lorax
v0.12.0: Multi-LoRA prefix caching, fp8 kv cache, Mllama, function calling

LoRAX: servidor de inferência Multi-LoRA que pode ser dimensionado para milhares de LLMs ajustados
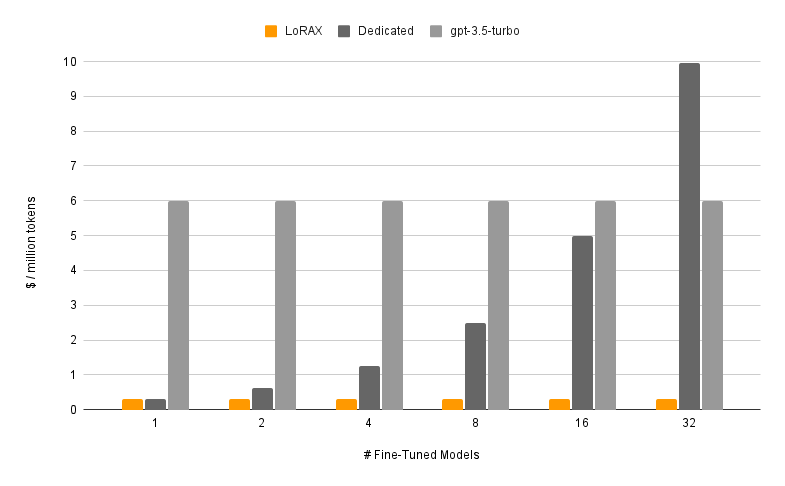
LoRAX (LoRA eXchange) é uma estrutura que permite aos usuários servir milhares de modelos ajustados em uma única GPU, reduzindo drasticamente o custo de serviço sem comprometer o rendimento ou a latência.
Índice
Características
Modelos
?Começando
Requisitos
Inicie o servidor LoRAX
Solicitar via API REST
Solicitar via cliente Python
Bate-papo via API OpenAI
Próximas etapas
Agradecimentos
Roteiro
Carregamento dinâmico do adaptador: inclua qualquer adaptador LoRA ajustado do HuggingFace, Predibase ou qualquer sistema de arquivos em sua solicitação, ele será carregado na hora certa, sem bloquear solicitações simultâneas. Combine adaptadores por solicitação para criar conjuntos poderosos instantaneamente.
Lote Contínuo Heterogêneo: agrupa solicitações de adaptadores diferentes no mesmo lote, mantendo a latência e a taxa de transferência quase constantes com o número de adaptadores simultâneos.
Agendamento de troca de adaptador: pré-busca e descarrega adaptadores de forma assíncrona entre a GPU e a memória da CPU, agenda o lote de solicitações para otimizar o rendimento agregado do sistema.
Inferência otimizada: otimizações de alto rendimento e baixa latência, incluindo paralelismo de tensor, kernels CUDA pré-compilados (atenção flash, atenção paginada, SGMV), quantização, streaming de token.
Imagens Docker pré-construídas prontas para produção , gráficos Helm para Kubernetes, métricas Prometheus e rastreamento distribuído com Open Telemetry. API compatível com OpenAI que oferece suporte a conversas de bate-papo multiturno. Adaptadores privados por meio de isolamento de locatário por solicitação. Saída estruturada (modo JSON).
? Gratuito para uso comercial: Licença Apache 2.0. Já disse o suficiente?
Servir um modelo ajustado com LoRAX consiste em dois componentes:
Modelo Base: modelo grande pré-treinado compartilhado por todos os adaptadores.
Adaptador: pesos de adaptador específicos da tarefa carregados dinamicamente por solicitação.
LoRAX oferece suporte a vários modelos de linguagem grande como modelo base, incluindo Llama (incluindo CodeLlama), Mistral (incluindo Zephyr) e Qwen. Consulte Arquiteturas Suportadas para obter uma lista completa de modelos básicos suportados.
Os modelos básicos podem ser carregados em fp16 ou quantizados com bitsandbytes , GPT-Q ou AWQ.
Os adaptadores suportados incluem adaptadores LoRA treinados usando as bibliotecas PEFT e Ludwig. Qualquer uma das camadas lineares do modelo pode ser adaptada via LoRA e carregada no LoRAX.
Recomendamos começar com nossa imagem Docker pré-construída para evitar a compilação de kernels CUDA personalizados e outras dependências.
Os requisitos mínimos de sistema necessários para executar o LoRAX incluem:
GPU Nvidia (geração Ampere ou superior)
Drivers de dispositivos compatíveis com CUDA 11.8 e superiores
SO Linux
Docker (para este guia)
Instale nvidia-container-toolkit então
sudo systemctl daemon-reload
sudo systemctl restart docker
modelo=mistralai/Mistral-7B-Instruct-v0.1
volume=$PWD/dados
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/dados
ghcr.io/predibase/lorax:main --model-id $modelPara obter um tutorial completo, incluindo streaming de token e o cliente Python, consulte Conceitos básicos - Docker.
Base de prompt LLM:
enrolar 127.0.0.1:8080/gerar
-X POSTAR
-d '{ "inputs": "[INST] Natalia vendeu clipes para 48 de seus amigos em abril, e depois vendeu metade desses clipes em maio. Quantos clipes Natalia vendeu no total em abril e maio? [/INST] ", "parâmetros": { "max_new_tokens": 64 } }'
-H 'Tipo de conteúdo: aplicativo/json'Solicite um adaptador LoRA:
enrolar 127.0.0.1:8080/gerar
-X POSTAR
-d '{ "inputs": "[INST] Natalia vendeu clipes para 48 de seus amigos em abril, e depois vendeu metade desses clipes em maio. Quantos clipes Natalia vendeu no total em abril e maio? [/INST] ", "parâmetros": { "max_new_tokens": 64, "adapter_id": "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k" } }'
-H 'Tipo de conteúdo: aplicativo/json'Consulte Referência - API REST para obter detalhes completos.
Instalar:
pip instalar cliente lorax
Correr:
from lorax import Clientclient = Client("http://127.0.0.1:8080")# Prompt the base LLMprompt = "[INST] Natalia vendeu clipes para 48 de seus amigos em abril e depois vendeu metade desses clipes em maio . Quantos clipes Natalia vendeu no total em abril e maio? max_new_tokens=64).generated_text)# Solicita um adaptador LoRAadapter_id = "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"print(client.generate(prompt, max_new_tokens=64, adapter_id=adapter_id).generated_text )Consulte Referência - Cliente Python para obter detalhes completos.
Para outras maneiras de executar o LoRAX, consulte Primeiros passos - Kubernetes, Primeiros passos - SkyPilot e Primeiros passos - Local.
LoRAX oferece suporte a conversas de bate-papo multiturno combinadas com carregamento dinâmico de adaptador por meio de uma API compatível com OpenAI. Basta especificar qualquer adaptador como parâmetro model .
de importação openai OpenAIclient = OpenAI(api_key="EMPTY",base_url="http://127.0.0.1:8080/v1",
)resp = client.chat.completions.create(model="alignment-handbook/zephyr-7b-dpo-lora",messages=[
{"role": "system","content": "Você é um chatbot amigável que sempre responde no estilo de um pirata",
},
{"role": "user", "content": "Quantos helicópteros um humano pode comer de uma só vez?"},
],max_tokens=100,
)print("Resposta:", resp.choices[0].message.content)Consulte API compatível com OpenAI para obter detalhes.
Aqui estão alguns outros modelos interessantes do Mistral-7B ajustados para experimentar:
alinhamento-handbook/zephyr-7b-dpo-lora: Mistral-7b ajustado no conjunto de dados Zephyr-7B com DPO.
IlyaGusev/saiga_mistral_7b_lora: chatbot russo baseado em Open-Orca/Mistral-7B-OpenOrca .
Undi95/Mistral-7B-roleplay_alpaca-lora: Ajustado usando prompts de dramatização.
Você pode encontrar mais adaptadores LoRA aqui ou tentar ajustar o seu próprio com PEFT ou Ludwig.
LoRAX é construído sobre a inferência de geração de texto do HuggingFace, bifurcada a partir da v0.9.4 (Apache 2.0).
Gostaríamos também de agradecer a Punica por seu trabalho no kernel SGMV, que é usado para acelerar a inferência de vários adaptadores sob carga pesada.
Nosso roteiro é rastreado aqui.


