gpt neox
GPT-NeoX 2.0
Este repositório registra a biblioteca da EleutherAI para treinar modelos de linguagem em larga escala em GPUs. Nossa estrutura atual é baseada no modelo de linguagem Megatron da NVIDIA e foi aprimorada com técnicas do DeepSpeed, bem como algumas otimizações inovadoras. Nosso objetivo é tornar este repositório um local centralizado e acessível para reunir técnicas para treinar modelos de linguagem autoregressivos em larga escala e acelerar a pesquisa em treinamento em larga escala. Esta biblioteca é amplamente utilizada em laboratórios acadêmicos, industriais e governamentais, inclusive por pesquisadores do Oak Ridge National Lab, CarperAI, Stability AI, Together.ai, Korea University, Carnegie Mellon University e University of Tokyo, entre outros. Exclusivamente entre bibliotecas semelhantes, GPT-NeoX suporta uma ampla variedade de sistemas e hardwares, incluindo lançamento via Slurm, MPI e IBM Job Step Manager, e foi executado em escala em AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI e outros.
Se você não deseja treinar modelos com bilhões de parâmetros do zero, provavelmente esta é a biblioteca errada para usar. Para necessidades genéricas de inferência, recomendamos que você use a biblioteca transformers Hugging Face, que oferece suporte a modelos GPT-NeoX.
GPT-NeoX aproveita muitos dos mesmos recursos e tecnologias da popular biblioteca Megatron-DeepSpeed, mas com usabilidade substancialmente aumentada e novas otimizações. Os principais recursos incluem:
[09/09/2024] Agora oferecemos suporte ao aprendizado de preferências via DPO, KTO e modelagem de recompensa
[09/09/2024] Agora oferecemos suporte à integração com Comet ML, uma plataforma de monitoramento de aprendizado de máquina
[21/05/2024] Agora oferecemos suporte a RWKV com paralelismo de pipeline! Veja os PRs para RWKV e RWKV+pipeline
[21/03/2024] Agora oferecemos suporte à Mistura de Especialistas (MoE)
[17/03/2024] Agora oferecemos suporte a GPUs AMD MI250X
[15/03/2024] Agora oferecemos suporte ao Mamba com paralelismo de tensor! Veja o PR
[10/08/2023] Agora oferecemos suporte para checkpoint com AWS S3! Ative com a opção de configuração s3_path (para mais detalhes, consulte o PR)
[20/09/2023] A partir de # 1035, descontinuamos o Flash Attention 0.xe 1.x e migramos o suporte para o Flash Attention 2.x. Não acreditamos que isso causará problemas, mas se você tiver um caso de uso específico que requer suporte a flash antigo usando o GPT-NeoX mais recente, levante um problema.
[10/08/2023] Temos suporte experimental para LLaMA 2 e Flash Attention v2 em nosso projeto math-lm que será lançado ainda este mês.
[17/05/2023] Depois de corrigir alguns bugs diversos, agora oferecemos suporte total ao bf16.
[11/04/2023] Atualizamos nossa implementação de Flash Attention para agora oferecer suporte a embeddings posicionais de Alibi.
[09/03/2023] Lançamos o GPT-NeoX 2.0.0, uma versão atualizada construída no DeepSpeed mais recente que será sincronizada regularmente daqui para frente.
Antes de 09/03/2023, GPT-NeoX contava com DeeperSpeed, que era baseado em uma versão antiga do DeepSpeed (0.3.15). Para migrar para a versão upstream mais recente do DeepSpeed e, ao mesmo tempo, permitir que os usuários acessem as versões antigas do GPT-NeoX e DeeperSpeed, introduzimos dois lançamentos versionados para ambas as bibliotecas:
Esta base de código foi desenvolvida e testada principalmente para Python 3.8-3.10 e PyTorch 1.8-2.0. Este não é um requisito estrito e outras versões e combinações de bibliotecas podem funcionar.
Para instalar as dependências básicas restantes, execute:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometda raiz do repositório.
