TEMPO
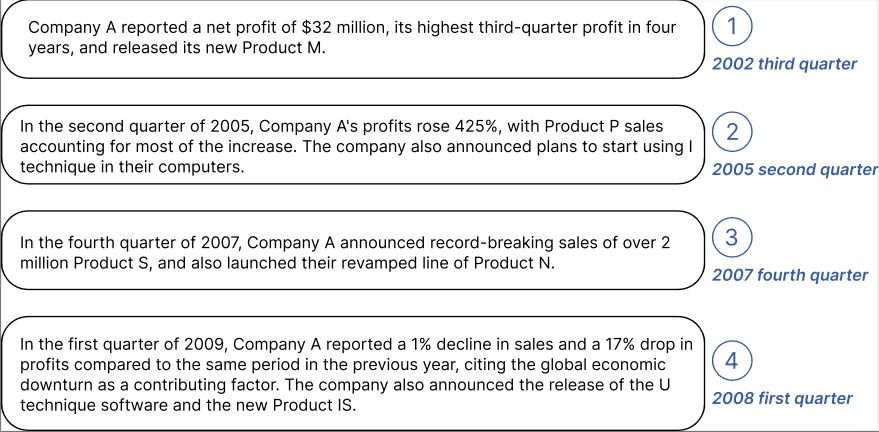
1.0.0

O código oficial para ["TEMPO: Transformador generativo pré-treinado baseado em prompt para previsão de séries temporais (ICLR 2024)"].
TEMPO é um dos primeiros modelos de base de série temporal de código aberto para previsão de tarefas versão v1.0.
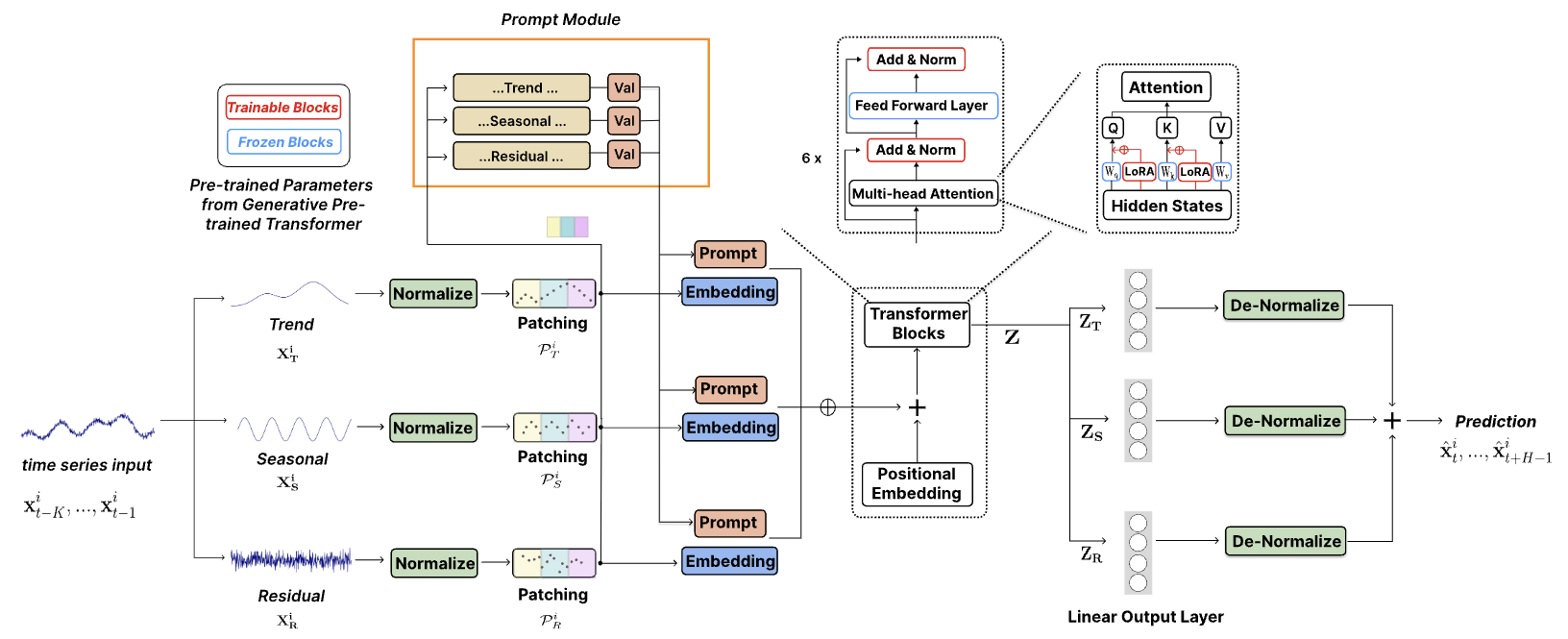
Outubro de 2024 : Simplificamos nossa estrutura de código, permitindo que os usuários baixem o modelo pré-treinado e realizem inferência zero-shot com uma única linha de código! Confira nossa demonstração para mais detalhes. A contagem de downloads do nosso modelo no HuggingFace agora pode ser rastreada!
Junho de 2024 : Adicionamos demonstrações para reproduzir experimentos de disparo zero no Colab. Também adicionamos a demonstração de construção do conjunto de dados do cliente e fazemos a inferência diretamente por meio de nosso modelo básico pré-treinado: Colab
Maio de 2024 : TEMPO lançou uma demonstração online baseada em GUI, permitindo aos usuários interagir diretamente com nosso modelo básico!
Maio de 2024 : TEMPO publicou o modelo de base pré-treinado 80M no HuggingFace!
Maio de 2024 : ? Adicionamos o código para modelos TEMPO de pré-treinamento e inferência. Você pode encontrar uma demonstração do script de pré-treinamento nesta pasta. Também adicionamos um script para a demonstração de inferência.
Março de 2024 : ? Lançado conjunto de dados TETS do S&P 500 usado em experimentos multimodais no TEMPO.
Março de 2024 : ? A TEMPO publicou o código do projeto e o checkpoint pré-treinado online!
Janeiro de 2024 : Artigo TEMPO aceito pelo ICLR!
Outubro de 2023 : Artigo TEMPO lançado no Arxiv!
conda create -n tempo python=3.8
conda activate tempo
pip install -r requirements.txt
Um exemplo de simplificação que mostra como realizar previsões usando TEMPO:
# Third-party library imports
import numpy as np
import torch
from numpy . random import choice
# Local imports
from models . TEMPO import TEMPO
model = TEMPO . load_pretrained_model (
device = torch . device ( 'cuda:0' if torch . cuda . is_available () else 'cpu' ),
repo_id = "Melady/TEMPO" ,
filename = "TEMPO-80M_v1.pth" ,
cache_dir = "./checkpoints/TEMPO_checkpoints"
)
input_data = np . random . rand ( 336 ) # Random input data
with torch . no_grad ():
predicted_values = model . predict ( input_data , pred_length = 96 )
print ( "Predicted values:" )
print ( predicted_values )Por favor, tente reproduzir os experimentos zero-shot no ETTh2 [aqui no Colab].
Usamos a seguinte página do Colab para mostrar a demonstração da construção do conjunto de dados do cliente e fazer a inferência diretamente por meio de nosso modelo básico pré-treinado: [Colab]
Experimente nossa demonstração do modelo de base [aqui].
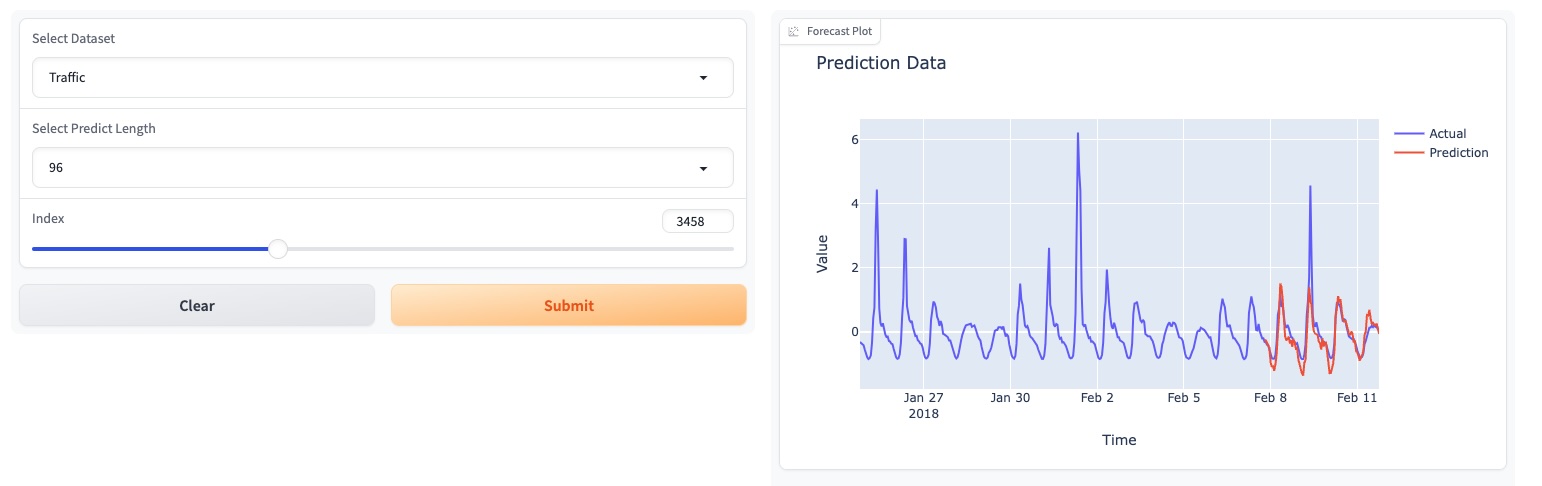
Também atualizamos nossos modelos no HuggingFace: [Melady/TEMPO].
Baixe os dados do [Google Drive] ou [Baidu Drive] e coloque os dados baixados na pasta ./dataset . Você também pode baixar os resultados STL do [Google Drive] e colocar os dados baixados na pasta ./stl .
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather].sh
Após o treinamento, podemos testar o modelo TEMPO na configuração zero-shot:
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather]_test.sh
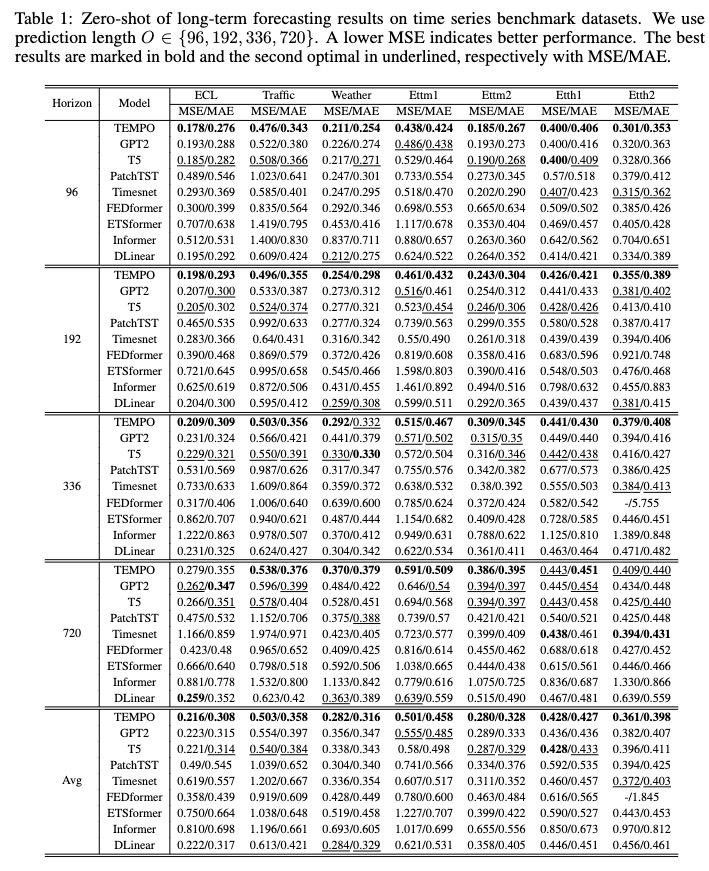
Você pode baixar o modelo pré-treinado no [Google Drive] e executar o script de teste para se divertir.
Aqui estão os prompts usados para gerar as informações textuais correspondentes de séries temporais via [API OPENAI ChatGPT-3.5]

Os dados da série temporal são provenientes do [S&P 500]. Aqui está o caso do EBITDA para uma empresa do conjunto de dados:
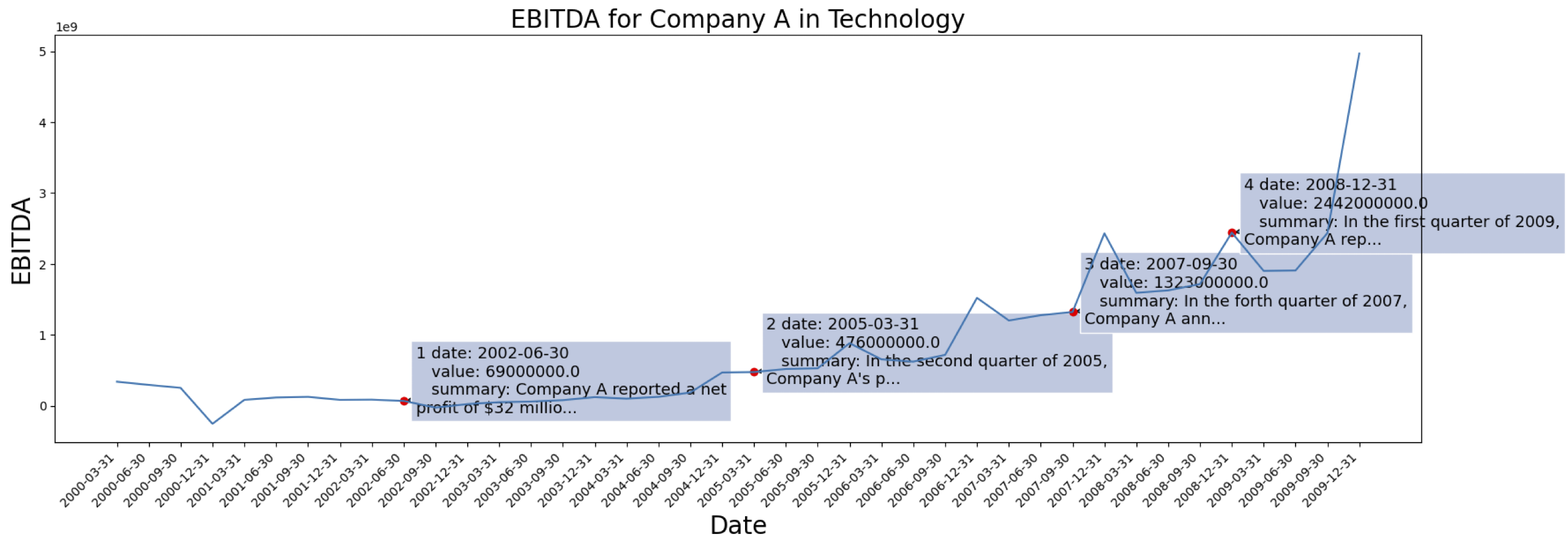
Exemplo de informação contextual gerada para a Empresa marcada acima:
Você pode baixar os dados processados com incorporação de texto do GPT2 em: [TETS].
Sinta-se à vontade para conectar [email protected] / [email protected] se estiver interessado em aplicar o TEMPO à sua aplicação no mundo real.
@inproceedings{
cao2024tempo,
title={{TEMPO}: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting},
author={Defu Cao and Furong Jia and Sercan O Arik and Tomas Pfister and Yixiang Zheng and Wen Ye and Yan Liu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=YH5w12OUuU}
}
@article{
Jia_Wang_Zheng_Cao_Liu_2024,
title={GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/30383},
DOI={10.1609/aaai.v38i21.30383},
number={21},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Jia, Furong and Wang, Kevin and Zheng, Yixiang and Cao, Defu and Liu, Yan},
year={2024}, month={Mar.}, pages={23343-23351}
}


