dsub
Release 0.5.0
dsub é uma ferramenta de linha de comando que facilita o envio e a execução de scripts em lote na nuvem.
A experiência do usuário dsub é modelada a partir de agendadores de tarefas de computação tradicionais de alto desempenho, como Grid Engine e Slurm. Você escreve um script e o envia para um agendador de tarefas a partir de um prompt de shell em sua máquina local.
Hoje, dsub oferece suporte ao Google Cloud como executor de tarefas em lote de back-end, junto com um provedor local para desenvolvimento e teste. Com a ajuda da comunidade, gostaríamos de adicionar outros back-ends, como Grid Engine, Slurm, Amazon Batch e Azure Batch.
dsub é escrito em Python e requer Python 3.7 ou superior.
dsub 0.4.7.dsub 0.4.1.dsub 0.3.10.Isso é opcional, mas seja instalando do PyPI ou do github, é altamente recomendável usar um ambiente virtual Python.
Você pode fazer isso em um diretório de sua escolha.
python3 -m venv dsub_libs
source dsub_libs/bin/activate
O uso de um ambiente virtual Python isola as dependências da biblioteca dsub de outros aplicativos Python em seu sistema.
Ative este ambiente virtual em qualquer sessão de shell antes de executar dsub . Para desativar o ambiente virtual em seu shell, execute o comando:
deactivate
Alternativamente, é fornecido um conjunto de scripts de conveniência que ativam o virutalenv antes de chamar dsub , dstat e ddel . Eles estão no diretório bin. Você pode usar esses scripts se não quiser ativar o virtualenv explicitamente em seu shell.
Embora não seja usado diretamente pelo dsub para os provedores google-batch ou google-cls-v2 , é provável que você queira instalar as ferramentas de linha de comando encontradas no Google Cloud SDK.
Se você for usar o provedor local para um desenvolvimento mais rápido do trabalho, precisará instalar o SDK do Google Cloud, que usa gsutil para garantir a semântica de operação de arquivos consistente com os provedores dsub do Google.
Instale o SDK do Google Cloud
Correr
gcloud init
gcloud solicitará que você defina seu projeto padrão e conceda credenciais ao Google Cloud SDK.
dsubEscolha um dos seguintes:
Se necessário, instale o pip.
Instalar dsub
pip install dsub
Certifique-se de ter o git instalado
Instruções para o seu ambiente podem ser encontradas no site do git.
Clone este repositório.
git clone https://github.com/DataBiosphere/dsub
cd dsub
Instale o dsub (isso também instalará as dependências)
python -m pip install .
Configure a conclusão da guia Bash (opcional).
source bash_tab_complete
Verifique minimamente a instalação executando:
dsub --help
(Opcional) Instale o Docker.
Isso será necessário apenas se você quiser criar suas próprias imagens Docker ou usar o provedor local .
Após clonar o repositório dsub, você também pode usar o Makefile executando:
make
Isso criará um ambiente virtual Python e instalará dsub em um diretório chamado dsub_libs .
Achamos que você achará o provedor local muito útil ao criar suas tarefas dsub . Em vez de enviar uma solicitação para executar seu comando em uma VM na nuvem, o provedor local executa suas tarefas dsub em sua máquina local.
O provedor local não foi projetado para funcionar em escala. Ele foi projetado para emular a execução em uma VM na nuvem, de modo que você possa iterar rapidamente. Você obterá tempos de resposta mais rápidos e não incorrerá em cobranças de nuvem ao usá-lo.
Execute um trabalho dsub e aguarde a conclusão.
Aqui está um teste "Hello World" muito simples:
dsub
--provider local
--logging "${TMPDIR:-/tmp}/dsub-test/logging/"
--output OUT="${TMPDIR:-/tmp}/dsub-test/output/out.txt"
--command 'echo "Hello World" > "${OUT}"'
--wait
Nota: TMPDIR é comumente definido como /tmp por padrão na maioria dos sistemas Unix, embora muitas vezes não seja definido. Em algumas versões do MacOS, o TMPDIR está definido para um local em /var/folders .
Nota: A sintaxe acima ${TMPDIR:-/tmp} é conhecida por ser suportada por Bash, zsh, ksh. O shell irá expandir TMPDIR , mas se não estiver definido, /tmp será usado.