Aviso
Nossa base de código depende do DeeperSpeed, nosso fork da biblioteca DeepSpeed com algumas alterações adicionais. Recomendamos fortemente o uso do Anaconda, uma máquina virtual ou alguma outra forma de isolamento de ambiente antes de continuar. Não fazer isso pode causar a quebra de outros repositórios que dependem do DeepSpeed.
Agora oferecemos suporte a GPUs AMD (MI100, MI250X) por meio da compilação JIT de kernel fundido. Kernels fundidos serão compilados e carregados conforme necessário. Para evitar espera durante o lançamento do trabalho, você também pode fazer o seguinte para a pré-construção manual:
python
from megatron . fused_kernels import load
load () Isso adaptará automaticamente o processo de construção de diferentes fornecedores de GPU (AMD, NVIDIA) sem alterações de código específicas da plataforma. Para testar ainda mais os kernels fundidos usando pytest , use pytest tests/model/test_fused_kernels.py
Para usar Flash-Attention, instale as dependências adicionais em ./requirements/requirements-flashattention.txt e defina o tipo de atenção em sua configuração de acordo (consulte configurações). Isso pode fornecer acelerações significativas em relação à atenção regular em determinadas arquiteturas de GPU, incluindo GPUs Ampere (como A100s); veja o repositório para mais detalhes.
NeoX e Deep(er)Speed oferecem suporte ao treinamento em vários nós diferentes e você tem a opção de usar uma variedade de iniciadores diferentes para orquestrar trabalhos de vários nós.
Em geral, é necessário haver um "hostfile" em algum lugar acessível com o formato:
node1_ip slots=8
node2_ip slots=8 onde a primeira coluna contém o endereço IP de cada nó em sua configuração e o número de slots é o número de GPUs às quais o nó tem acesso. Na sua configuração você deve passar o caminho para o hostfile com "hostfile": "/path/to/hostfile" . Alternativamente, o caminho para o arquivo host pode estar na variável de ambiente DLTS_HOSTFILE .
pdsh é o inicializador padrão e, se você estiver usando pdsh , tudo o que você deve fazer (além de garantir que o pdsh esteja instalado em seu ambiente) é definir {"launcher": "pdsh"} em seus arquivos de configuração.
Se estiver usando MPI, você deve especificar a biblioteca MPI (DeepSpeed/GPT-NeoX atualmente suporta mvapich , openmpi , mpich e impi , embora openmpi seja o mais comumente usado e testado), bem como passar o sinalizador deepspeed_mpi em seu arquivo de configuração:
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} Com seu ambiente configurado corretamente e os arquivos de configuração corretos, você pode usar deepy.py como um script python normal e iniciar (por exemplo) um trabalho de treinamento com:
python3 deepy.py train.py /path/to/configs/my_model.yml
Usar Slurm pode ser um pouco mais complicado. Assim como no MPI, você deve adicionar o seguinte à sua configuração:
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} Se você não tiver acesso ssh aos nós de computação em seu cluster Slurm, será necessário adicionar {"no_ssh_check": true}
Há muitos casos em que as opções de inicialização padrão acima não são suficientes
Nesses casos, você precisará modificar o utilitário DeepSpeed multinode runner para oferecer suporte ao seu caso de uso. Em termos gerais, essas melhorias se enquadram em duas categorias:
Nesse caso, você deve adicionar uma nova classe de executor multinode a deepspeed/launcher/multinode_runner.py e expô-la como uma opção de configuração no GPT-NeoX. Exemplos de como fizemos isso para o Summit JSRun estão neste commit DeeperSpeed e neste commit GPT-NeoX, respectivamente.
Encontramos muitos casos em que desejamos modificar o comando MPI/Slurm run para uma otimização ou para depurar (por exemplo, para modificar a ligação da CPU Slurm srun ou para marcar logs MPI com a classificação). Neste caso, você deve modificar o comando run da classe runner multinode sob seu método get_cmd (por exemplo, mpirun_cmd para OpenMPI). Exemplos de como fizemos isso para fornecer comandos de execução otimizados e com classificação de classificação usando Slurm e OpenMPI para o cluster Stability estão neste branch DeeperSpeed
Em geral você não poderá ter um único arquivo host fixo, então você precisa ter um script para gerar um dinamicamente quando seu trabalho for iniciado. Um exemplo de script para gerar dinamicamente um arquivo host usando Slurm e 8 GPUs por nó é:
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID e $SLURM_NODELIST sendo variáveis de ambiente que o Slurm criará para você. Consulte a documentação do sbatch para obter uma lista completa de variáveis de ambiente Slurm disponíveis definidas no momento da criação do trabalho.
