SOLIDER
1.0.0

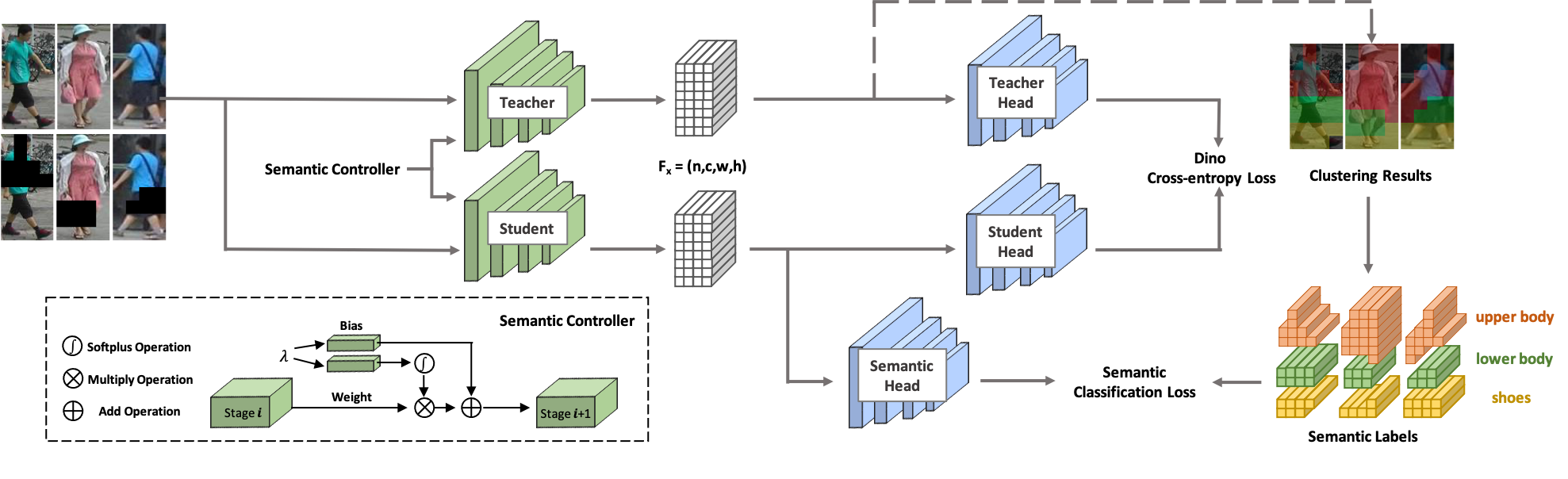
Bem-vindo ao SOLIDER ! SOLIDER é uma estrutura de aprendizagem auto-supervisionada semântica controlável para aprender representações humanas gerais a partir de imagens humanas massivas não rotuladas que podem beneficiar ao máximo as tarefas centradas no ser humano. Ao contrário dos métodos de aprendizagem auto-supervisionados existentes, o conhecimento prévio de imagens humanas é utilizado no SOLIDER para construir rótulos pseudo-semânticos e importar mais informações semânticas para a representação aprendida. Enquanto isso, diferentes tarefas posteriores sempre exigem proporções diferentes de informações semânticas e informações de aparência, e uma única representação aprendida não pode atender a todos os requisitos. Para resolver este problema, SOLIDER introduz uma rede condicional com um controlador semântico, que pode atender a diferentes necessidades de tarefas downstream. Para obter mais detalhes, consulte nosso artigo Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks.
Esta base de código foi desenvolvida com python versão 3.7, PyTorch versão 1.7.1, CUDA 10.1 e torchvision 0.8.2.
Usamos LUPerson como dados de treinamento, que consiste em imagens humanas não rotuladas. Baixe LUPerson de seu link oficial e descompacte-o.
sh run_solider.shsh run_dino.sh
sh resume_solider.shHá uma demonstração para executar o modelo SOLIDER treinado, que pode ser incorporado à inferência ou ao ajuste fino da tarefa downstream.
python demo.pyUsamos o Swin-Transformer como nossa espinha dorsal, o que apresenta grandes vantagens em muitas tarefas de CV.
| Tarefa | Conjunto de dados | Swin minúsculo (Link) | Swin pequeno (Link) | Base Swin (Link) |
|---|---|---|---|---|
| Reidentificação de Pessoa (mAP/R1) sem reclassificação | Mercado1501 | 91,6/96,1 | 93,3/96,6 | 93,9/96,9 |
| MSMT17 | 67,4/85,9 | 76,9/90,8 | 77,1/90,7 | |
| Reidentificação de Pessoa (mAP/R1) com reclassificação | Mercado1501 | 95,3/96,6 | 95,4/96,4 | 95,6/96,7 |
| MSMT17 | 81,5/89,2 | 86,5/91,7 | 86,5/91,7 | |
| Reconhecimento de atributos (mA) | PETA_ZS | 74,37 | 76,21 | 76,43 |
| RAP_ZS | 74,23 | 75,95 | 76,42 | |
| PA100K | 84,14 | 86,25 | 86,37 | |
| Pesquisa de pessoa (mAP/R1) | CUHK-SYSU | 94,9/95,7 | 95,5/95,8 | 94,9/95,5 |
| PRW | 56,8/86,8 | 59,8/86,7 | 59,7/86,8 | |
| Detecção de pedestres (MR-2) | Pessoas da cidade | 10,3/40,8 | 10,0/39,2 | 9,7/39,4 |
| Análise Humana (mIOU) | LÁBIO | 57,52 | 60,21 | 60,50 |
| Estimativa de pose (AP/AR) | COCO | 74,4/79,6 | 76,3/81,3 | 76,6/81,5 |
Nossa implementação é baseada principalmente nas seguintes bases de código. Agradecemos com gratidão aos autores por seus maravilhosos trabalhos.
Se você usa o SOLIDER em sua pesquisa, cite nosso trabalho usando a seguinte entrada do BibTeX:
@inproceedings{chen2023beyond,
title={Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks},
author={Weihua Chen and Xianzhe Xu and Jian Jia and Hao Luo and Yaohua Wang and Fan Wang and Rong Jin and Xiuyu Sun},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023},
}