Veja o arquivo de saída.
cat "${TMPDIR:-/tmp}/dsub-test/output/out.txt"
dsub atualmente oferece suporte à API Cloud Life Sciences v2beta do Google Cloud e está desenvolvendo suporte para a API Batch do Google Cloud.
dsub oferece suporte à API v2beta com o provedor google-cls-v2 . google-cls-v2 é o provedor padrão atual. dsub fará a transição para tornar google-batch o padrão nas próximas versões.
As etapas para começar diferem um pouco, conforme indicado nas etapas abaixo:
Cadastre-se para uma conta do Google e crie um projeto.
Habilite as APIs:
v2beta (provedor: google-cls-v2 ):Habilite as APIs Cloud Life Sciences, Storage e Compute
batch (provedor: google-batch ):Habilite as APIs de lote, armazenamento e computação.
Forneça credenciais para que dsub possa chamar as APIs do Google:
gcloud auth application-default login
Crie um intervalo do Google Cloud Storage.
Os logs dsub e os arquivos de saída serão gravados em um bucket. Crie um bucket usando o navegador de armazenamento ou execute o utilitário de linha de comando gsutil, incluído no Cloud SDK.
gsutil mb gs://my-bucket
Altere my-bucket para um nome exclusivo que siga as convenções de nomenclatura de bucket.
(Por padrão, o bucket estará nos EUA, mas você pode alterar ou refinar a configuração de localização com a opção -l .)
Execute um trabalho dsub "Hello World" muito simples e aguarde a conclusão.
Para a API v2beta (provedor: google-cls-v2 ):
dsub
--provider google-cls-v2
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
Altere my-cloud-project para seu projeto do Google Cloud e my-bucket para o bucket que você criou acima.
Para a API batch (provedor: google-batch ):
dsub
--provider google-batch
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
Altere my-cloud-project para seu projeto do Google Cloud e my-bucket para o bucket que você criou acima.
A saída do comando de script será gravada no arquivo OUT especificado no Cloud Storage.
Veja o arquivo de saída.
gsutil cat gs://my-bucket/output/out.txt
Sempre que possível, dsub tenta oferecer suporte aos usuários para que possam desenvolver e testar localmente (para uma iteração mais rápida) e depois progredir para a execução em escala.
Para esse fim, dsub fornece vários "provedores de back-end", cada um dos quais implementa um ambiente de tempo de execução consistente. Os provedores atuais são:
Mais detalhes sobre o ambiente de execução implementado pelos provedores de back-end podem ser encontrados em provedores de back-end dsub.
google-cls-v2 e google-batch O provedor google-cls-v2 é baseado na API Cloud Life Sciences v2beta . Esta API é muito semelhante à sua antecessora, a API Genomics v2alpha1 . Detalhes das diferenças podem ser encontrados no Guia de Migração.
O provedor google-batch é baseado na API Cloud Batch. Detalhes do Cloud Life Sciences versus Batch podem ser encontrados neste Guia de migração.
dsub esconde em grande parte as diferenças entre as APIs, mas há algumas diferenças a serem observadas:
google-batch requer que os trabalhos sejam executados em uma região Os sinalizadores --regions e --zones para dsub especificam onde as tarefas devem ser executadas. O google-cls-v2 permite especificar uma multirregião como US , várias regiões ou várias zonas entre regiões. Com o provedor google-batch , você deve especificar uma região ou diversas zonas em uma única região.
dsubAs seções a seguir mostram como executar tarefas mais complexas.
Você pode fornecer um comando shell diretamente na linha de comando do dsub, como no exemplo hello acima.
Você também pode salvar seu script em um arquivo, como hello.sh . Então você pode executar:
dsub
...
--script hello.sh
Se o seu script tiver dependências que não estão armazenadas na imagem do Docker, você poderá transferi-las para o disco local. Consulte as instruções abaixo para trabalhar com arquivos e pastas de entrada e saída.
Para começar com mais facilidade, dsub usa uma imagem padrão do Ubuntu Docker. Esta imagem padrão pode mudar a qualquer momento em versões futuras, portanto, para fluxos de trabalho de produção reproduzíveis, você deve sempre especificar a imagem explicitamente.
Você pode alterar a imagem passando o sinalizador --image .
dsub
...