Em seguida, você pode criar um script em lote para iniciar seu trabalho GPT-NeoX. Um script sbatch básico em um cluster baseado em Slurm com 8 GPUs por nó seria assim:
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
Você pode então iniciar uma corrida de treinamento com sbatch my_sbatch_script.sh
Também fornecemos uma configuração Dockerfile e docker-compose se você preferir executar o NeoX em um contêiner.
Os requisitos para executar o contêiner são ter drivers de GPU apropriados, uma instalação atualizada do Docker e nvidia-container-toolkit instalado. Para testar se sua instalação está boa, você pode usar a "carga de trabalho de amostra", que é:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Desde que seja executado, você precisa exportar NEOX_DATA_PATH e NEOX_CHECKPOINT_PATH em seu ambiente para especificar seu diretório de dados e diretório para armazenar e carregar pontos de verificação:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
E então, no diretório gpt-neox, você pode construir a imagem e executar um shell em um contêiner com
docker compose run gpt-neox bash
Após a construção, você deverá ser capaz de fazer isso:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
Para um trabalho de longa duração, você deve executar
docker compose up -d
para executar o contêiner no modo desanexado e, em seguida, em uma sessão de terminal separada, execute
docker compose exec gpt-neox bash
Você pode então executar qualquer trabalho que desejar dentro do contêiner.
As preocupações ao executar por um longo período ou no modo independente incluem
Se preferir executar a imagem do contêiner pré-construída no dockerhub, você pode executar os comandos docker compose com -f docker-compose-dockerhub.yml , por exemplo,
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
Todas as funcionalidades devem ser iniciadas usando deepy.py , um wrapper em torno do iniciador deepspeed .
Atualmente oferecemos três funções principais:
train.py é usado para treinamento e ajuste de modelos.eval.py é usado para avaliar um modelo treinado usando o equipamento de avaliação de modelo de linguagem.generate.py é usado para obter uma amostra de texto de um modelo treinado.que pode ser iniciado com:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]Por exemplo, para iniciar o treinamento você pode executar
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlPara obter mais detalhes sobre cada ponto de entrada, consulte Treinamento e Ajuste Fino, Inferência e Avaliação respectivamente.
Os parâmetros GPT-NeoX são definidos em um arquivo de configuração YAML que é passado para o iniciador deepy.py. Fornecemos alguns exemplos de arquivos .yml nas configurações, mostrando uma ampla gama de recursos e tamanhos de modelo.
Esses arquivos geralmente estão completos, mas não são os ideais. Por exemplo, dependendo da configuração específica da sua GPU, pode ser necessário alterar algumas configurações, como pipe-parallel-size , model-parallel-size para aumentar ou diminuir o grau de paralelização, train_micro_batch_size_per_gpu ou gradient-accumulation-steps para modificar o tamanho do lote configurações relacionadas ou o ditado zero_optimization para modificar como os estados do otimizador são paralelizados entre os trabalhadores.
Para um guia mais detalhado sobre os recursos disponíveis e como configurá-los, consulte o README de configuração e para documentação de todos os argumentos possíveis, consulte configs/neox_arguments.md.
GPT-NeoX inclui várias implementações especializadas para MoE. Para selecionar entre eles, especifique moe_type de megablocks (padrão) ou deepspeed .
Ambos são baseados na estrutura de paralelismo DeepSpeed MoE, que suporta paralelismo de dados tensores-especialistas. Ambos permitem que você alterne entre drop-token e dropless (padrão, e é para isso que o Megablocks foi projetado). O roteamento Sinkhorn estará disponível em breve!
Para obter um exemplo de configuração básica completa, consulte configs/125M-dmoe.yml (para Megablocks dropless) ou configs/125M-moe.yml.
A maioria dos argumentos de configuração relacionados ao MoE são prefixados com moe . Alguns parâmetros de configuração comuns e seus padrões são os seguintes:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed pode ser configurado ainda mais com o seguinte:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
Uma camada MoE está presente em todas as camadas do transformador expert_interval , incluindo a primeira, portanto, com 12 camadas no total:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
Os especialistas estariam nestas camadas:
0, 2, 4, 6, 8, 10
Por padrão, usamos paralelismo de dados especializados, portanto, qualquer paralelismo de tensor disponível ( model_parallel_size ) será usado para roteamento especializado. Por exemplo, dado o seguinte:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
Com 32 GPUs, o comportamento será semelhante a:
expert_parallel_size == model_parallel_size . Definir enable_expert_tensor_parallelism ativa o paralelismo tensor-expert-data (TED). A maneira de interpretar o acima seria então:
expert_parallel_size == 1 ou model_parallel_size == 1 .Portanto observe que DP deve ser divisível por (MP*EP). Para mais detalhes, consulte o documento TED.
O paralelismo de pipeline ainda não é compatível. Em breve!
Vários conjuntos de dados pré-configurados estão disponíveis, incluindo a maioria dos componentes da Pile, bem como o próprio conjunto de trens da Pile, para tokenização direta usando o ponto de entrada prepare_data.py .
Por exemplo, para baixar e tokenizar o conjunto de dados enwik8 com o Tokenizer GPT2, salvando-os em ./data você pode executar:
python prepare_data.py -d ./data
ou um único fragmento da pilha ( pile_subset ) com o tokenizer GPT-NeoX-20B (supondo que você o tenha salvo em ./20B_checkpoints/20B_tokenizer.json ):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
Os dados tokenizados serão salvos em dois arquivos: [data-dir]/[dataset-name]/[dataset-name]_text_document.bin e [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . Você precisará adicionar o prefixo que ambos os arquivos compartilham ao arquivo de configuração de treinamento no campo data-path . EX.:
" data-path " : " ./data/enwik8/enwik8_text_document " , Para preparar seu próprio conjunto de dados para treinamento com dados personalizados, formate-o como um arquivo grande no formato jsonl, com cada item na lista de dicionários sendo um documento separado. O texto do documento deve ser agrupado em uma chave JSON, ou seja, "text" . Quaisquer dados auxiliares armazenados em outros campos não serão utilizados.
Em seguida, certifique-se de baixar o vocabulário do tokenizer GPT2 e mesclar os arquivos dos seguintes links:
Ou use o tokenizer 20B (para o qual é necessário apenas um único arquivo Vocab):
(como alternativa, você pode fornecer qualquer arquivo tokenizer que possa ser carregado pela biblioteca de tokenizers do Hugging Face com o comando Tokenizer.from_pretrained() )
Agora você pode pretokenizar seus dados usando tools/datasets/preprocess_data.py , cujos argumentos são detalhados abaixo:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
Por exemplo:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodVocê então executaria o treinamento com as seguintes configurações adicionadas ao seu arquivo de configuração:
" data-path " : " data/mydataset_text_document " , O treinamento é iniciado usando deepy.py , um wrapper em torno do iniciador do DeepSpeed, que inicia o mesmo script em paralelo em muitas GPUs/nós.
O padrão geral de uso é:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...Você pode passar um número arbitrário de configurações que serão mescladas em tempo de execução.
Você também pode, opcionalmente, passar um prefixo de configuração, que assumirá que todas as suas configurações estão na mesma pasta e anexará esse prefixo ao caminho.
Por exemplo:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml Isso implantará o script train.py em todos os nós com um processo por GPU. Os nós de trabalho e o número de GPUs são especificados no arquivo /job/hostfile (consulte a documentação do parâmetro) ou podem simplesmente ser passados como o argumento num_gpus se estiver executando em uma configuração de nó único.
Embora isso não seja estritamente necessário, achamos útil definir os parâmetros do modelo em um arquivo de configuração (por exemplo, configs/125M.yml ) e os parâmetros do caminho de dados em outro (por exemplo, configs/local_setup.yml ).
GPT-NeoX-20B é um modelo de linguagem autoregressiva de 20 bilhões de parâmetros treinado na Pile. Detalhes técnicos sobre o GPT-NeoX-20B podem ser encontrados no artigo associado. O arquivo de configuração para este modelo está disponível em ./configs/20B.yml e incluído nos links de download abaixo.
Pesos finos - (sem estados de otimização, para inferência ou ajuste fino, 39 GB)
Para fazer download da linha de comando para uma pasta chamada 20B_checkpoints , use o seguinte comando:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsPesos totais - (incluindo estados do otimizador, 268 GB)
Para fazer download da linha de comando para uma pasta chamada 20B_checkpoints , use o seguinte comando:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsOs pesos podem ser baixados alternativamente usando um cliente BitTorrent. Arquivos torrent podem ser baixados aqui: pesos finos, pesos completos.
Também temos 150 pontos de verificação salvos durante o treinamento, um a cada 1.000 passos. Estamos trabalhando para descobrir a melhor forma de atendê-los em grande escala, mas enquanto isso, as pessoas interessadas em trabalhar com os pontos de verificação parcialmente treinados podem nos enviar um e-mail para [email protected] para providenciar o acesso.
O Pythia Scaling Suite é um conjunto de modelos que varia de 70M de parâmetros a 12B de parâmetros treinados na Pile, destinado a promover pesquisas sobre interpretabilidade e dinâmica de treinamento de grandes modelos de linguagem. Mais detalhes sobre o projeto e links para os modelos podem ser encontrados no artigo e no GitHub do projeto.
O Projeto Poliglota é um esforço para treinar modelos poderosos de idiomas pré-treinados que não o inglês para promover a acessibilidade dessa tecnologia a pesquisadores fora das potências dominantes do aprendizado de máquina. A EleutherAI treinou e lançou modelos de idioma coreano com parâmetros de 1,3B, 3,8B e 5,8B, o maior dos quais supera todos os outros modelos de idioma disponíveis publicamente em tarefas de idioma coreano. Mais detalhes sobre o projeto e links para os modelos podem ser encontrados aqui.
Para a maioria dos usos, recomendamos a implantação de modelos treinados usando a biblioteca GPT-NeoX por meio da biblioteca Hugging Face Transformers, que é melhor otimizada para inferência.
Oferecemos suporte a três tipos de geração a partir de um modelo pré-treinado:
Todos os três tipos de geração de texto podem ser iniciados via python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml com os valores apropriados definidos em configs/text_generation.yml .
GPT-NeoX oferece suporte à avaliação em tarefas posteriores por meio do equipamento de avaliação de modelo de linguagem.
Para avaliar um modelo treinado no equipamento de avaliação, basta executar:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn onde --eval_tasks é uma lista de tarefas de avaliação seguidas de espaços, por exemplo --eval_tasks lambada hellaswag piqa sciq . Para obter detalhes de todas as tarefas disponíveis, consulte o repositório lm-evaluation-harness.
O GPT-NeoX é fortemente otimizado apenas para treinamento, e os pontos de verificação do modelo GPT-NeoX não são compatíveis imediatamente com outras bibliotecas de aprendizado profundo. Para tornar os modelos facilmente carregáveis e compartilháveis com os usuários finais, e para posterior exportação para várias outras estruturas, o GPT-NeoX oferece suporte à conversão de pontos de verificação para o formato Hugging Face Transformers.
Embora o NeoX suporte uma série de configurações arquitetônicas diferentes, incluindo embeddings posicionais AliBi, nem todas essas configurações são mapeadas de forma limpa nas configurações suportadas nos Hugging Face Transformers.
NeoX suporta exportação de modelos compatíveis para as seguintes arquiteturas:
O treinamento de um modelo que não se encaixa perfeitamente em uma dessas arquiteturas do Hugging Face Transformers exigirá a gravação de código de modelagem personalizado para o modelo exportado.
Para converter um ponto de verificação da biblioteca GPT-NeoX para o formato carregável Hugging Face, execute:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}Em seguida, para fazer upload de um modelo para o Hugging Face Hub, execute:
huggingface-cli login
python ./tools/ckpts/upload.pye insira as informações solicitadas, incluindo token de usuário do hub HF.
NeoX fornece vários utilitários para converter um ponto de verificação de modelo pré-treinado em um formato que pode ser treinado na biblioteca.
Os seguintes modelos ou famílias de modelos podem ser carregados no GPT-NeoX:
Fornecemos dois utilitários para conversão de dois formatos de checkpoint diferentes em um formato compatível com GPT-NeoX.
Para converter um ponto de verificação Llama 1 ou Llama 2 distribuído pela Meta AI de seu formato de arquivo original (para download aqui ou aqui) na biblioteca GPT-NeoX, execute
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
Para converter de um modelo Hugging Face em um modelo NeoX carregável, execute tools/ckpts/convert_hf_to_sequential.py . Consulte a documentação desse arquivo para obter mais opções.
Além de armazenar logs localmente, oferecemos suporte integrado para duas estruturas populares de monitoramento de experimentos: Weights & Biases, TensorBoard e Comet
Weights & Biases para registrar nossos experimentos é uma plataforma de monitoramento de aprendizado de máquina. Para usar o wandb para monitorar seus experimentos gpt-neox:
wandb login - suas corridas serão registradas automaticamente../requirements/requirements-wandb.txt . Um exemplo de configuração é fornecido em ./configs/local_setup_wandb.yml .wandb_group permite nomear o grupo de execução e wandb_team permite atribuir suas execuções a uma organização ou conta de equipe. Um exemplo de configuração é fornecido em ./configs/local_setup_wandb.yml . Oferecemos suporte ao uso do TensorBoard por meio do campo tensorboard-dir . As dependências necessárias para o monitoramento do TensorBoard podem ser encontradas e instaladas em ./requirements/requirements-tensorboard.txt .
Comet é uma plataforma de monitoramento de aprendizado de máquina. Para usar o cometa para monitorar seus experimentos gpt-neox:
comet login ou passando export COMET_API_KEY=<your-key-here>comet_ml e quaisquer bibliotecas de dependência via pip install -r requirements/requirements-comet.txtuse_comet: True . Você também pode personalizar onde os dados estão sendo registrados com comet_workspace e comet_project . Um exemplo completo de configuração com cometa habilitado é fornecido em configs/local_setup_comet.yml . Se precisar fornecer um arquivo host para uso com o iniciador DeepSpeed baseado em MPI, você pode definir a variável de ambiente DLTS_HOSTFILE para apontar para o arquivo host.
Oferecemos suporte para criação de perfil com Nsight Systems, PyTorch Profiler e PyTorch Memory Profiling.
Para usar o perfil do Nsight Systems, defina as opções de configuração profile , profile_step_start e profile_step_stop (veja aqui para uso de argumentos e aqui para um exemplo de configuração).
Para preencher as métricas nsys, inicie o treinamento com:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
O arquivo de saída gerado pode então ser visualizado com a GUI do Nsight Systems:
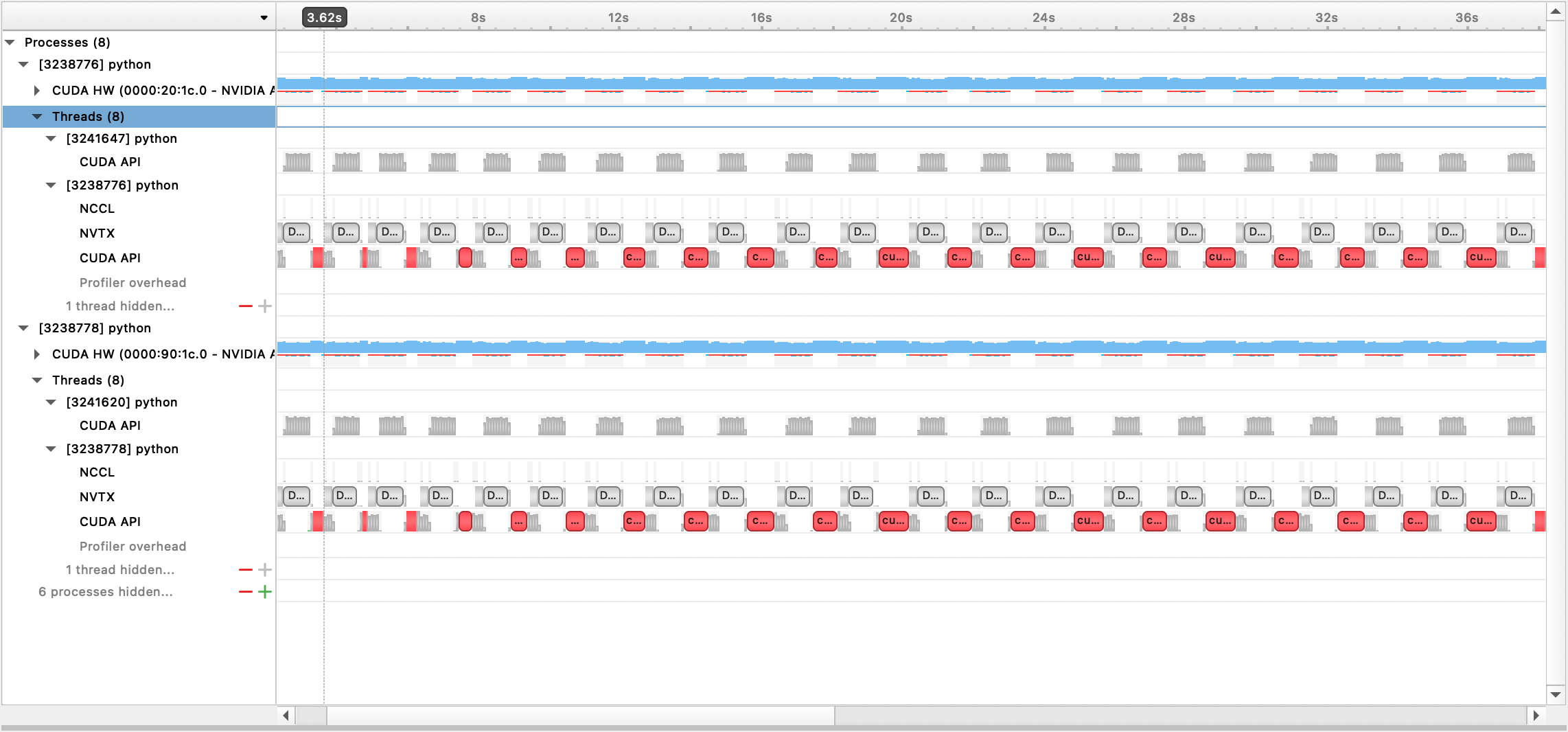
Para usar o criador de perfil PyTorch integrado, defina as opções de configuração profile , profile_step_start e profile_step_stop (veja aqui para uso de argumentos e aqui para um exemplo de configuração).
O criador de perfil PyTorch salvará rastros no diretório de log tensorboard . Você pode visualizar esses rastreamentos no TensorBoard seguindo as etapas aqui.
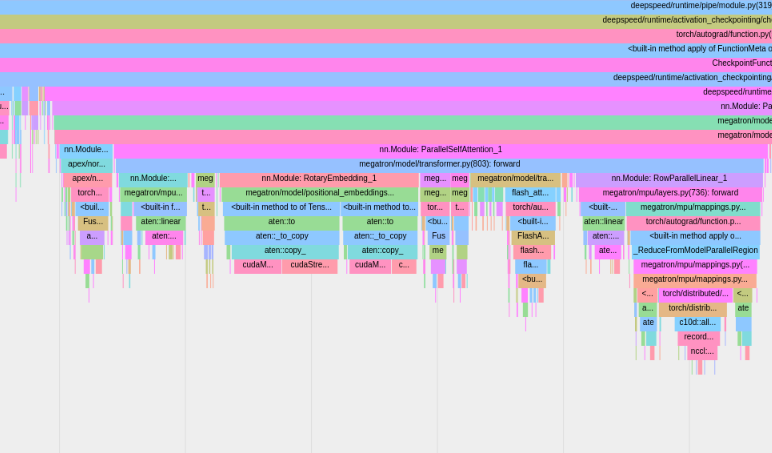
Para usar o perfil de memória PyTorch, defina as opções de configuração memory_profiling e memory_profiling_path (veja aqui para uso de argumentos e aqui para um exemplo de configuração).
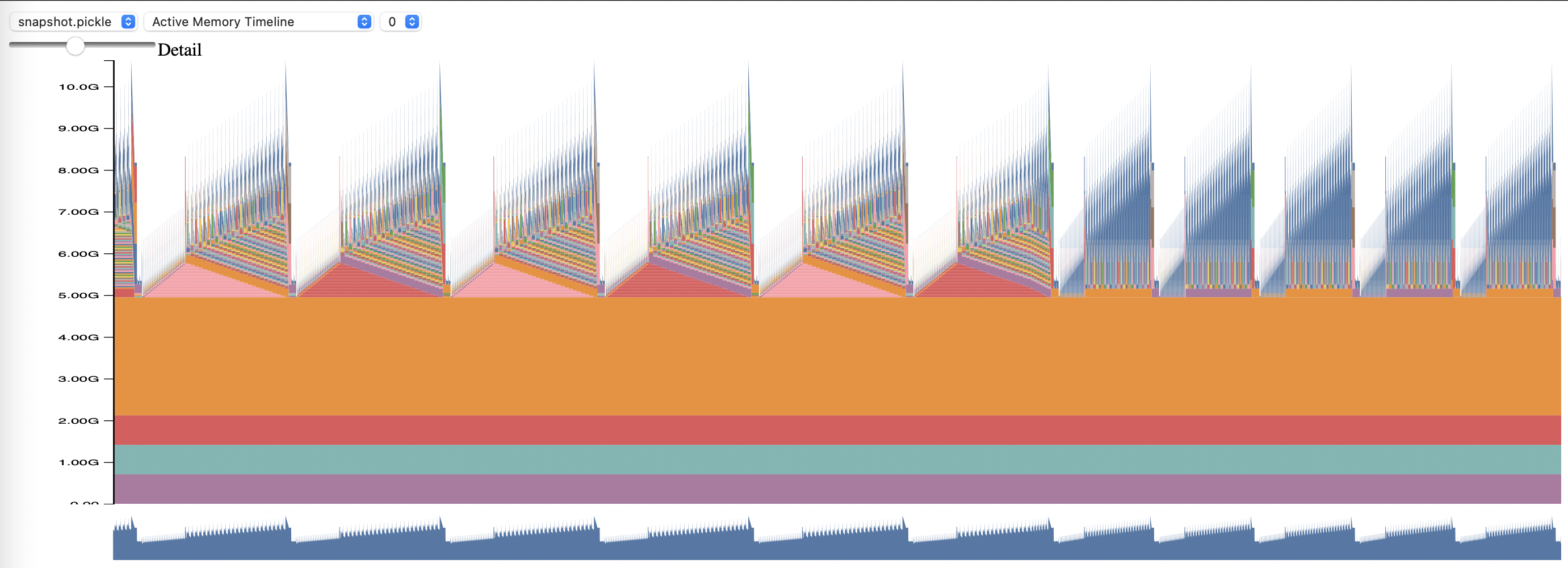
Visualize o perfil gerado com o script memory_viz.py. Corra com:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
A biblioteca GPT-NeoX foi amplamente adotada por pesquisadores acadêmicos e industriais e portada para muitos sistemas HPC.
Se você achou esta biblioteca útil em sua pesquisa, entre em contato e nos informe! Adoraríamos adicionar você às nossas listas.
EleutherAI e nossos colaboradores o utilizaram nas seguintes publicações:
As seguintes publicações de outros grupos de pesquisa utilizam esta biblioteca:


