer procura os dados no cache ou nos arquivos de dados.
Etapa 7 - Se a instrução for UPDATE ou INSERT, ela será passada ao gerenciador de transações para processamento posterior.
Passo 8 – Durante uma transação, os dados ficam em modo de bloqueio. Isso é garantido pelo gerenciador de bloqueios. Também garante as propriedades ACID da transação.
O teorema CAP é um dos termos mais famosos da ciência da computação, mas aposto que diferentes desenvolvedores têm entendimentos diferentes. Vamos examinar o que é e por que pode ser confuso.
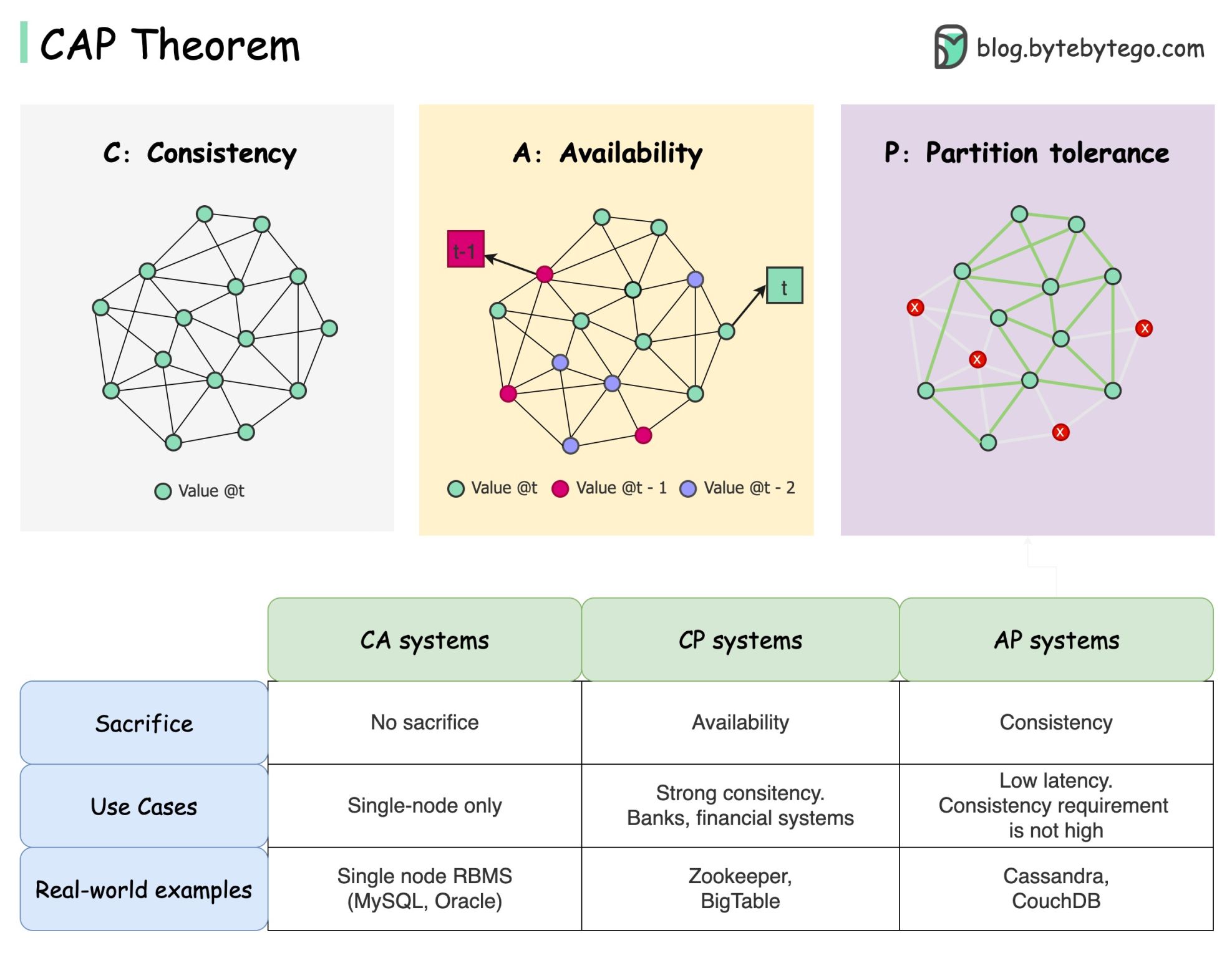
O teorema CAP afirma que um sistema distribuído não pode fornecer mais do que duas destas três garantias simultaneamente.
Consistência : consistência significa que todos os clientes veem os mesmos dados ao mesmo tempo, independentemente do nó ao qual se conectam.
Disponibilidade : disponibilidade significa que qualquer cliente que solicite dados obtém uma resposta mesmo se alguns dos nós estiverem inativos.
Tolerância de partição : uma partição indica uma quebra de comunicação entre dois nós. Tolerância de partição significa que o sistema continua a operar apesar das partições de rede.
A formulação “2 de 3” pode ser útil, mas esta simplificação pode ser enganosa .
Escolher um banco de dados não é fácil. Justificar a nossa escolha puramente com base no teorema CAP não é suficiente. Por exemplo, as empresas não escolhem o Cassandra para aplicativos de chat simplesmente porque é um sistema AP. Existe uma lista de boas características que tornam o Cassandra uma opção desejável para armazenar mensagens de chat. Precisamos cavar mais fundo.
“O CAP proíbe apenas uma pequena parte do espaço de design: perfeita disponibilidade e consistência na presença de divisórias, que são raras”. Citado no artigo: CAP Doze anos depois: como as “regras” mudaram.
O teorema é cerca de 100% de disponibilidade e consistência. Uma discussão mais realista seria a compensação entre latência e consistência quando não há partição de rede. Veja o teorema PACELC para mais detalhes.
O teorema CAP é realmente útil?
Penso que ainda é útil, pois abre as nossas mentes para uma série de discussões sobre compromissos, mas é apenas parte da história. Precisamos nos aprofundar ao escolher o banco de dados certo.
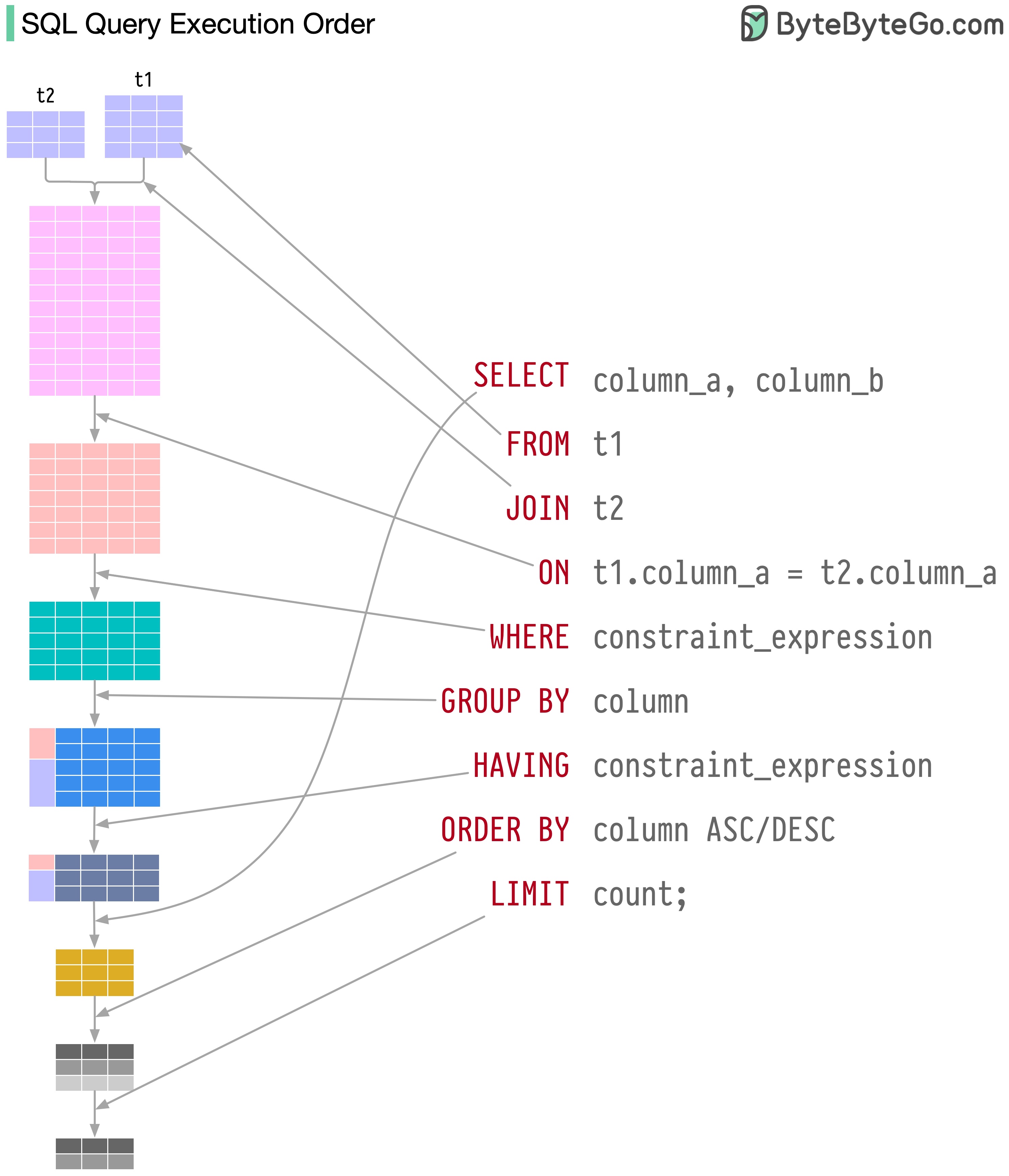
As instruções SQL são executadas pelo sistema de banco de dados em diversas etapas, incluindo:
A execução do SQL é altamente complexa e envolve muitas considerações, como:
Em 1986, SQL (Structured Query Language) tornou-se um padrão. Nos 40 anos seguintes, tornou-se a linguagem dominante para sistemas de gerenciamento de banco de dados relacionais. A leitura do padrão mais recente (ANSI SQL 2016) pode ser demorada. Como posso aprender isso?
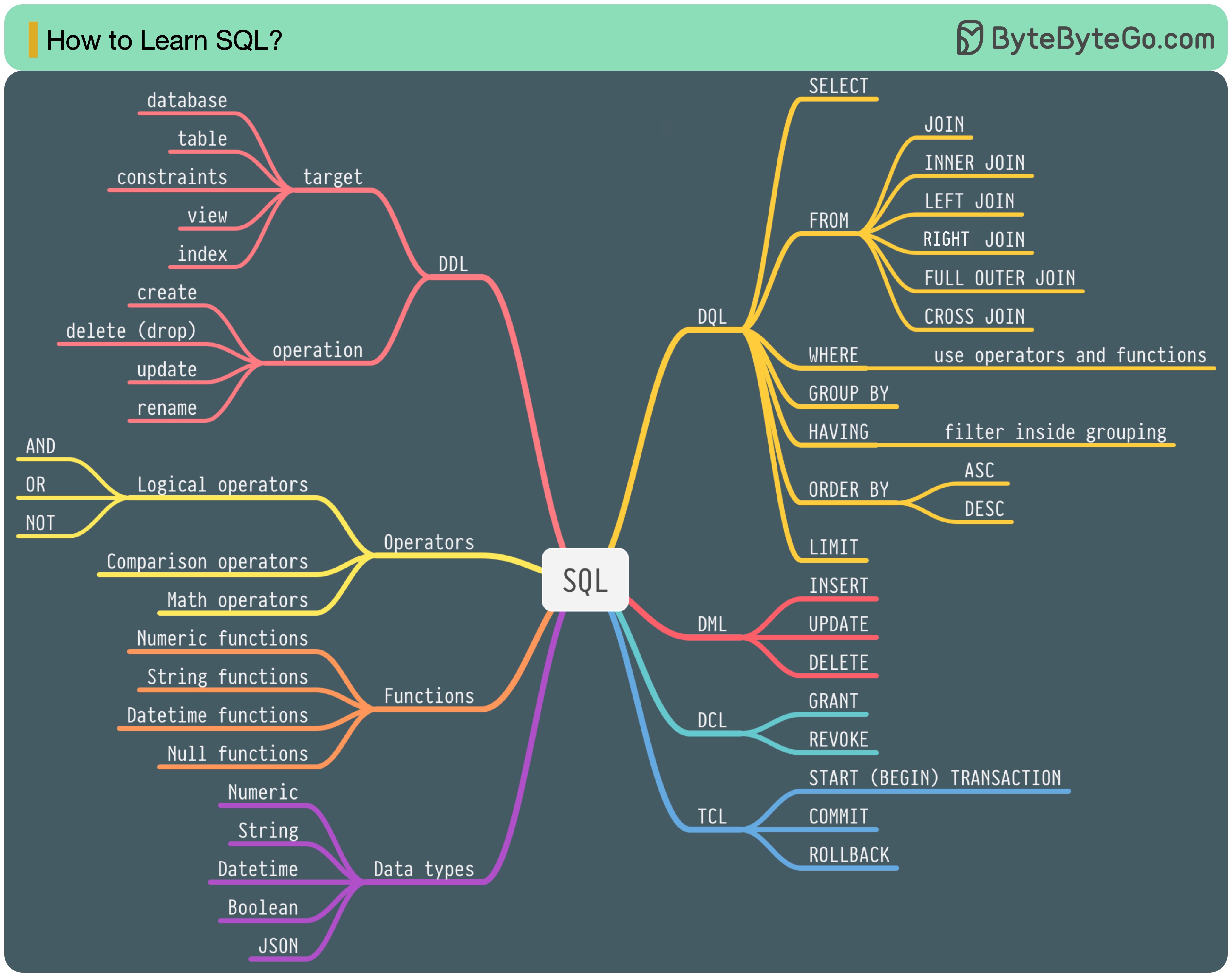
Existem 5 componentes da linguagem SQL:
Para um engenheiro de back-end, talvez você precise saber a maior parte. Como analista de dados, talvez você precise ter um bom conhecimento de DQL. Selecione os tópicos que são mais relevantes para você.
Este diagrama ilustra onde armazenamos dados em cache em uma arquitetura típica.
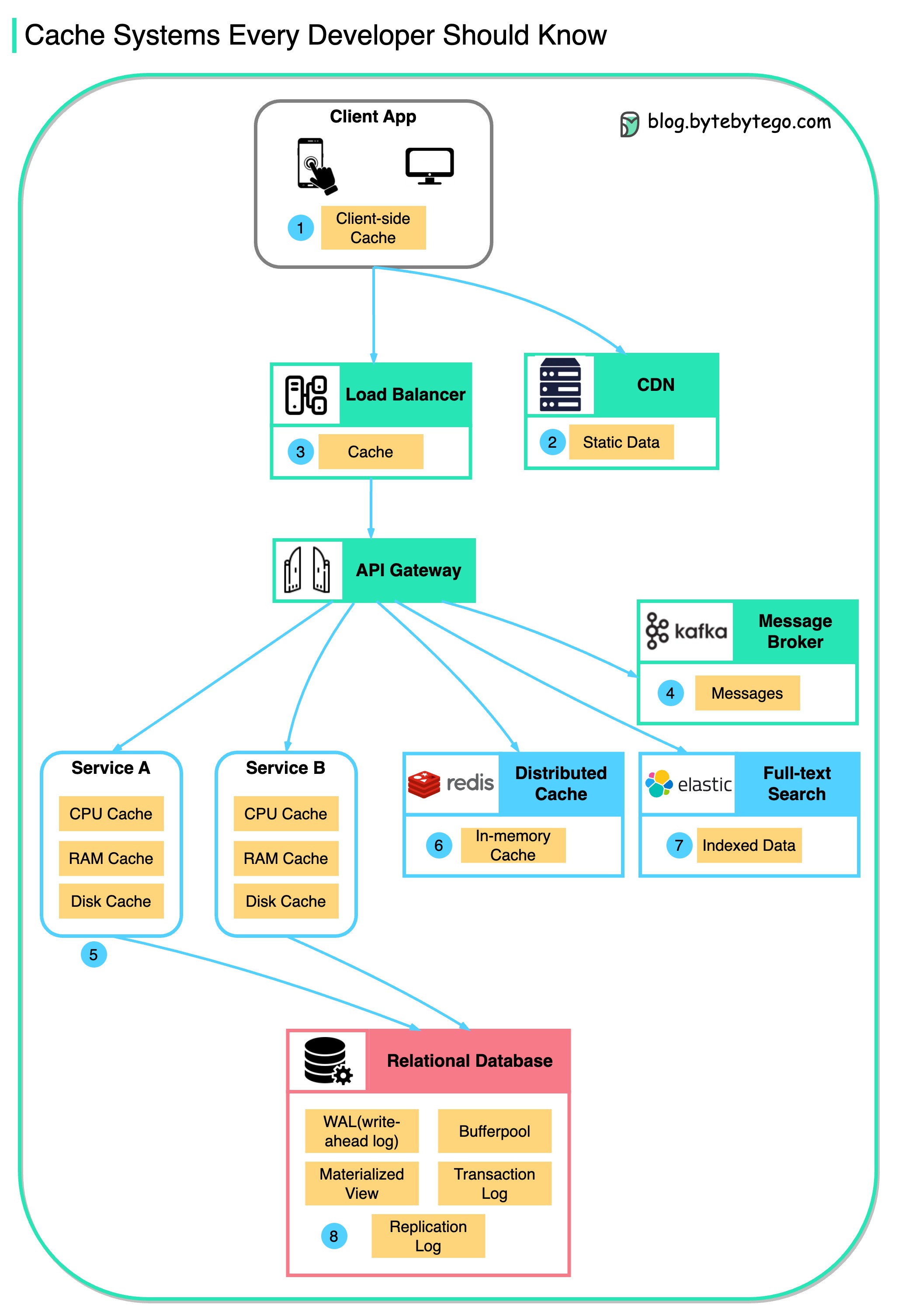
Existem várias camadas ao longo do fluxo.
Existem 3 razões principais, conforme mostrado no diagrama abaixo.
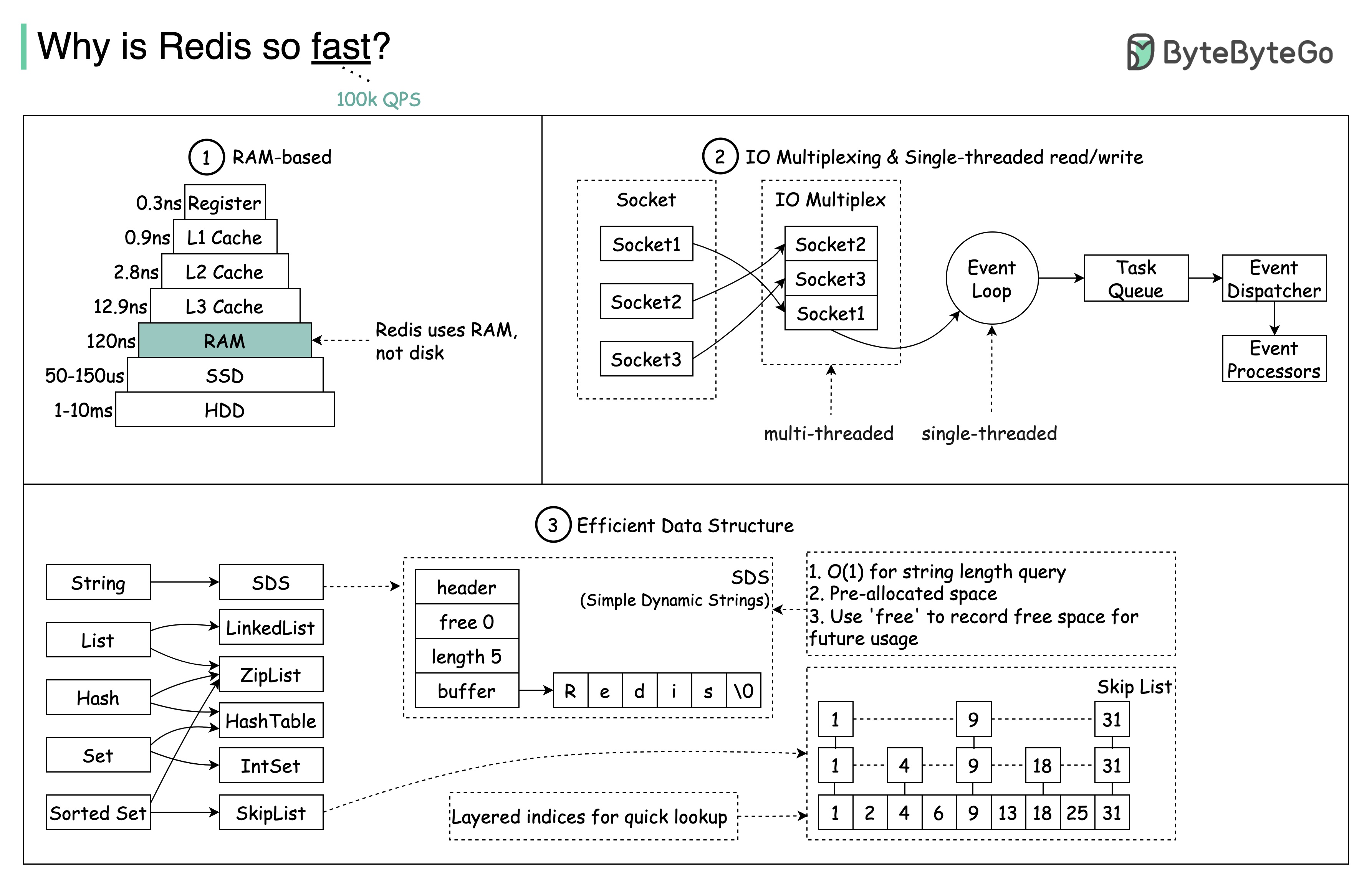
Pergunta: Outro armazenamento popular na memória é o Memcached. Você conhece as diferenças entre Redis e Memcached?
Você deve ter notado que o estilo deste diagrama é diferente das minhas postagens anteriores. Por favor, deixe -me saber qual você prefere.
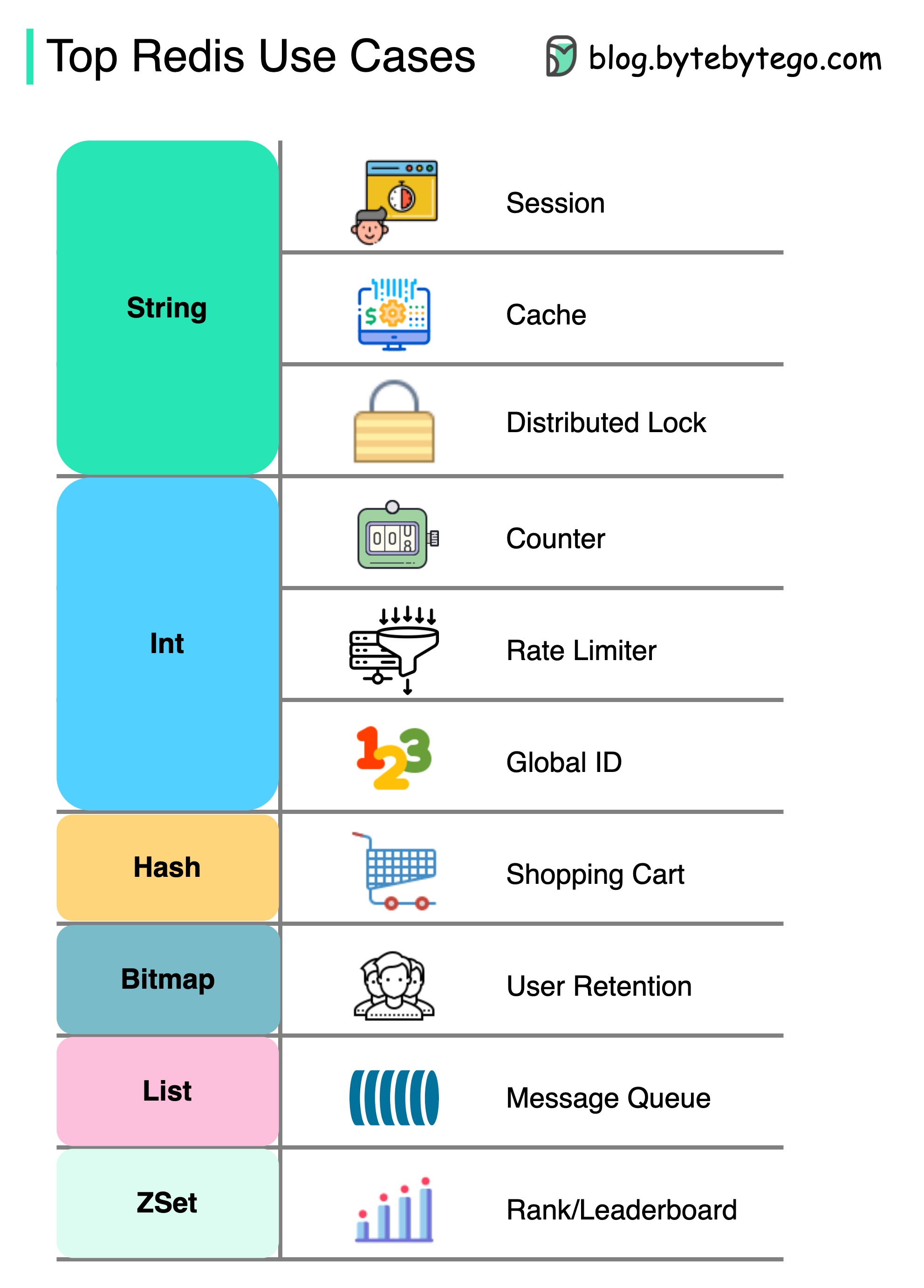
Há mais em redis do que apenas em cache.
Redis pode ser usado em vários cenários, como mostrado no diagrama.
Sessão
Podemos usar o Redis para compartilhar dados da sessão do usuário entre diferentes serviços.
Cache
Podemos usar o Redis para armazenar em cache objetos ou páginas, especialmente para dados do ponto de acesso.
Bloqueio distribuído
Podemos usar uma sequência Redis para adquirir bloqueios entre serviços distribuídos.
Contador
Podemos contar quantos gostos ou quantas leituras para artigos.
Limitador de taxa
Podemos aplicar um limitador de taxa para determinados IPs do usuário.
Gerador de ID global
Podemos usar o Redis Int para ID global.
Carrinho de compras
Podemos usar o Hash Redis para representar pares de valores-chave em um carrinho de compras.
Calcule a retenção de usuários
Podemos usar o bitmap para representar o login do usuário diariamente e calcular a retenção de usuários.
Fila de mensagens
Podemos usar a lista para uma fila de mensagens.
Classificação
Podemos usar o Zset para classificar os artigos.
Projetar sistemas em larga escala geralmente requer consideração cuidadosa do cache. Abaixo estão cinco estratégias de cache que são frequentemente utilizadas.
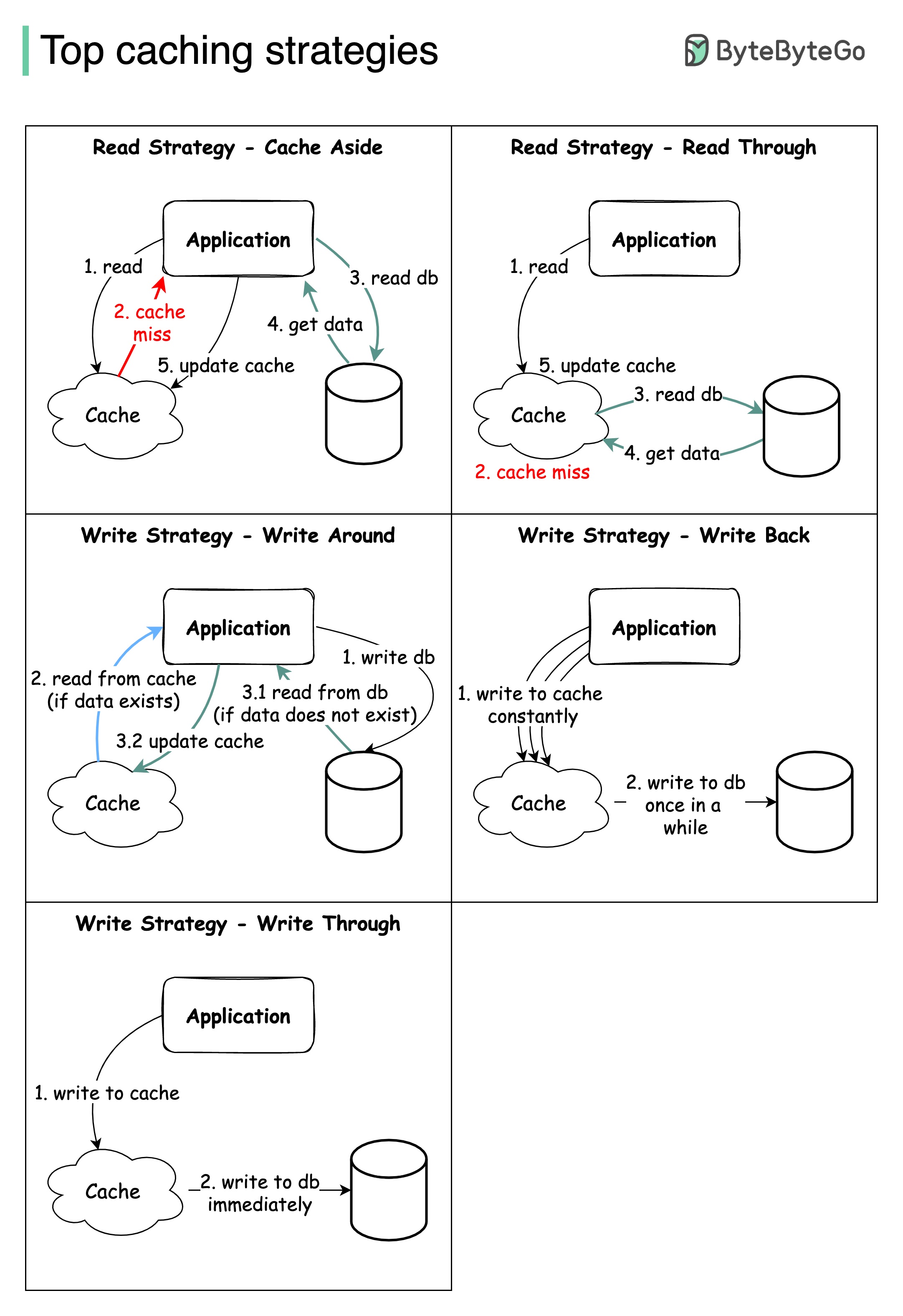
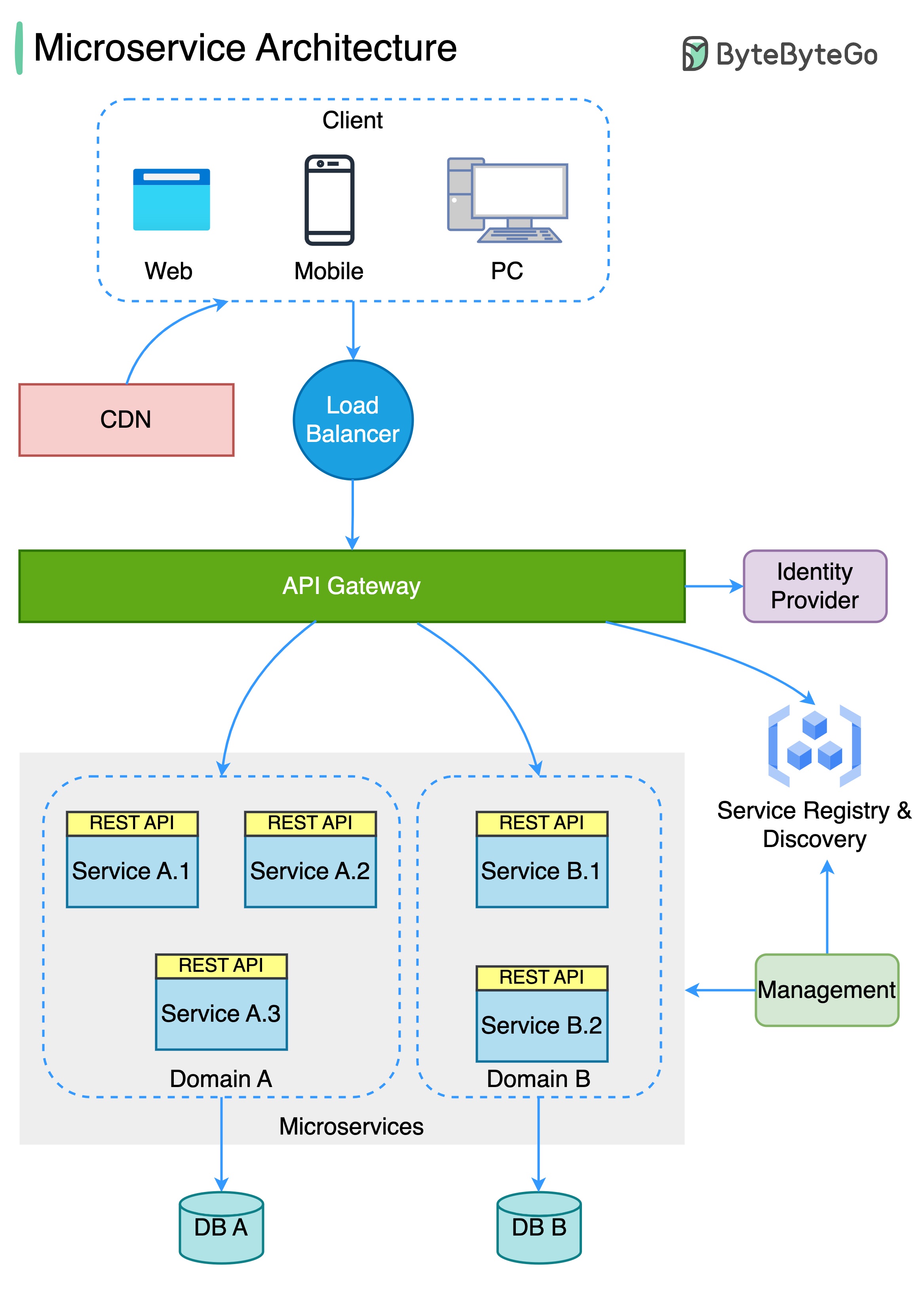
O diagrama abaixo mostra uma arquitetura de microsserviço típica.
Benefícios dos microsserviços:
Uma imagem vale mais que mil palavras: 9 práticas recomendadas para o desenvolvimento de microsserviços.
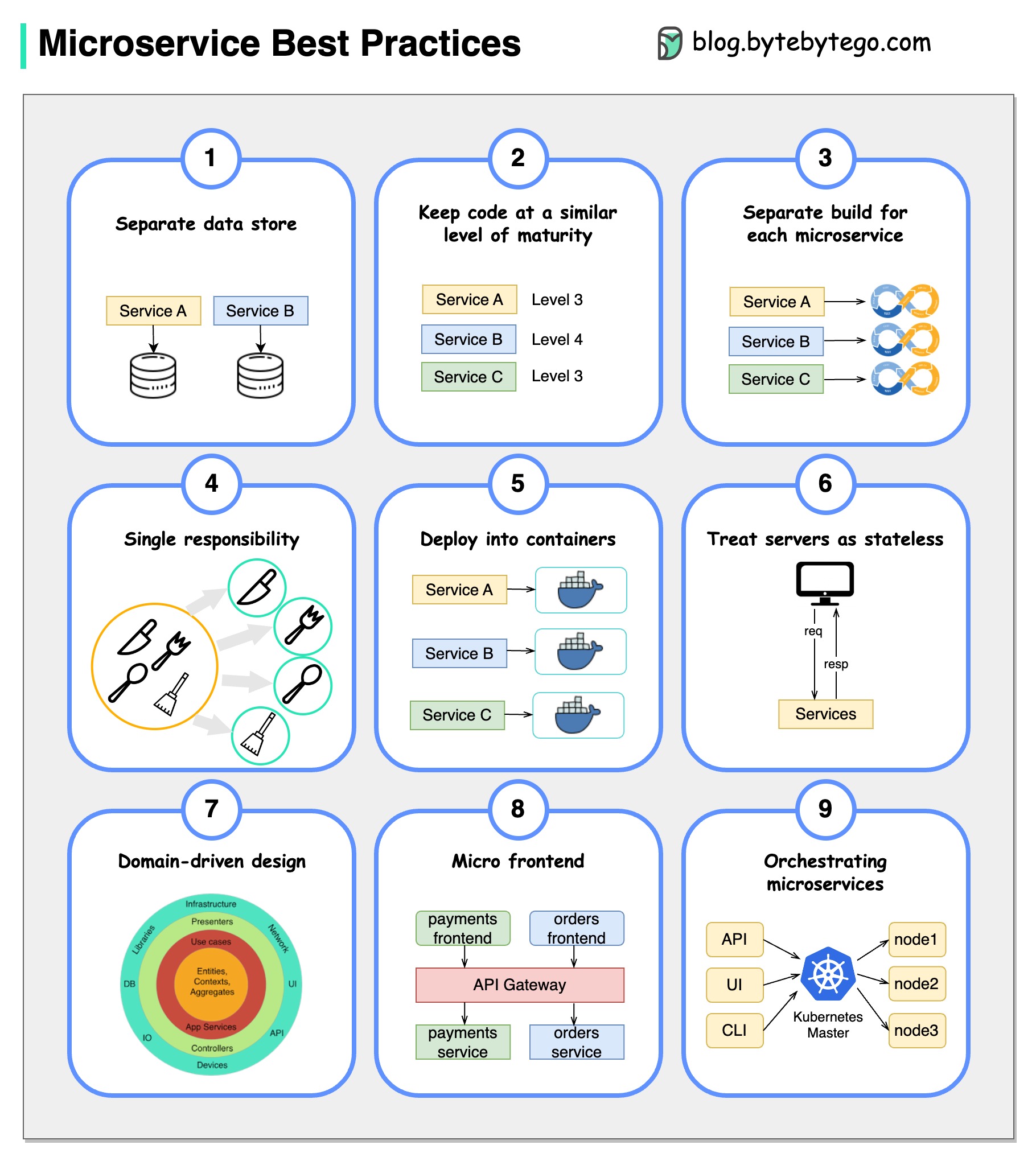
Quando desenvolvemos microsserviços, precisamos seguir as seguintes práticas recomendadas:
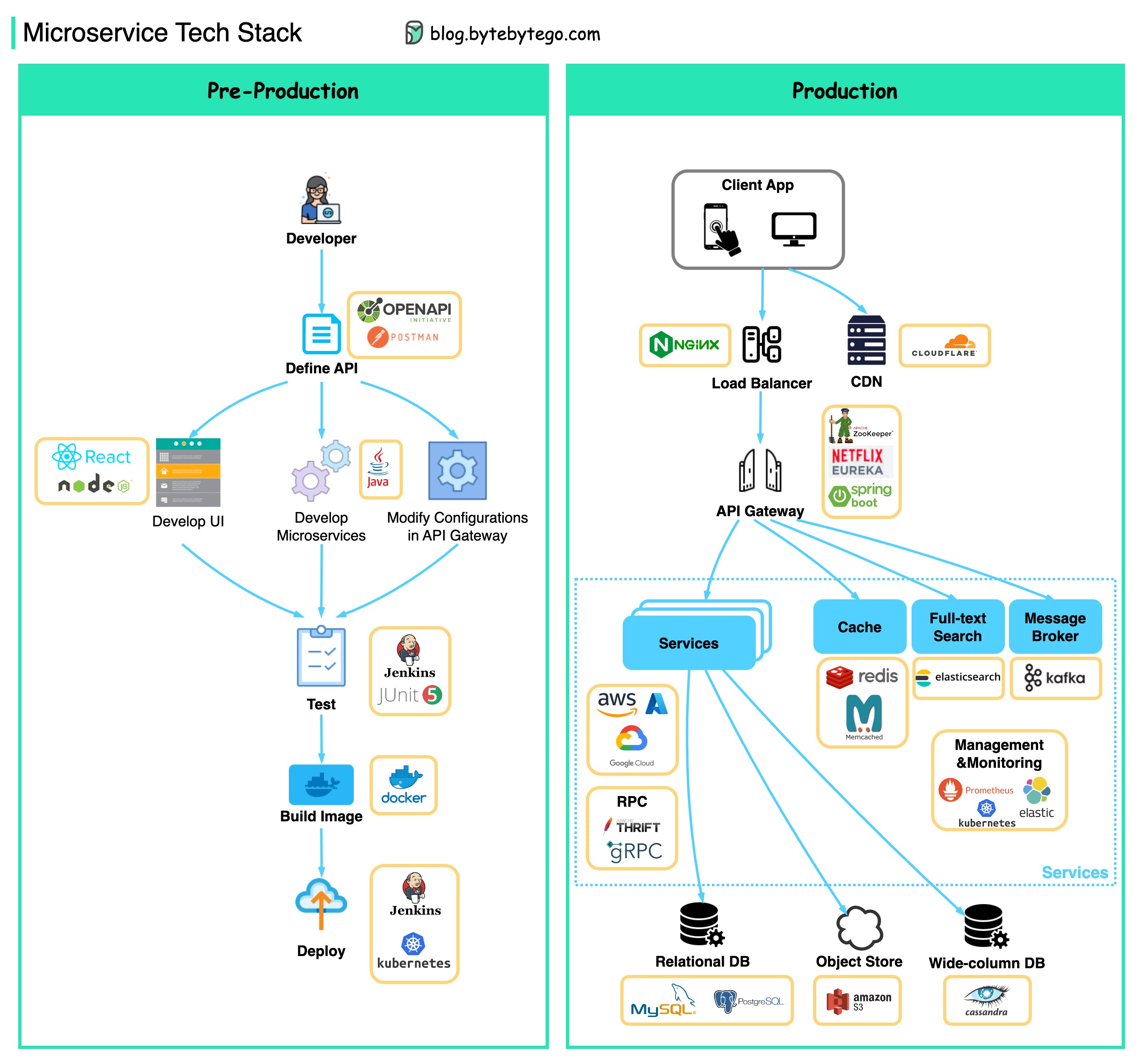
Abaixo, você encontrará um diagrama mostrando a pilha de tecnologia do MicrosService, tanto para a fase de desenvolvimento quanto para a produção.
Existem muitas decisões de design que contribuíram para o desempenho de Kafka. Neste post, vamos nos concentrar em dois. Achamos que esses dois carregaram mais peso.
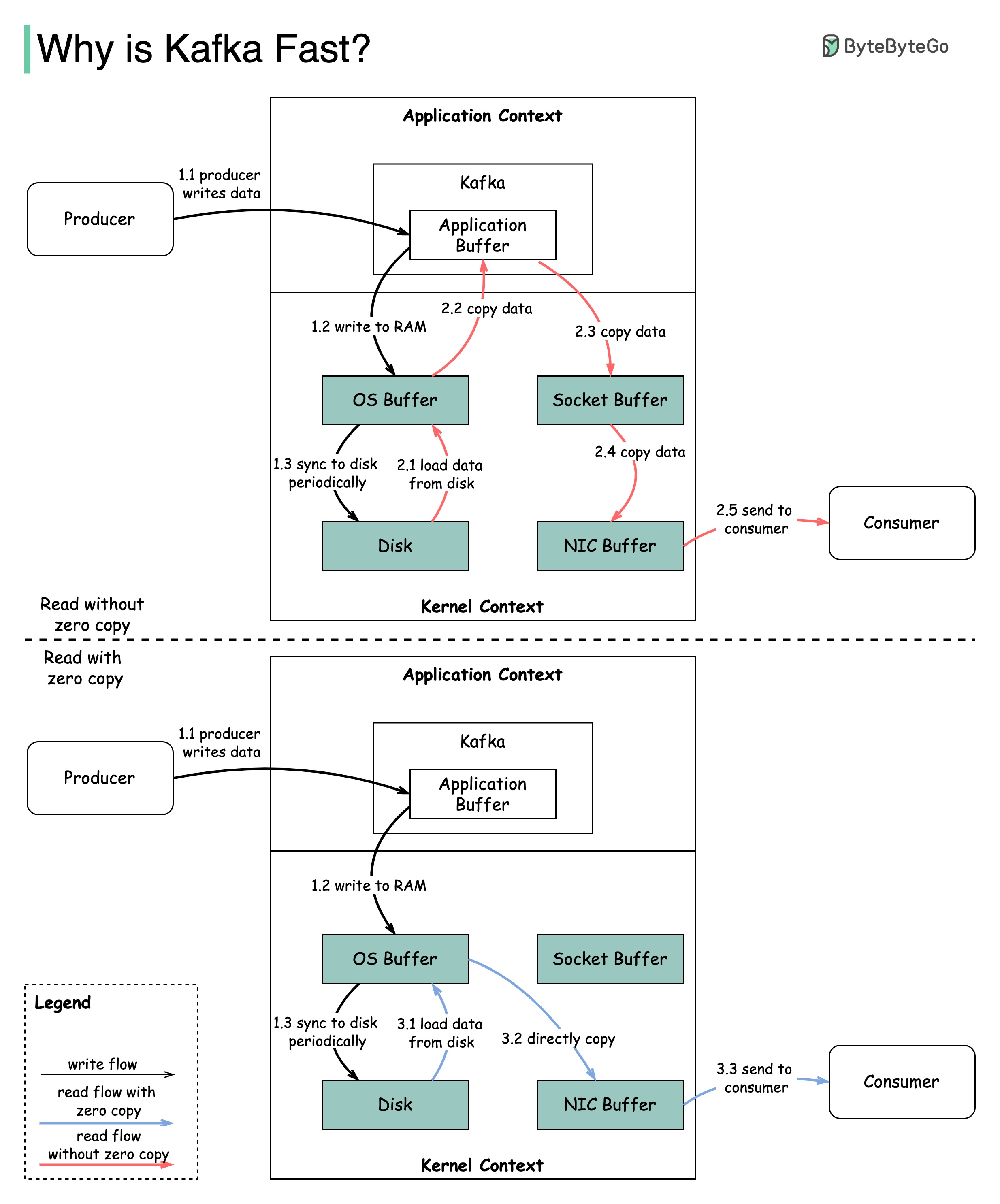
O diagrama ilustra como os dados são transmitidos entre produtor e consumidor e o que significa cópia zero.
2.1 Os dados são carregados do disco para o cache do sistema operacional
2.2 Os dados são copiados do Cache do OS para o aplicativo Kafka
2.3 Aplicativo Kafka copia os dados no buffer de soquete
2.4 Os dados são copiados do buffer de soquete para a placa de rede
2.5 A placa de rede envia dados para o consumidor
3.1: Os dados são carregados do disco para o cache do cache 3.2 cache OS copia diretamente os dados para a placa de rede via comando sendfile () 3.3 A placa de rede envia dados para o consumidor
Zero Cópia é um atalho para salvar as várias cópias de dados entre o contexto do aplicativo e o contexto do kernel.
O diagrama abaixo mostra a economia do fluxo de pagamento com cartão de crédito.
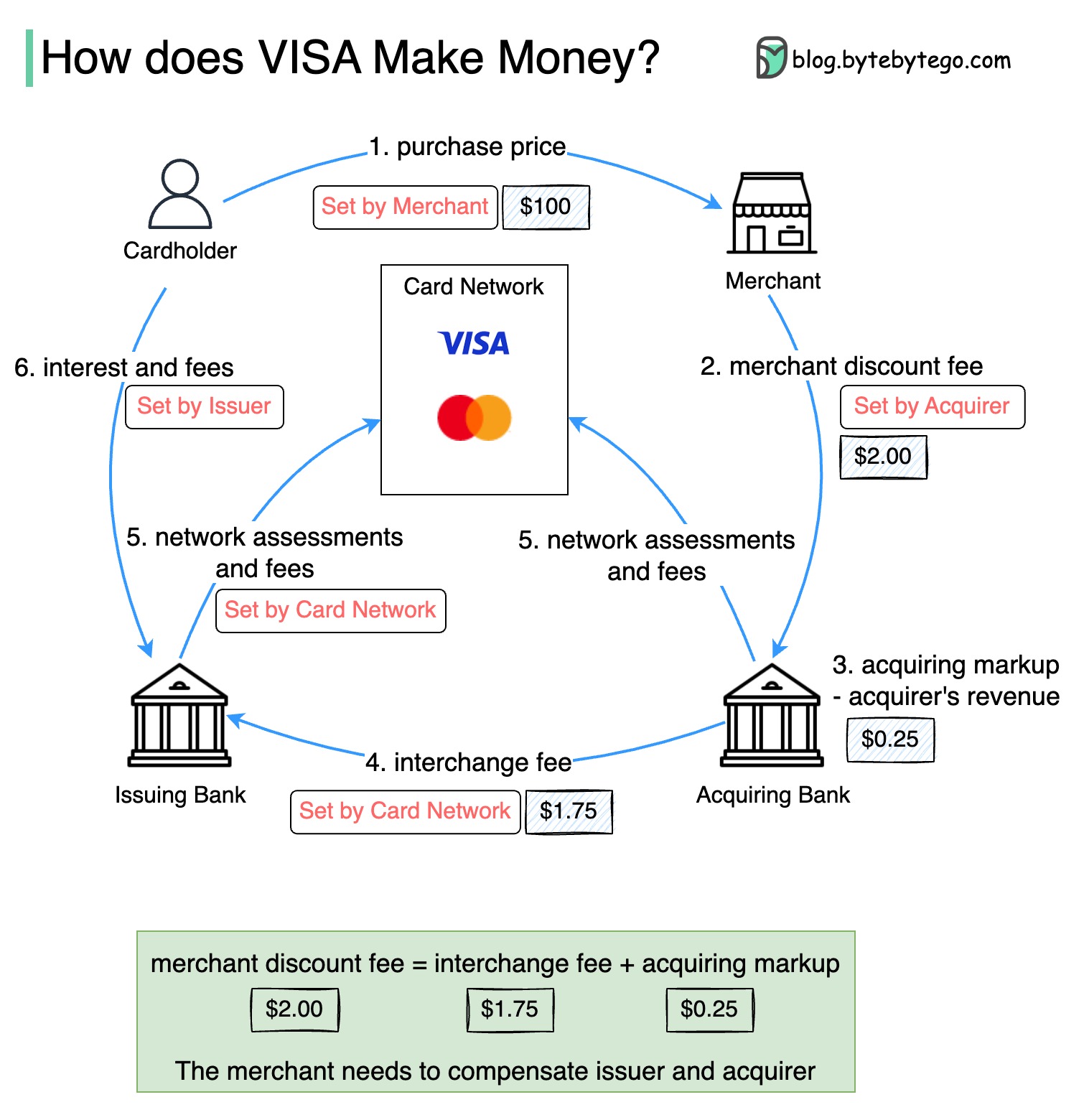
1. O titular do cartão paga US $ 100 comerciais para comprar um produto.
2. O comerciante se beneficia do uso do cartão de crédito com maior volume de vendas e precisa compensar o emissor e a rede de cartões para fornecer o serviço de pagamento. O banco adquirente define uma taxa com o comerciante, chamado "Taxa de desconto do comerciante".
3 - 4. O banco adquirente mantém US $ 0,25 como marcação de aquisição e US $ 1,75 é pago ao banco emissor como taxa de intercâmbio. A taxa de desconto do comerciante deve cobrir a taxa de intercâmbio.
A taxa de intercâmbio é estabelecida pela rede de cartões porque é menos eficiente para cada banco emissor negociar taxas com cada comerciante.
5. A rede de cartões configura as avaliações e taxas de rede com cada banco, que paga a rede de cartões por seus serviços todos os meses. Por exemplo, o VISA cobra uma avaliação de 0,11%, além de uma taxa de uso de US $ 0,0195, por cada furto.
6. O titular do cartão paga ao banco emissor por seus serviços.
Por que o banco emissor deve ser compensado?
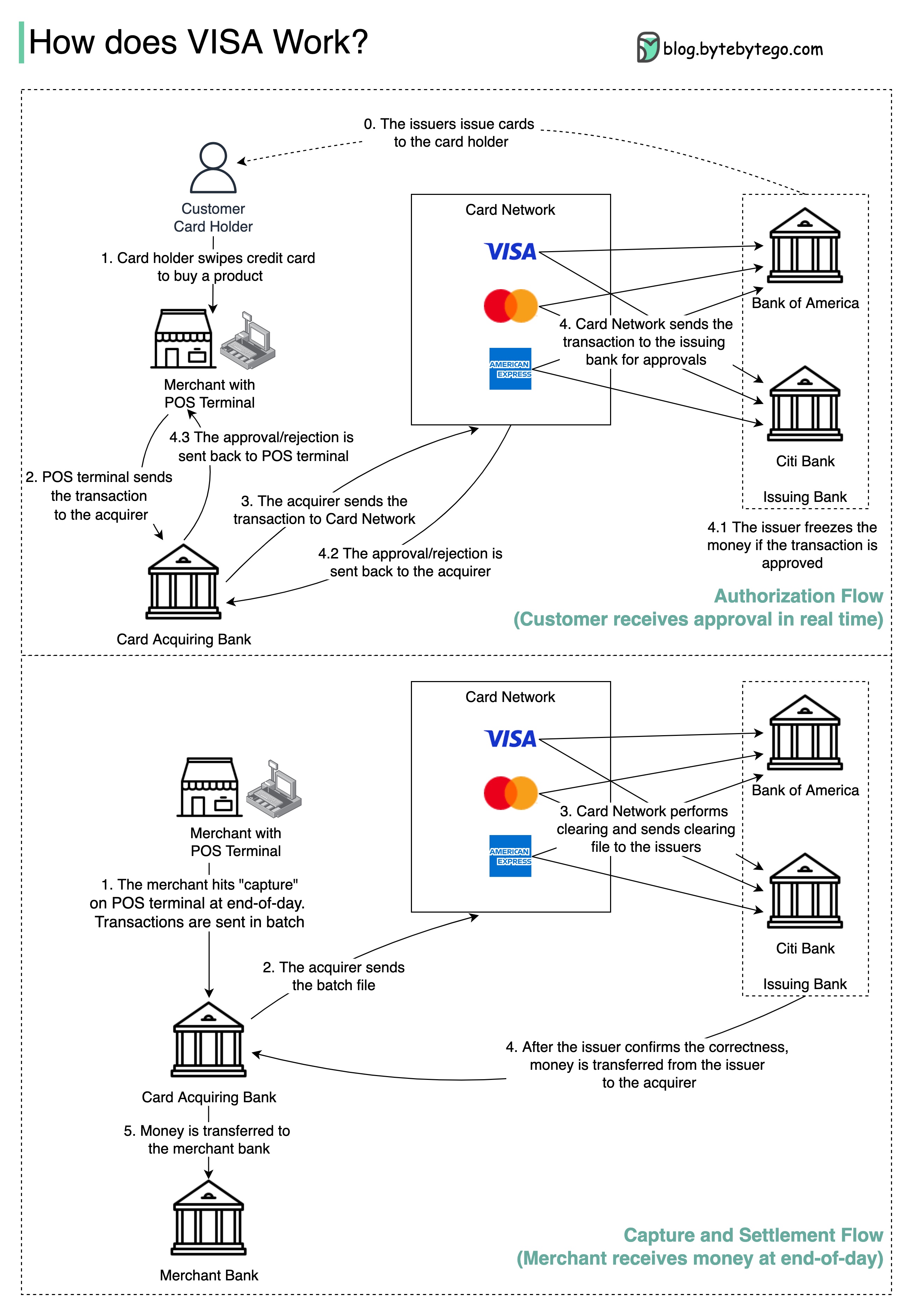
Visa, MasterCard e American Express atuam como redes de cartões para a limpeza e liquidação de fundos. O banco que adquiriu cartões e o banco emissor de cartões podem ser - e geralmente são - diferentes. Se os bancos resolvessem transações um por um sem intermediário, cada banco teria que liquidar as transações com todos os outros bancos. Isso é bastante ineficiente.
O diagrama abaixo mostra o papel da Visa no processo de pagamento do cartão de crédito. Existem dois fluxos envolvidos. O fluxo de autorização acontece quando o cliente passa o cartão de crédito. O fluxo de captura e liquidação acontece quando o comerciante quer obter o dinheiro no final do dia.
Etapa 0: o cartão emitindo cartões de crédito em emissão de seus clientes.
Etapa 1: O titular do cartão deseja comprar um produto e deslizar o cartão de crédito no ponto de venda (POS) na loja do comerciante.
Etapa 2: O terminal POS envia a transação para o banco adquirente, que forneceu o terminal POS.
Etapas 3 e 4: o banco adquirente envia a transação para a rede de cartões, também chamada de esquema de cartões. A rede de cartões envia a transação ao banco emissor para aprovação.
Etapas 4.1, 4.2 e 4.3: O banco emissor congela o dinheiro se a transação for aprovada. A aprovação ou rejeição é enviada de volta ao adquirente, bem como ao terminal POS.
Etapas 1 e 2: O comerciante quer coletar o dinheiro no final do dia, para que atinja "Capture" no terminal POS. As transações são enviadas para o adquirente em lote. O adquirente envia o arquivo em lote com transações para a rede de cartões.
Etapa 3: A rede de cartões executa a limpeza das transações coletadas de diferentes adquirentes e envia os arquivos de compensação para diferentes bancos emitidos.
Etapa 4: Os bancos emissores confirmam a correção dos arquivos de compensação e transferem dinheiro para os bancos adquirentes relevantes.
Etapa 5: O banco adquirente transfere dinheiro para o banco do comerciante.
Etapa 4: A rede de cartões limpa as transações de diferentes bancos adquirentes. A limpeza é um processo no qual as transações de deslocamento mútuo são compensadas, portanto o número de transações totais é reduzido.
No processo, a rede de cartões assume o ônus de conversar com cada banco e recebe taxas de serviço em troca.
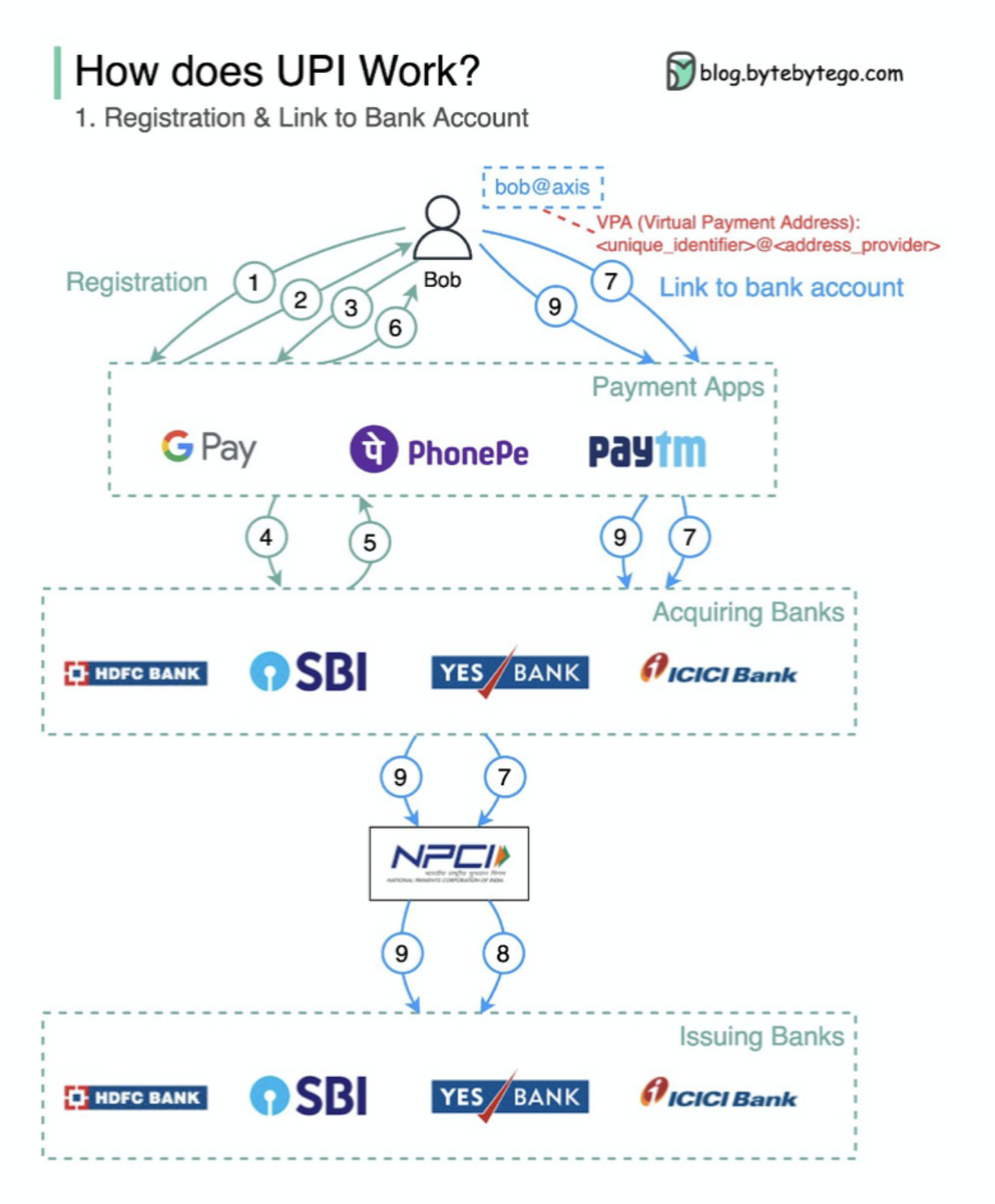
O que é UPI? A UPI é um sistema de pagamento em tempo real instantâneo desenvolvido pela National Payments Corporation da Índia.
Ele representa 60% das transações digitais de varejo na Índia hoje.
UPI = Linguagem da marcação de pagamento + padrão para pagamentos interoperáveis
Os conceitos de DevOps, SRE e engenharia de plataformas surgiram em momentos diferentes e foram desenvolvidos por vários indivíduos e organizações.
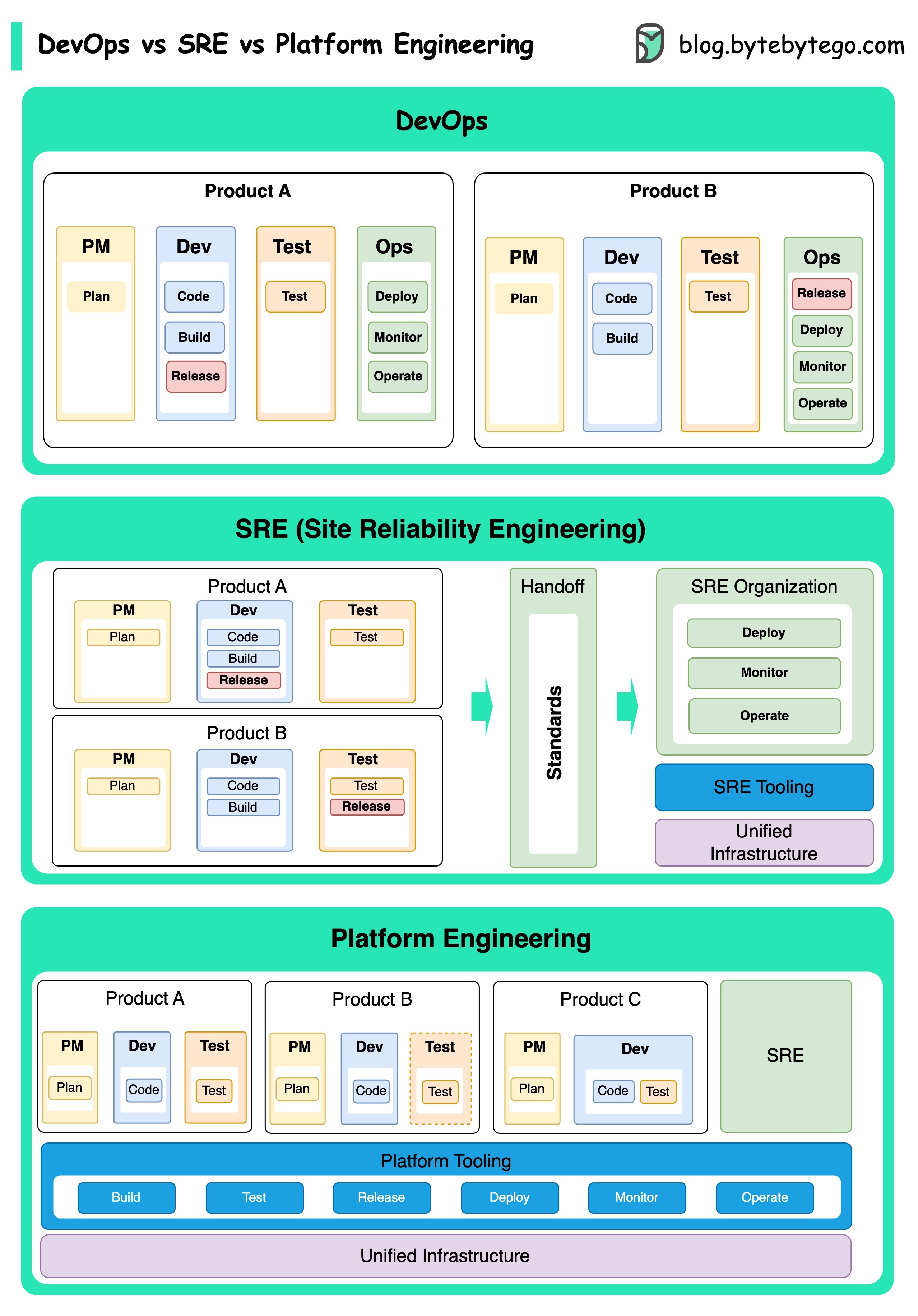
O DevOps como conceito foi introduzido em 2009 por Patrick Debois e Andrew Shafer na Conferência Agile. Eles procuraram preencher a lacuna entre o desenvolvimento de software e as operações, promovendo uma cultura colaborativa e compartilhou a responsabilidade por todo o ciclo de vida do desenvolvimento de software.
A SRE, ou engenharia de confiabilidade do site, foi pioneira pelo Google no início dos anos 2000 para enfrentar os desafios operacionais no gerenciamento de sistemas complexos em larga escala. O Google desenvolveu práticas e ferramentas de SRE, como o sistema de gerenciamento de cluster Borg e o sistema de monitoramento monarca, para melhorar a confiabilidade e a eficiência de seus serviços.
A Plataform Engineering é um conceito mais recente, construindo sobre a base da SRE Engineering. As origens precisas da engenharia de plataformas são menos claras, mas geralmente é entendida como uma extensão das práticas de DevOps e SRE, com foco em fornecer uma plataforma abrangente para o desenvolvimento de produtos que suporta toda a perspectiva dos negócios.
Vale a pena notar que, embora esses conceitos tenham surgido em momentos diferentes. Todos estão relacionados à tendência mais ampla de melhorar a colaboração, a automação e a eficiência no desenvolvimento e operações de software.
K8S é um sistema de orquestração de contêineres. É usado para implantação e gerenciamento de contêineres. Seu design é bastante impactado pelo sistema interno do Google Borg.
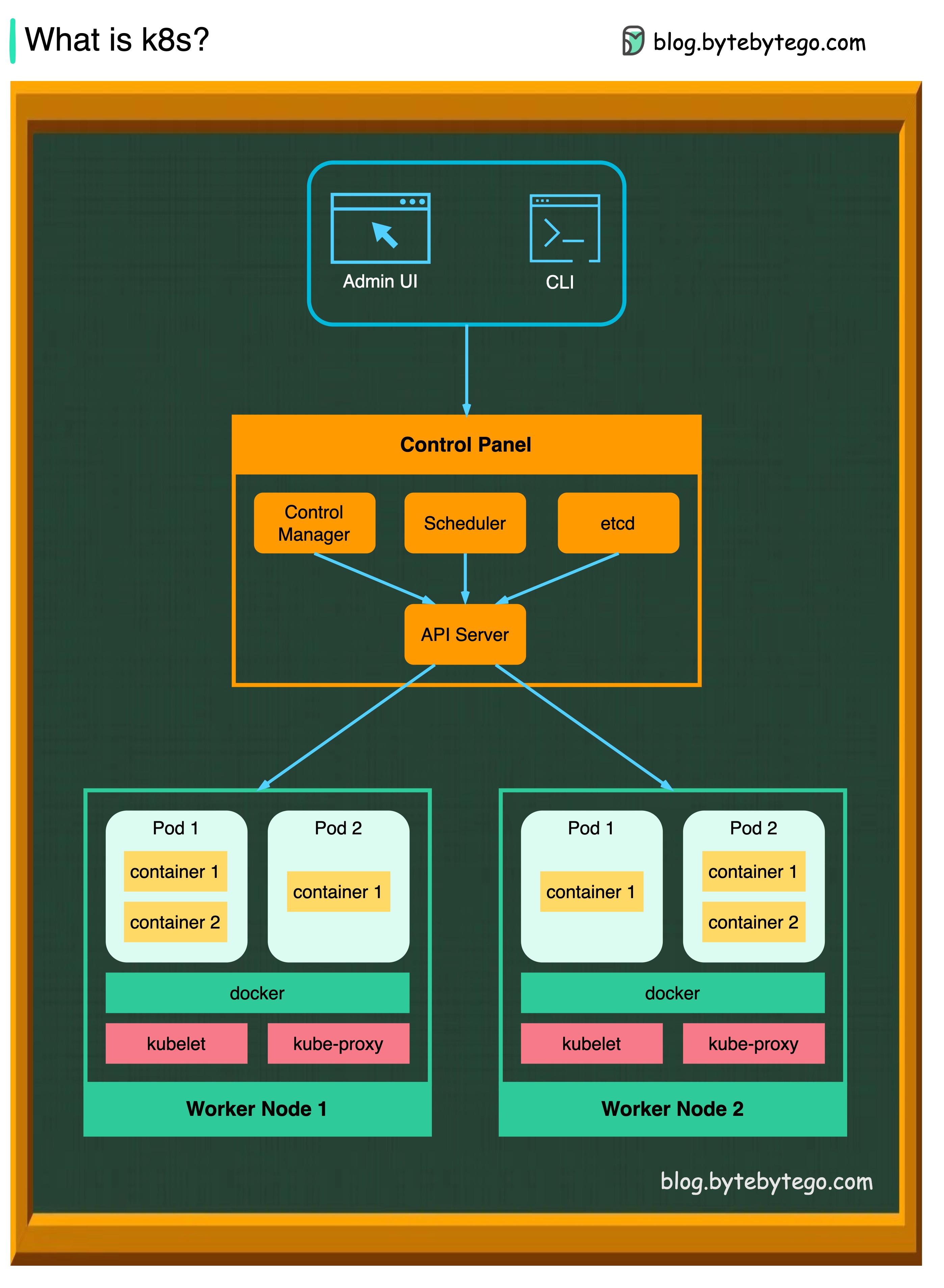
Um cluster K8S consiste em um conjunto de máquinas de trabalho, chamadas nós, que executam aplicativos de contêiner. Todo cluster tem pelo menos um nó do trabalhador.
O (s) nó do trabalhador (s) hospeda os pods que são os componentes da carga de trabalho do aplicativo. O plano de controle gerencia os nós do trabalhador e as vagens no cluster. Nos ambientes de produção, o plano de controle geralmente é executado em vários computadores, e um cluster geralmente executa vários nós, fornecendo tolerância a falhas e alta disponibilidade.
Servidor API
O servidor da API fala com todos os componentes no cluster K8S. Todas as operações nos pods são executadas conversando com o servidor API.
Agendador
O agendador assiste as cargas de trabalho de pod e atribui cargas em pods recém -criados.
Gerente de Controlador
O Controller Manager executa os controladores, incluindo controlador de nó, controlador de trabalho, controlador de pontos de extremidade e controlador ServiceAcCount.
etc.
O etcd é uma loja de valor-chave usada como loja de apoio da Kubernetes para todos os dados do cluster.
Vagens
Um POD é um grupo de contêineres e é a menor unidade que os K8s administram. Os pods têm um único endereço IP aplicado a todos os contêineres dentro da vagem.
Kubelet
Um agente que é executado em cada nó no cluster. Ele garante que os contêineres estejam em execução em uma vagem.
Kube proxy
O Kube-Proxy é um proxy de rede que é executado em cada nó em seu cluster. Ele direciona o tráfego que entra em um nó do serviço. Ele encaminha solicitações de trabalho para os contêineres corretos.

O que é Docker?
O Docker é uma plataforma de código aberto que permite que você empacote, distribua e execute aplicativos em contêineres isolados. Ele se concentra na contêinerização, fornecendo ambientes leves que encapsulam aplicativos e suas dependências.
O que é Kubernetes?
O Kubernetes, geralmente chamado de K8S, é uma plataforma de orquestração de contêineres de código aberto. Ele fornece uma estrutura para automatizar a implantação, escala e gerenciamento de aplicativos de contêiner em um cluster de nós.
Como os dois são diferentes um do outro?
Docker: Docker opera no nível individual de contêineres em um único host de sistema operacional.
Você deve gerenciar manualmente cada host e configurar redes, políticas de segurança e armazenamento para vários contêineres relacionados podem ser complexos.
Kubernetes: Kubernetes opera no nível do cluster. Ele gerencia vários aplicativos de contêiner em vários hosts, fornecendo automação para tarefas como balanceamento de carga, dimensionamento e garantindo o estado de aplicações desejado.
Em resumo, o Docker se concentra na contêiner e contêineres em hosts individuais, enquanto a Kubernetes é especializada no gerenciamento e orquestra de contêineres em escala em um cluster de hosts.
O diagrama abaixo mostra a arquitetura do Docker e como funciona quando executamos "Docker Build", "Docker Pull" e "Docker Run".
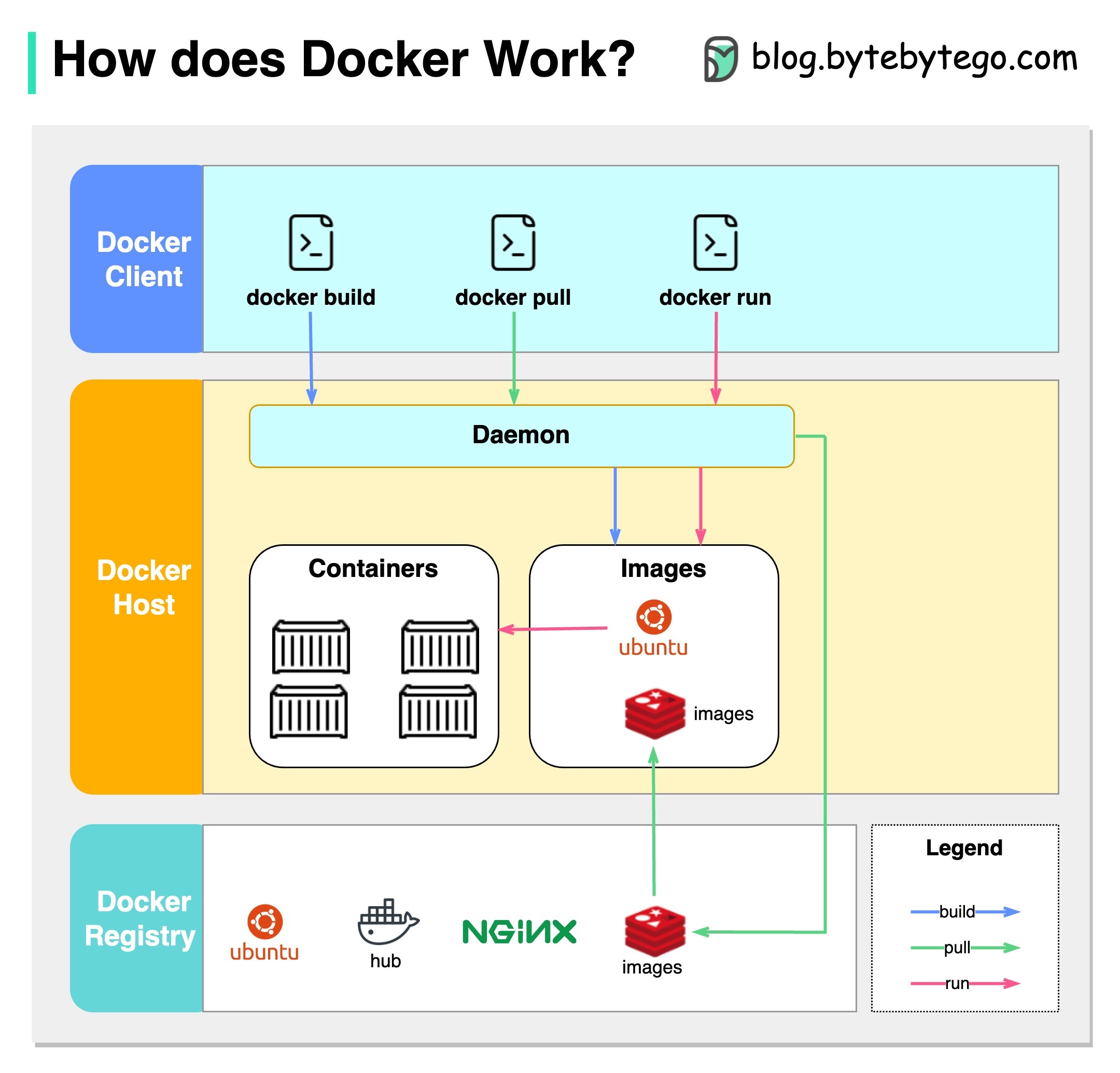
Existem 3 componentes na arquitetura do Docker:
Cliente Docker
O cliente do Docker fala com o daemon do Docker.
Host Docker
O Docker Daemon escuta as solicitações da API do Docker e gerencia objetos do Docker, como imagens, contêineres, redes e volumes.
Docker Registry
Um Docker Registry armazena imagens do Docker. Docker Hub é um registro público que qualquer um pode usar.
Vamos pegar o comando "Docker Run" como exemplo.
Para começar, é essencial identificar onde nosso código é armazenado. A suposição comum é que existem apenas dois locais - um em um servidor remoto como o GitHub e o outro em nossa máquina local. No entanto, isso não é totalmente preciso. O Git mantém três armazenamentos locais em nossa máquina, o que significa que nosso código pode ser encontrado em quatro lugares:
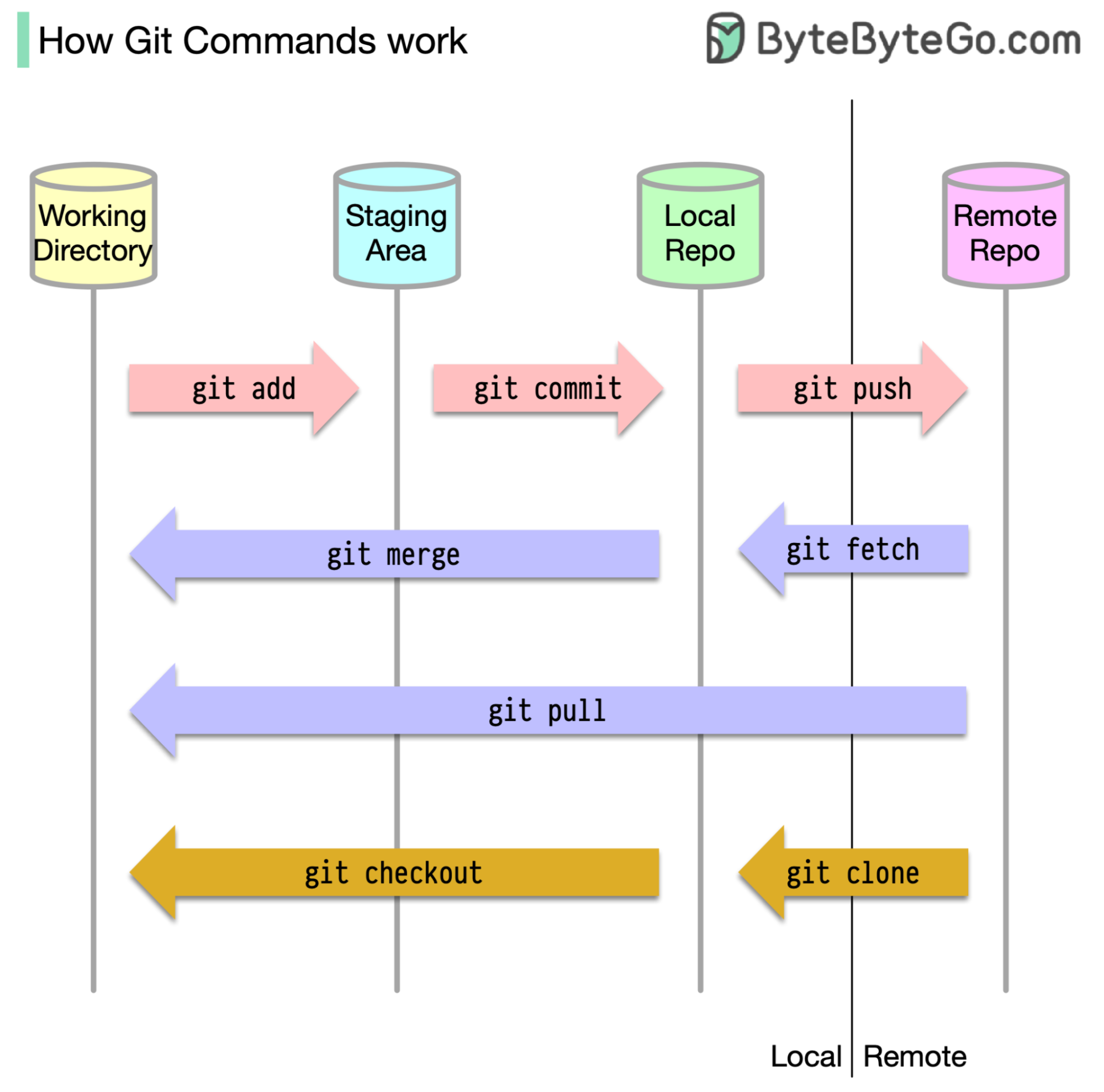
A maioria dos comandos Git move principalmente os arquivos entre esses quatro locais.
O diagrama abaixo mostra o fluxo de trabalho Git.
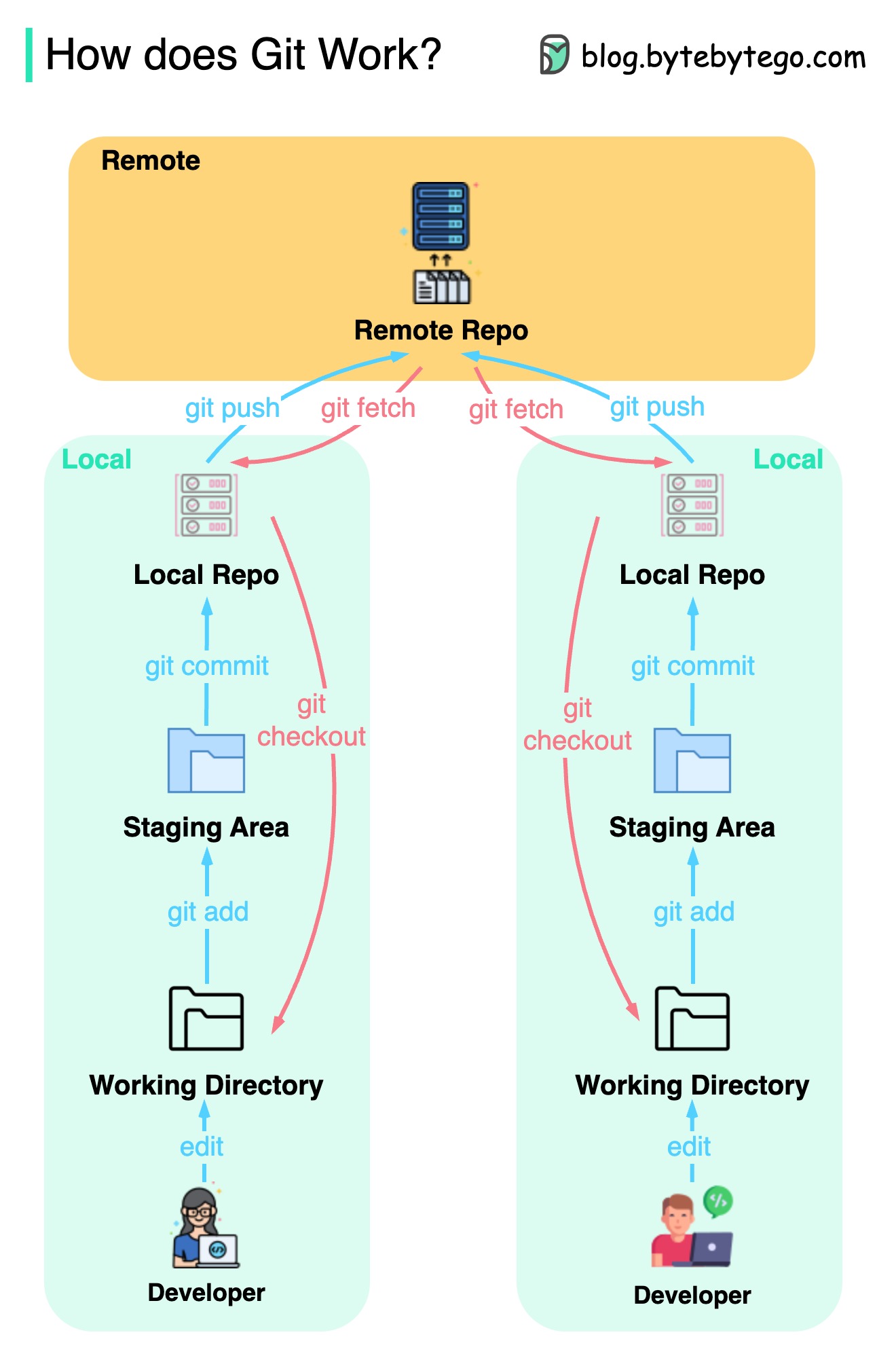
O GIT é um sistema de controle de versão distribuído.
Todo desenvolvedor mantém uma cópia local do repositório principal e edita e se compromete com a cópia local.
O compromisso é muito rápido porque a operação não interage com o repositório remoto.
Se o repositório remoto for acertado, os arquivos poderão ser recuperados dos repositórios locais.
Quais são as diferenças?