--image ubuntu:16.04
--script hello.sh
Nota: sua --image deve incluir o interpretador Bash Shell.
Para obter mais informações sobre como usar o sinalizador --image , consulte a seção de imagens em Scripts, Comandos e Docker
Você pode passar variáveis de ambiente para seu script usando o sinalizador --env .
dsub
...
--env MESSAGE=hello
--command 'echo ${MESSAGE}'
A variável de ambiente MESSAGE receberá o valor hello quando seu contêiner Docker for executado.
Seu script ou comando pode fazer referência à variável como qualquer outra variável de ambiente Linux, como ${MESSAGE} .
Certifique-se de colocar sua string de comando entre aspas simples e não aspas duplas. Se você usar aspas duplas, o comando será expandido em seu shell local antes de ser passado para o dsub. Para obter mais informações sobre como usar o sinalizador --command , consulte Scripts, comandos e Docker
Para definir diversas variáveis de ambiente, você pode repetir a sinalização:
--env VAR1=value1
--env VAR2=value2
Você também pode definir diversas variáveis, delimitadas por espaço, com um único sinalizador:
--env VAR1=value1 VAR2=value2
dsub imita o comportamento de um sistema de arquivos compartilhado usando caminhos de armazenamento em nuvem para arquivos e pastas de entrada e saída. Você especifica o caminho do bucket de armazenamento em nuvem. Os caminhos podem ser:
gs://my-bucket/my-filegs://my-bucket/my-foldergs://my-bucket/my-folder/*Consulte a documentação de entradas e saídas para obter mais detalhes.
Se o seu script espera ler arquivos de entrada locais que ainda não estão contidos na imagem do Docker, os arquivos deverão estar disponíveis no Google Cloud Storage.
Se o seu script tiver arquivos dependentes, você poderá disponibilizá-los para o seu script:
Para fazer upload dos arquivos para o Google Cloud Storage, você pode usar o navegador de armazenamento ou gsutil. Você também pode executar dados públicos ou compartilhados com sua conta de serviço, um endereço de e-mail que pode ser encontrado no Console do Google Cloud.
Para especificar arquivos de entrada e saída, use os sinalizadores --input e --output :
dsub
...
--input INPUT_FILE_1=gs://my-bucket/my-input-file-1
--input INPUT_FILE_2=gs://my-bucket/my-input-file-2
--output OUTPUT_FILE=gs://my-bucket/my-output-file
--command 'cat "${INPUT_FILE_1}" "${INPUT_FILE_2}" > "${OUTPUT_FILE}"'
Neste exemplo:
gs://my-bucket/my-input-file-1 para um caminho no disco de dados${INPUT_FILE_1}gs://my-bucket/my-input-file-2 para um caminho no disco de dados${INPUT_FILE_2} O --command pode referenciar os caminhos dos arquivos usando as variáveis de ambiente.
Também neste exemplo:
${OUTPUT_FILE}${OUTPUT_FILE} Após a conclusão do --command , o arquivo de saída será copiado para o caminho do bucket gs://my-bucket/my-output-file
Vários parâmetros --input e --output podem ser especificados e podem ser especificados em qualquer ordem.
Para copiar pastas em vez de arquivos, use os sinalizadores --input-recursive e output-recursive :
dsub
...
--input-recursive FOLDER=gs://my-bucket/my-folder
--command 'find ${FOLDER} -name "foo*"'
Vários parâmetros --input-recursive e --output-recursive podem ser especificados e podem ser especificados em qualquer ordem.
Embora a especificação explícita de entradas melhore o rastreamento da procedência dos seus dados, há casos em que talvez você não queira localizar explicitamente todas as entradas do Cloud Storage para sua VM de trabalho.
Por exemplo, se você tiver:
OU
OU
então você pode achar mais eficiente ou conveniente acessar esses dados montando somente leitura:
Os provedores google-cls-v2 e google-batch oferecem suporte a esses métodos de fornecimento de acesso a dados de recursos.
O provedor local oferece suporte à montagem de um diretório local de maneira semelhante para dar suporte ao seu desenvolvimento local.
Para que o provedor google-cls-v2 ou google-batch monte um bucket do Cloud Storage usando o Cloud Storage FUSE, use a sinalização de linha de comando --mount :
--mount RESOURCES=gs://mybucket
O bucket será montado somente leitura no contêiner Docker executando seu --script ou --command e o local disponibilizado por meio da variável de ambiente ${RESOURCES} . Dentro do seu script, você pode fazer referência ao caminho montado usando a variável de ambiente. Leia as principais diferenças de um sistema de arquivos POSIX e semântica antes de usar o Cloud Storage FUSE.
Para que o provedor google-cls-v2 ou google-batch monte um disco permanente que você pré-criou e preencheu, use o sinalizador de linha de comando --mount e o URL do disco de origem:
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/zones/your_disk_zone/disks/your-disk"
Para que o provedor google-cls-v2 ou google-batch monte um disco permanente criado a partir de uma imagem, use o sinalizador de linha de comando --mount e o URL da imagem de origem e o tamanho (em GB) do disco:
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/global/images/your-image 50"
A imagem será usada para criar um novo disco permanente, que será anexado a uma VM do Compute Engine. O disco será montado no contêiner Docker executando seu --script ou --command e o local disponibilizado pela variável de ambiente ${RESOURCES} . Dentro do seu script, você pode fazer referência ao caminho montado usando a variável de ambiente.
Para criar uma imagem, consulte Criando uma imagem personalizada.
local ) Para que o provedor local monte um diretório somente leitura, use o sinalizador de linha de comando --mount e um prefixo file:// :
--mount RESOURCES=file://path/to/my/dir
O diretório local será montado no contêiner Docker executando seu --script ou --command e o local será disponibilizado por meio da variável de ambiente ${RESOURCES} . Dentro do seu script, você pode fazer referência ao caminho montado usando a variável de ambiente.
As tarefas dsub executadas usando o provedor local usarão os recursos disponíveis em sua máquina local.
As tarefas dsub executadas usando os provedores google-cls-v2 ou google-batch podem aproveitar uma ampla variedade de opções de CPU, RAM, disco e acelerador de hardware (por exemplo, GPU).
Consulte a documentação dos Recursos de computação para obter detalhes.
Por padrão, dsub gera um job-id com o formato job-name--userid--timestamp onde o job-name é truncado em 10 caracteres e o timestamp tem o formato YYMMDD-HHMMSS-XX , exclusivo para centésimos de segundo . Se você estiver enviando vários trabalhos simultaneamente, ainda poderá se deparar com situações em que o job-id não seja exclusivo. Se você precisar de um job-id exclusivo para esta situação, poderá usar o parâmetro --unique-job-id .
Se o parâmetro --unique-job-id for definido, job-id será um UUID exclusivo de 32 caracteres criado por https://docs.python.org/3/library/uuid.html. Como alguns provedores exigem que o job-id comece com uma letra, dsub substituirá qualquer dígito inicial por uma letra de maneira que preserve a exclusividade.
Cada um dos exemplos acima demonstrou o envio de uma única tarefa com um único conjunto de variáveis, entradas e saídas. Se você tiver um lote de entradas e quiser executar a mesma operação sobre elas, dsub permite criar um trabalho em lote.
Em vez de chamar dsub repetidamente, você pode criar um arquivo de valores separados por tabulação (TSV) contendo as variáveis, entradas e saídas para cada tarefa e, em seguida, chamar dsub uma vez. O resultado será um único job-id com múltiplas tarefas. As tarefas serão agendadas e executadas de forma independente, mas poderão ser monitoradas e excluídas em grupo.
A primeira linha do arquivo TSV especifica os nomes e tipos dos parâmetros. Por exemplo:
--env SAMPLE_ID<tab>--input VCF_FILE<tab>--output OUTPUT_PATH
Cada linha de adição no arquivo deve fornecer os valores de variável, entrada e saída para cada tarefa. Cada linha além do cabeçalho representa os valores de uma tarefa separada.
Vários parâmetros --env , --input e --output podem ser especificados e podem ser especificados em qualquer ordem. Por exemplo:
--env SAMPLE<tab>--input A<tab>--input B<tab>--env REFNAME<tab>--output O
S1<tab>gs://path/A1.txt<tab>gs://path/B1.txt<tab>R1<tab>gs://path/O1.txt
S2<tab>gs://path/A2.txt<tab>gs://path/B2.txt<tab>R2<tab>gs://path/O2.txt
Passe o arquivo TSV para dsub usando o parâmetro --tasks . Este parâmetro aceita o caminho do arquivo e, opcionalmente, uma série de tarefas a serem processadas. O arquivo pode ser lido no sistema de arquivos local (na máquina da qual você está chamando dsub ) ou em um bucket no Google Cloud Storage (o nome do arquivo começa com "gs://").
Por exemplo, suponha que my-tasks.tsv contenha 101 linhas: um cabeçalho de uma linha e 100 linhas de parâmetros para execução de tarefas. Então:
dsub ... --tasks ./my-tasks.tsv
criará um trabalho com 100 tarefas, enquanto:
dsub ... --tasks ./my-tasks.tsv 1-10
criará um trabalho com 10 tarefas, uma para cada uma das linhas 2 a 11.
Os valores do intervalo de tarefas podem assumir qualquer uma das seguintes formas:
m indica enviar tarefa m (linha m+1)m- indica enviar todas as tarefas começando com a tarefa mmn indica enviar todas as tarefas de m a n (inclusive). O sinalizador --logging aponta para um local para arquivos de log de tarefas dsub . Para obter detalhes sobre como especificar seu caminho de log, consulte Log.
É possível esperar a conclusão de um trabalho antes de iniciar outro. Para obter detalhes, consulte controle de trabalho com dsub.
É possível que dsub tente novamente tarefas com falha automaticamente. Para obter detalhes, consulte tentativas com dsub.
Você pode adicionar rótulos personalizados a trabalhos e tarefas, o que permite monitorar e cancelar tarefas usando seus próprios identificadores. Além disso, com os provedores do Google, rotular uma tarefa rotulará os recursos de computação associados, como máquinas virtuais e discos.
Para obter mais detalhes, consulte Verificação de status e solução de problemas de trabalhos
O comando dstat exibe o status dos trabalhos:
dstat --provider google-cls-v2 --project my-cloud-project
Sem argumentos adicionais, dstat exibirá uma lista de trabalhos em execução para o USER atual.
Para exibir o status de um trabalho específico, use o sinalizador --jobs :
dstat --provider google-cls-v2 --project my-cloud-project --jobs job-id
Para um trabalho em lote, a saída listará todas as tarefas em execução .
Cada trabalho enviado pelo dsub recebe um conjunto de valores de metadados que podem ser usados para identificação e controle de trabalhos. Os metadados associados a cada trabalho incluem:
job-name : o padrão é o nome do seu arquivo de script ou a primeira palavra do seu comando de script; pode ser definido explicitamente com o parâmetro --name .user-id : o valor da variável de ambiente USER .job-id : identificador do job, que pode ser usado em chamadas para dstat e ddel para monitoramento e cancelamento do job respectivamente. Consulte Identificadores de trabalho para obter mais detalhes sobre o formato job-id .task-id : se o trabalho for enviado com o parâmetro --tasks , cada tarefa receberá um valor sequencial no formato "task -n ", onde n é baseado em 1.Observe que os valores de metadados do trabalho serão modificados para estar em conformidade com as "Restrições de rótulo" listadas no guia Verificação de status e solução de problemas de trabalhos.
Os metadados podem ser usados para cancelar um trabalho ou tarefas individuais dentro de um trabalho em lote.
Para obter mais detalhes, consulte Verificação de status e solução de problemas de trabalhos
Por padrão, dstat gera uma linha por tarefa. Se você estiver usando um trabalho em lote com muitas tarefas, poderá se beneficiar de --summary .
$ dstat --provider google-cls-v2 --project my-project --status '*' --summary
Job Name Status Task Count
------------- ------------- -------------
my-job-name RUNNING 2
my-job-name SUCCESS 1
Neste modo, dstat imprime uma linha por par (nome do trabalho, status da tarefa). Você pode ver rapidamente quantas tarefas foram concluídas, quantas ainda estão em execução e quantas falharam/cancelaram.
O comando ddel excluirá os trabalhos em execução.
Por padrão, apenas os trabalhos enviados pelo usuário atual serão excluídos. Use o sinalizador --users para especificar outros usuários ou '*' para todos os usuários.
Para excluir um trabalho em execução:
ddel --provider google-cls-v2 --project my-cloud-project --jobs job-id
Se o trabalho for em lote, todas as tarefas em execução serão excluídas.
Para excluir tarefas específicas:
ddel
--provider google-cls-v2
--project my-cloud-project
--jobs job-id
--tasks task-id1 task-id2
Para excluir todos os trabalhos em execução do usuário atual:
ddel --provider google-cls-v2 --project my-cloud-project --jobs '*'
Ao executar o comando dsub com o provedor google-cls-v2 ou google-batch , há dois conjuntos diferentes de credenciais a serem considerados:
pipelines.run() para executar seu comando/script em uma VM A conta usada para enviar a solicitação pipelines.run() normalmente é suas credenciais de usuário final. Você teria configurado isso executando:
gcloud auth application-default login
A conta usada na VM é uma conta de serviço. A imagem abaixo ilustra isso:
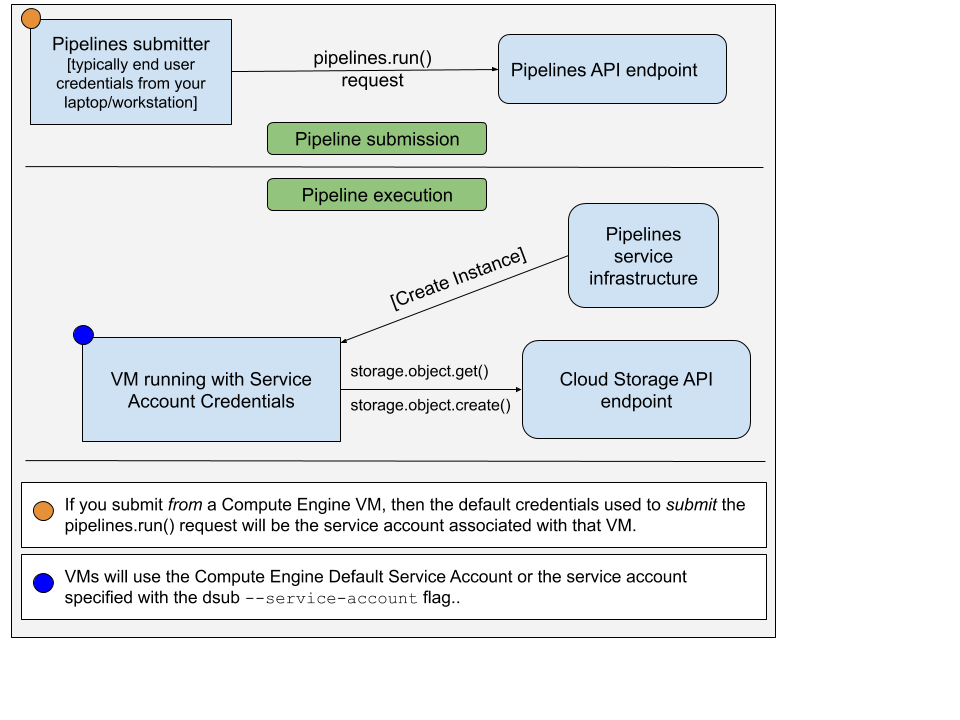
Por padrão, dsub usará a conta de serviço padrão do Compute Engine como conta de serviço autorizada na instância de VM. Você pode optar por especificar o endereço de e-mail de outra conta de serviço usando --service-account .
Por padrão, dsub concederá os seguintes escopos de acesso à conta de serviço:
Além disso, a API sempre adicionará este escopo:
Você pode optar por especificar escopos usando --scopes .
Embora seja simples usar a conta de serviço padrão, essa conta também possui amplos privilégios concedidos por padrão. Seguindo o Princípio do Menor Privilégio, você pode querer criar e usar uma conta de serviço que tenha apenas privilégios suficientes concedidos para executar seu comando/script dsub .
Para criar uma nova conta de serviço, siga as etapas abaixo:
Execute o comando gcloud iam service-accounts create . O endereço de e-mail da conta de serviço será [email protected] .
gcloud iam service-accounts create "sa-name"
Conceda acesso IAM em buckets, etc. à conta de serviço.
gsutil iam ch serviceAccount:[email protected]:roles/storage.objectAdmin gs://bucket-name
Atualize seu comando dsub para incluir --service-account
dsub
--service-account [email protected]
...
Veja os exemplos:
Veja mais documentação para:


