meme search engine
1.0.0
Você tem uma pasta grande de memes que deseja pesquisar semanticamente? Você tem um servidor Linux com GPU Nvidia? Você faz; isso agora é obrigatório.
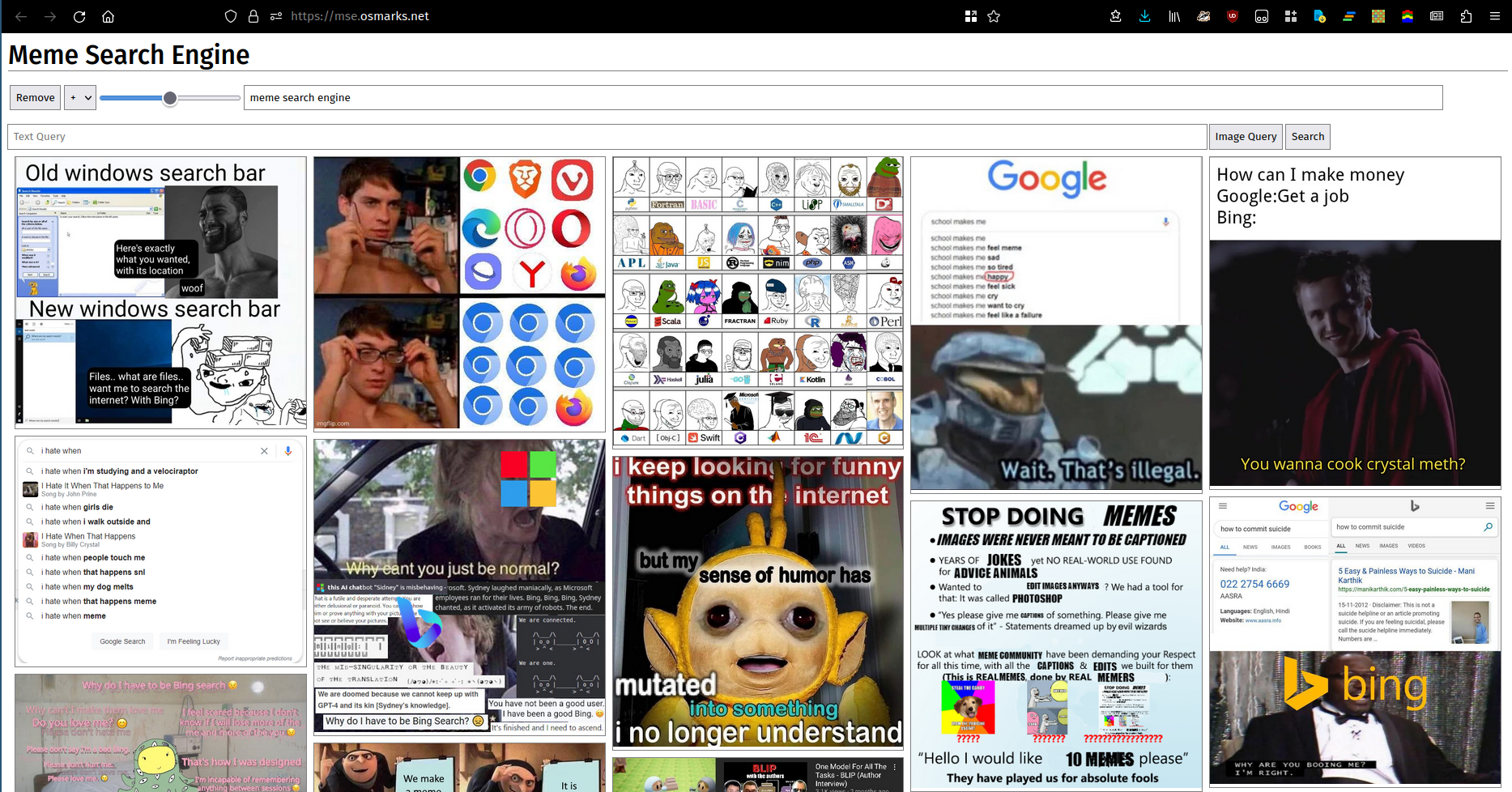
Dizem que uma imagem vale mais que mil palavras. Infelizmente, muitos (a maioria?) conjuntos de palavras não podem ser adequadamente descritos por imagens. Independentemente disso, aqui está uma foto. Você pode usar uma instância em execução aqui.
Isso não foi testado. Pode funcionar. A nova versão do Rust simplifica algumas etapas (integra sua própria miniatura).
python -m http.server .pip de requirements.txt (as versões provavelmente não precisarão corresponder exatamente se você precisar alterá-las; acabei de colocar o que tenho instalado atualmente).transformers devido ao suporte SigLIP.thumbnailer.py (periodicamente, ao mesmo tempo que o índice é recarregado, de preferência)clip_server.py (como serviço em segundo plano).clip_server_config.json .device provavelmente deveria ser cuda ou cpu . O modelo será executado aqui.model émodel_name é o nome do modelo para fins de métricas.max_batch_size controla o tamanho máximo permitido do lote. Valores mais altos geralmente resultam em um desempenho um pouco melhor (o gargalo na maioria dos casos está em outro lugar agora) ao custo de um maior uso de VRAM.port é a porta para executar o servidor HTTP.meme-search-engine (Rust) (também como serviço em segundo plano).clip_server é o URL completo do servidor back-end.db_path é o caminho para o banco de dados SQLite de imagens e vetores de incorporação.files é onde os arquivos meme serão lidos. Os subdiretórios são indexados.port é a porta para servir HTTP.enable_thumbs como true para fornecer imagens compactadas.npm install , node src/build.js .frontend_config.json .image_path é o URL base do seu servidor meme (com barra final).backend_url é o URL em que mse.py está exposto (barra final provavelmente opcional).clip_server.py . Veja aqui informações sobre o MemeThresher, o novo sistema automático de aquisição/classificação de memes (em meme-rater ). Prevê-se que a implantação por conta própria seja um tanto complicada, mas deve ser praticamente factível:
crawler.py com sua própria fonte e execute-o para coletar um conjunto de dados inicial.mse.py com um arquivo de configuração como o fornecido para indexá-lo.rater_server.py para coletar um conjunto de dados inicial de pares.train.py para treinar um modelo. Talvez seja necessário ajustar os hiperparâmetros, pois não tenho ideia de quais são bons.active_learning.py no melhor ponto de verificação disponível para avaliar novos pares.copy_into_queue.py para copiar os novos pares na fila rater_server.py .library_processing_server.py e agende meme_pipeline.py para ser executado periodicamente. O Meme Search Engine usa um índice FAISS na memória para armazenar seus vetores de incorporação, porque eu era preguiçoso e funciona bem (~ 100 MB de RAM total usado para meus 8.000 memes). Se você quiser armazenar significativamente mais do que isso, terá que mudar para um índice mais eficiente/compacto (veja aqui). Como os índices vetoriais são mantidos exclusivamente na memória, você precisará persisti-los no disco ou usar aqueles que sejam rápidos para construir/remover/adicionar (presumivelmente índices PCA/PQ). Em algum momento, se você aumentar o tráfego total, o modelo CLIP também poderá se tornar um gargalo, pois também não tenho estratégia de lote. Atualmente, a indexação está vinculada à GPU, pois o novo modelo parece um pouco mais lento em lotes grandes e melhorei o pipeline de carregamento de imagens. Você também pode reduzir os memes exibidos para reduzir as necessidades de largura de banda.


