CQN
1.0.0
Uma reimplementação da Q-Network (CQN) grosseira para fina , um algoritmo RL baseado em valor com eficiência de amostra para controle contínuo, introduzido em:
Controle Contínuo com Aprendizado por Reforço Grosso a Fino
Younggyo Seo, Jafar Uruç, Stephen James
Nossa ideia principal é aprender agentes de RL que ampliam o espaço de ação contínua de maneira grosseira a fina, permitindo-nos treinar agentes de RL baseados em valor para controle contínuo com poucas ações discretas em cada nível.
Consulte a página do nosso projeto https://younggyo.me/cqn/ para obter mais informações.
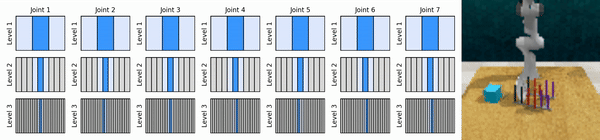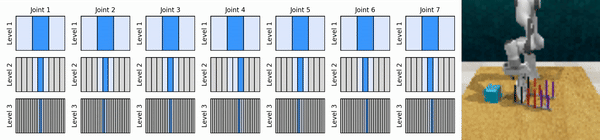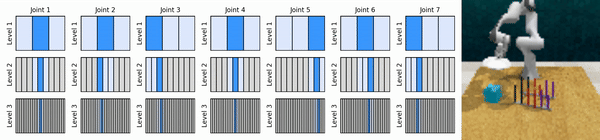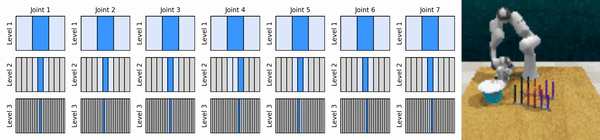
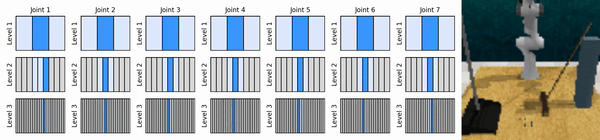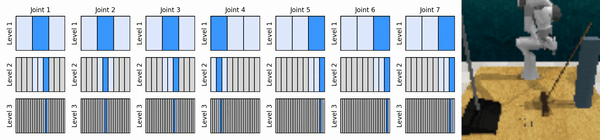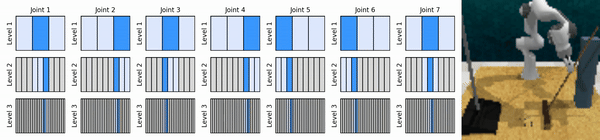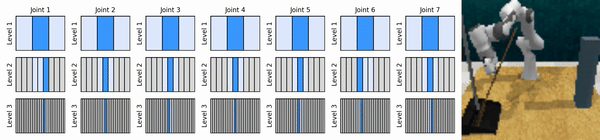
Instale o ambiente conda:
conda env create -f conda_env.yml
conda activate cqn
Instale RLBench e PyRep (devem ser usadas as versões mais recentes em 10 de julho de 2024). Siga o guia nos repositórios originais para (1) instalar RLBench e PyRep e (2) ativar o modo headless. (Consulte README no RLBench e Robobase para obter informações sobre como instalar o RLBench.)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
Demonstrações pré-coleção
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
Execute experimentos (CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Execute experimentos de linha de base (DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Execute experimentos:
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
Aviso: CQN não é extensivamente testado em DMC
Este repositório é baseado na implementação pública do DrQ-v2
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


