ai pizza
1.0.0
Ainda assim, ninguém sabe se uma máquina pode criar algo novo ou se está limitada ao que já sabe. Mas mesmo agora, a inteligência artificial pode resolver problemas complicados e analisar conjuntos de dados não estruturados. Nós da Dodo decidimos fazer um experimento. Organizar e descrever estruturalmente algo considerado caótico e subjetivo — o sabor. Decidimos usar a inteligência artificial para encontrar as combinações mais selvagens de ingredientes que, no entanto, serão consideradas deliciosas pela maioria das pessoas.
Em colaboração com especialistas do MIPT e Skoltech, criamos inteligência artificial que analisou mais de 300.000 receitas e resultados de pesquisas sobre combinações moleculares de ingredientes conduzidas por Cambridge e várias outras universidades dos EUA. Com base nisso, a IA aprendeu a encontrar conexões não óbvias entre ingredientes e a entender como emparelhar os ingredientes e como a presença de cada um influencia as combinações de todos os outros.
Para qualquer modelo você precisa de dados. É por isso que para treinar a nossa IA recolhemos mais de 300 000 receitas culinárias.
A parte difícil não foi coletá-los, mas colocá-los na mesma forma. Por exemplo, a pimenta malagueta nas receitas é listada como “pimenta”, “pimenta”, “pimenta” ou mesmo “pimenta”. É óbvio para nós que tudo isso significa “pimenta”, mas a rede neural considera cada um deles como uma entidade individual.
Inicialmente, tínhamos mais de 100.000 ingredientes únicos e, depois de limparmos os dados, restaram apenas 1.000 posições únicas.
Assim que obtivermos o conjunto de dados, fizemos uma análise inicial. Primeiro, fizemos uma avaliação quantitativa de quantas cozinhas estavam presentes em nosso conjunto de dados.
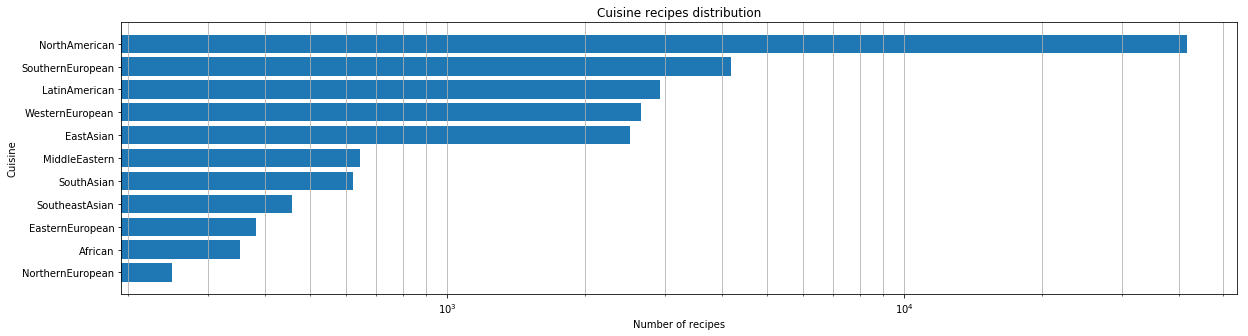
Para cada cozinha, identificamos os ingredientes mais populares.
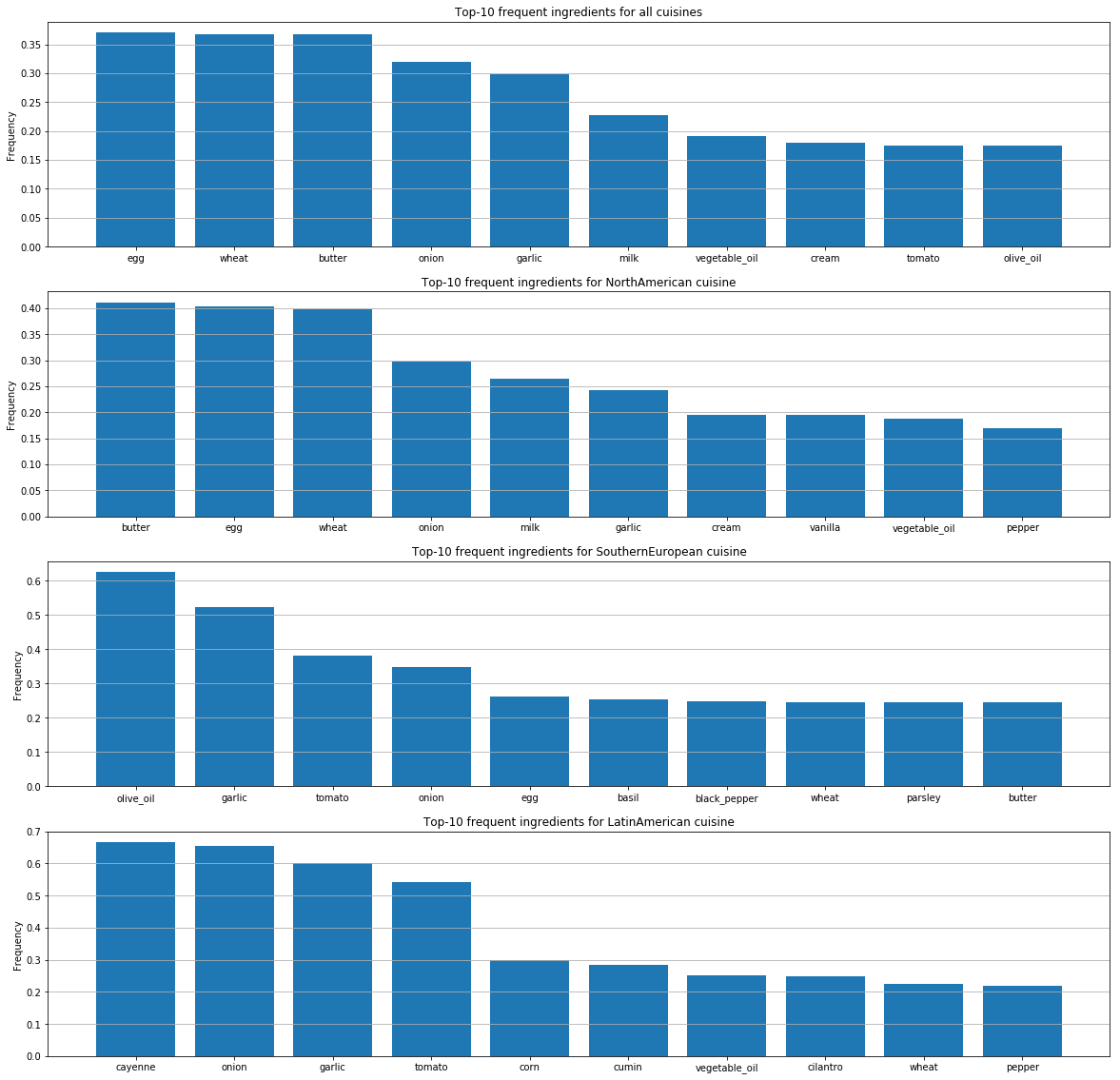
Esses gráficos mostram diferenças nas preferências de gosto das pessoas por país e diferenças na forma como combinam os ingredientes.
Depois disso, decidimos analisar receitas de pizza de todo o mundo para descobrir os padrões. Estas são as conclusões que tiramos.
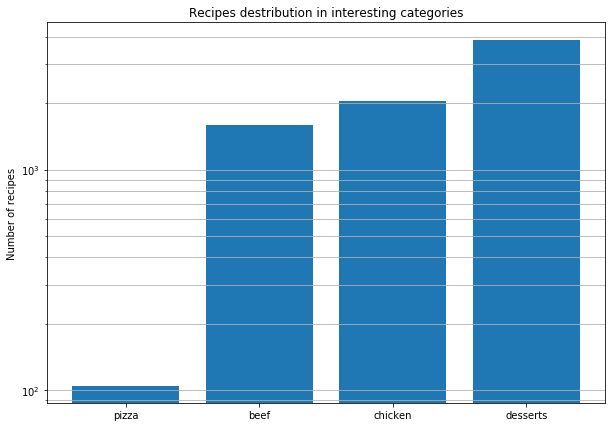
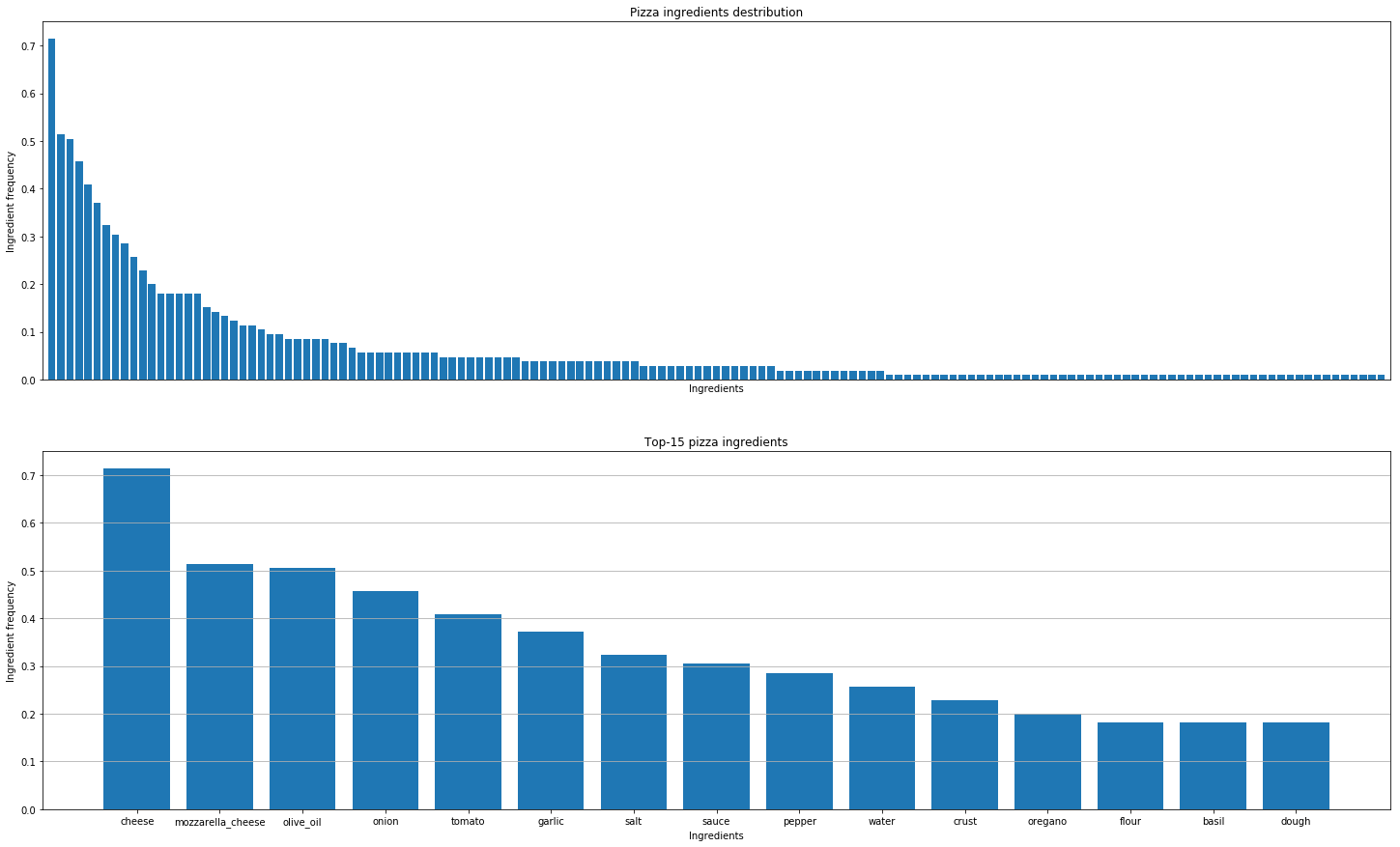
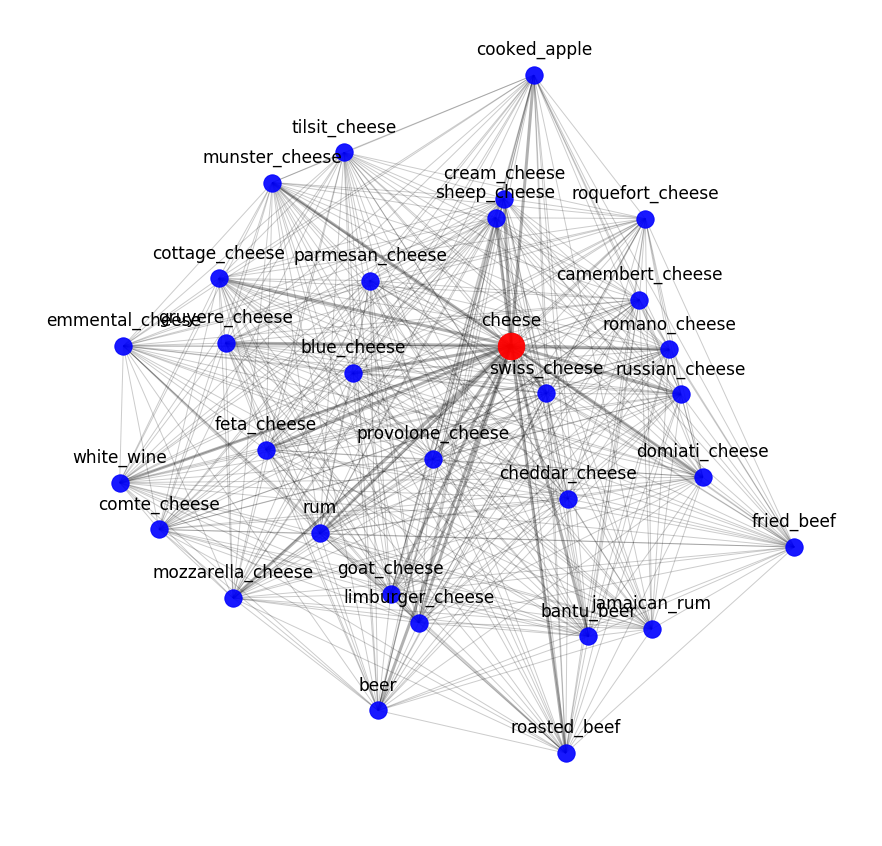
Encontrar combinações reais de sabores não é o mesmo que descobrir combinações moleculares. Todos os queijos têm a mesma composição molecular, mas isso não significa que boas combinações possam vir apenas dos ingredientes mais próximos.
No entanto, são as combinações de ingredientes molecularmente semelhantes que precisamos de ver quando convertemos os ingredientes em matemática. Porque objetos semelhantes (os mesmos queijos) devem permanecer semelhantes, não importa como os descrevamos. Desta forma podemos determinar se os objetos estão descritos corretamente.
Para apresentar a receita de forma compreensível para a rede neural, utilizamos Skip-Gram Negative Sampling (SGNS) — um algoritmo de word2vec, baseado na ocorrência de palavras no contexto.
Decidimos não usar modelos word2vec pré-treinados porque a estrutura semântica da receita é diferente de textos simples. E com estes modelos, poderíamos perder informações importantes.
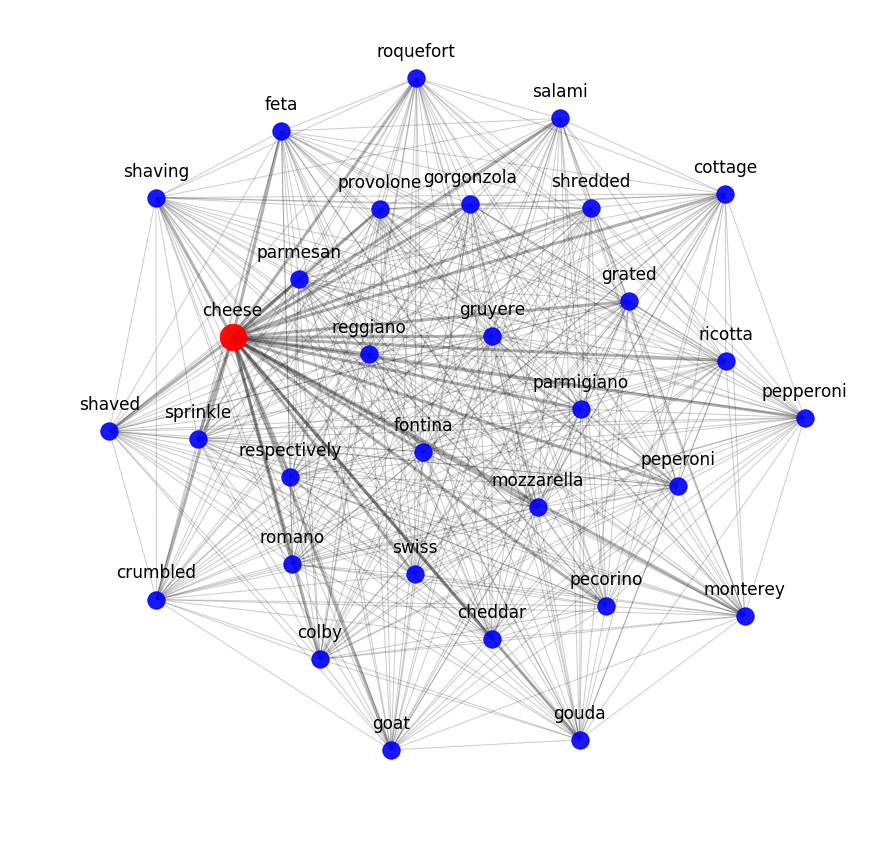
Você pode avaliar o resultado do word2vec observando os vizinhos semânticos mais próximos. Por exemplo, aqui está o que nosso modelo sabe sobre queijo:
Para testar até que ponto os modelos semânticos podem capturar as inter-relações dos ingredientes nas receitas, aplicamos um modelo de tópico. Em outras palavras, tentamos dividir o conjunto de dados da receita em clusters de acordo com regularidades determinadas matematicamente.
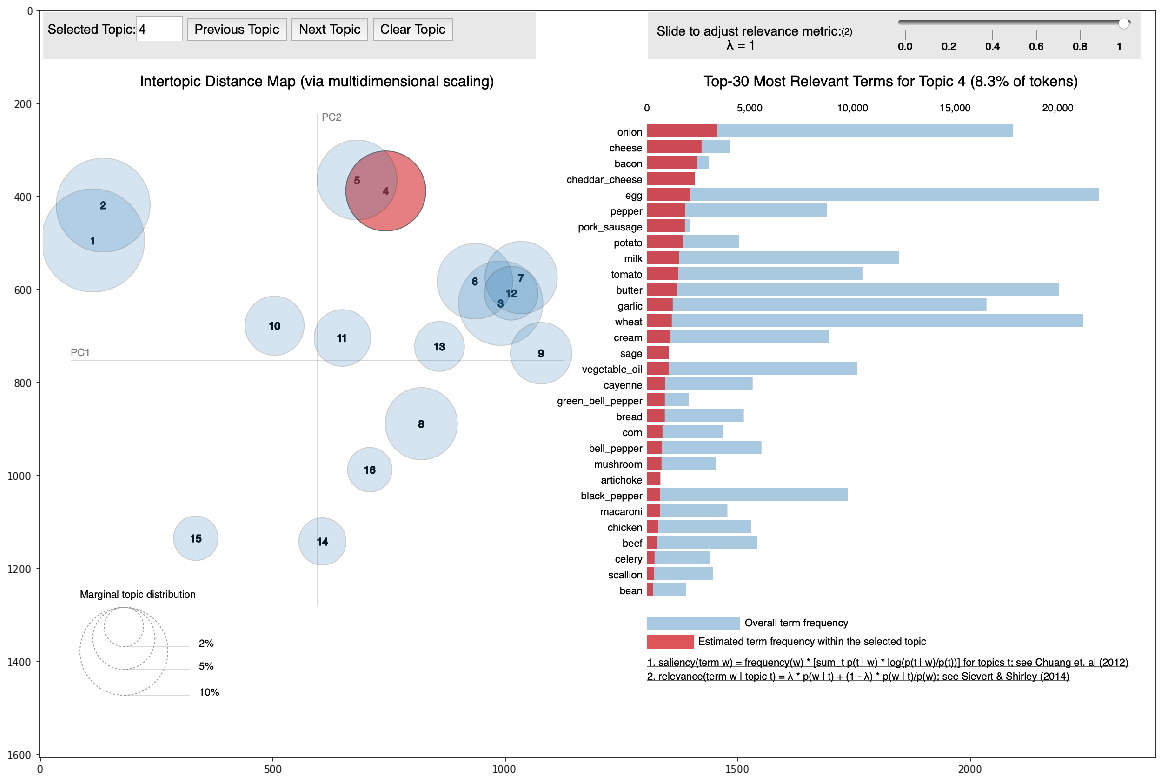
Para todas as receitas, sabíamos determinados clusters aos quais correspondiam. Para receitas de amostra, sabíamos sua conexão com clusters reais. Com base nisso encontramos a ligação entre esses dois tipos de clusters.
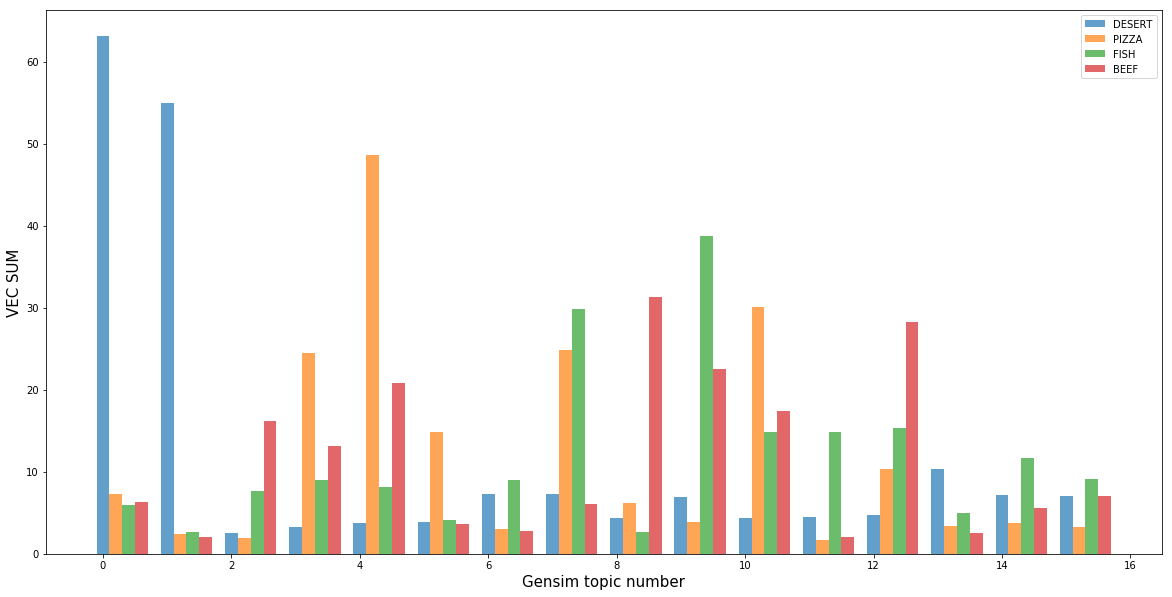
A mais evidente foi a classe de sobremesas, que foram incluídas nos tópicos 0 e 1, geradas pelo modelo de tópicos. Além das sobremesas, quase não existem outras aulas sobre estes temas, o que sugere que as sobremesas se separam facilmente de outras classes de pratos. Além disso, cada tópico tem uma classe que o descreve melhor. Isto significa que os nossos modelos conseguiram definir matematicamente o significado não óbvio de “gosto”.
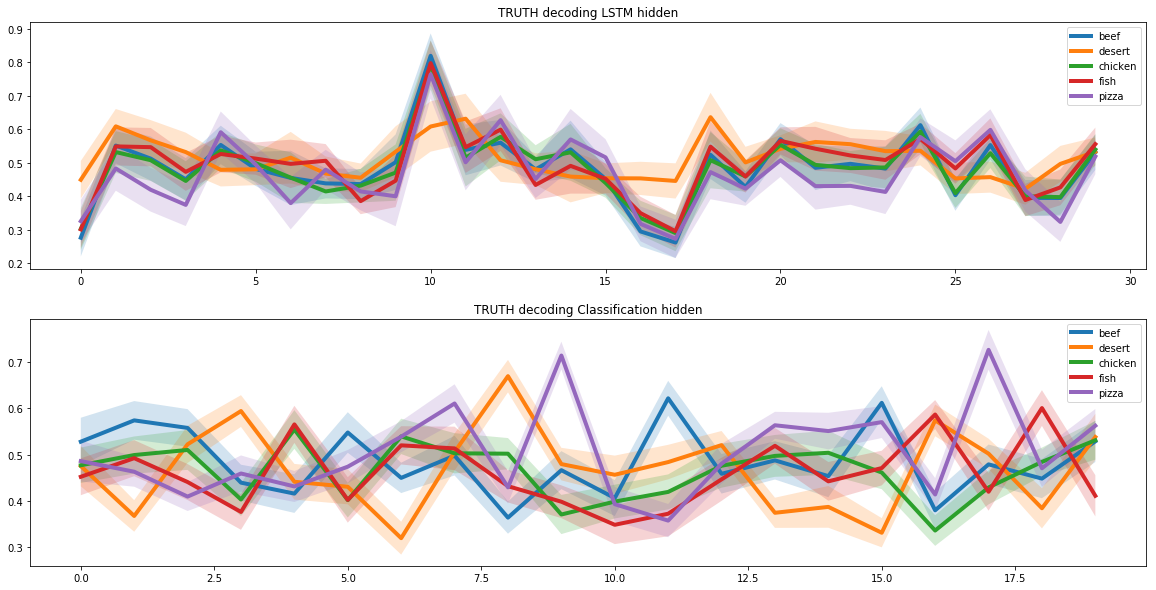
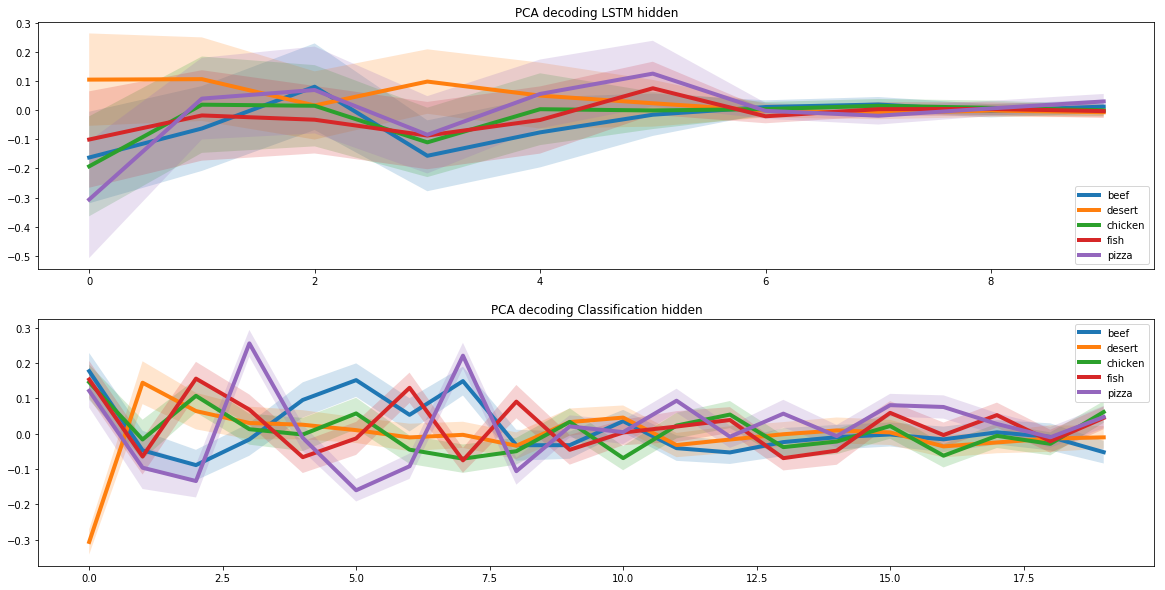
Usamos duas redes neurais recorrentes para criar novas receitas. Para tanto, assumimos que em todo o espaço de receitas existe um subespaço que corresponde às receitas de pizza. E para que a rede neural aprendesse a criar novas receitas de pizza, tivemos que encontrar este subespaço.
Esta tarefa é semelhante à autocodificação de imagens, na qual apresentamos a imagem como um vetor de baixa dimensão. Esses vetores podem conter muitas informações específicas sobre a imagem.
Por exemplo, esses vetores podem armazenar informações sobre a cor do cabelo de uma pessoa em uma célula separada para reconhecimento facial em uma foto. Escolhemos esta abordagem precisamente por causa das propriedades únicas do subespaço oculto.
Para identificar o subespaço da pizza, executamos as receitas da pizza por meio de duas redes neurais recorrentes. O primeiro recebeu a receita da pizza e encontrou sua representação como vetor latente. O segundo recebeu um vetor latente da primeira rede neural e criou uma receita baseada nele. As receitas na entrada da primeira rede neural e na saída da segunda deveriam ser iguais.
Dessa forma, duas redes neurais aprenderam a transformar corretamente a receita de um vetor latente. E com base nisso conseguimos encontrar um subespaço oculto, que corresponde a toda a gama de receitas de pizza.
Quando resolvemos o problema de criação de uma receita de pizza, tivemos que adicionar critérios de combinação molecular ao modelo. Para fazer isso, usamos os resultados de um estudo conjunto de cientistas de Cambridge e de várias universidades dos EUA.
O estudo descobriu que os ingredientes com os pares moleculares mais comuns formam as melhores combinações. Portanto, ao criar a receita, a rede neural preferiu ingredientes com estrutura molecular semelhante.
Como resultado, nossa rede neural aprendeu a criar receitas de pizza. Ao ajustar os coeficientes, a rede neural pode produzir tanto receitas clássicas, como margaritas ou pepperoni, quanto receitas inusitadas, uma das quais é o coração da Opensource Pizza.
| Não | Receita |
|---|---|
| 1 | espinafre, queijo, tomate, azeitona preta, azeitona, alho, pimenta, manjericão, frutas cítricas, melão, broto, leitelho, limão, robalo, nozes, rutabaga |
| 2 | cebola, tomate, azeitona, pimenta preta, pão, massa |
| 3 | frango, cebola, azeitona preta, queijo, molho, tomate, azeite, queijo mussarela |
| 4 | tomate, manteiga, queijo cremoso, pimenta, azeite, queijo, pimenta preta, queijo mussarela |
Open Source Pizza é licenciada sob licença MIT.
Golodyayev Arseniy, MIPT, Skoltech, [email protected]
Egor Baryshnikov, Skoltech, [email protected]


