Awesome Attention Heads
vey on LLM attention heads
Importante
Sobre este repositório. Esta é uma plataforma para obter as pesquisas mais recentes sobre diferentes tipos de Attention Heads do LLM. Além disso, divulgamos uma pesquisa baseada nesses trabalhos fantásticos.
Se você quiser citar nosso trabalho , aqui está nossa entrada no bibtex: CITATION.bib.
Se você quiser apenas ver a lista de artigos relacionados, vá diretamente para aqui.
Se você quiser contribuir com este repositório, consulte aqui.
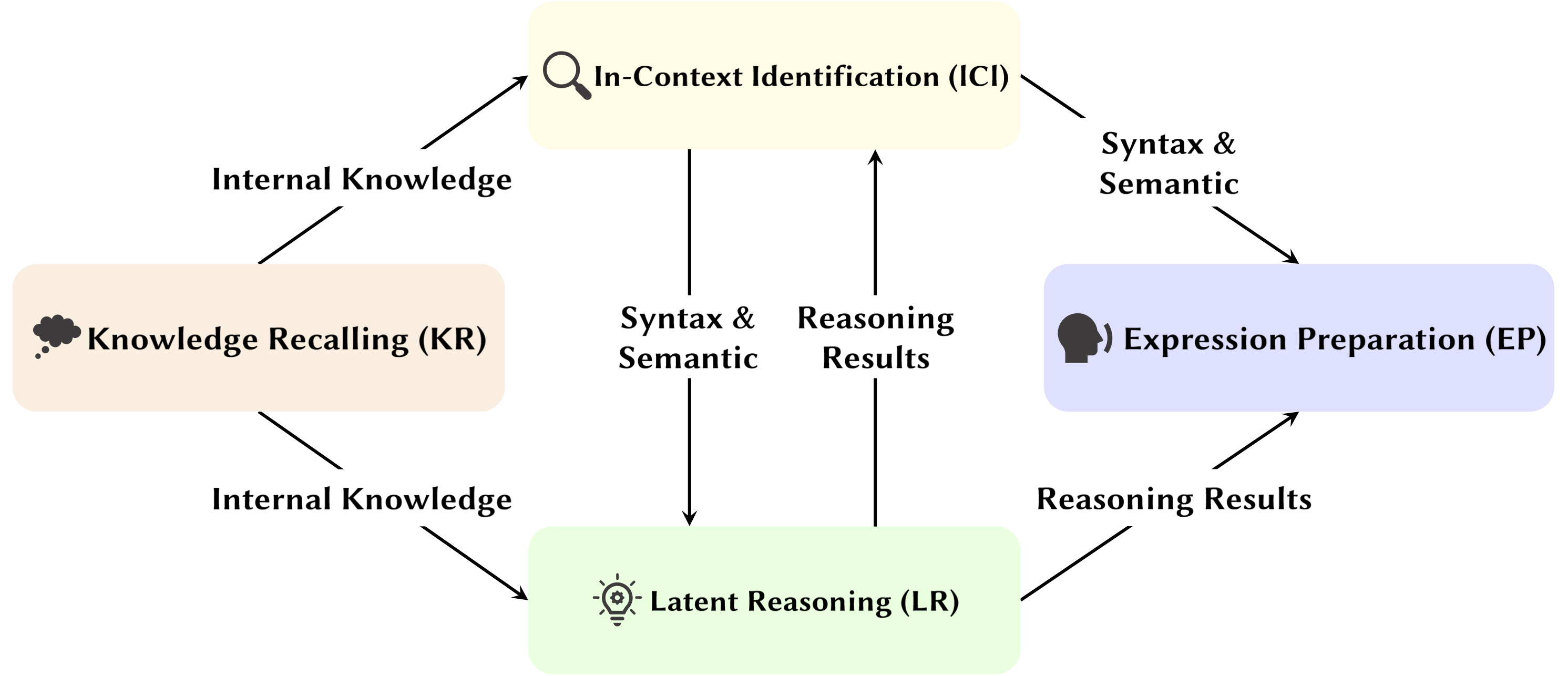
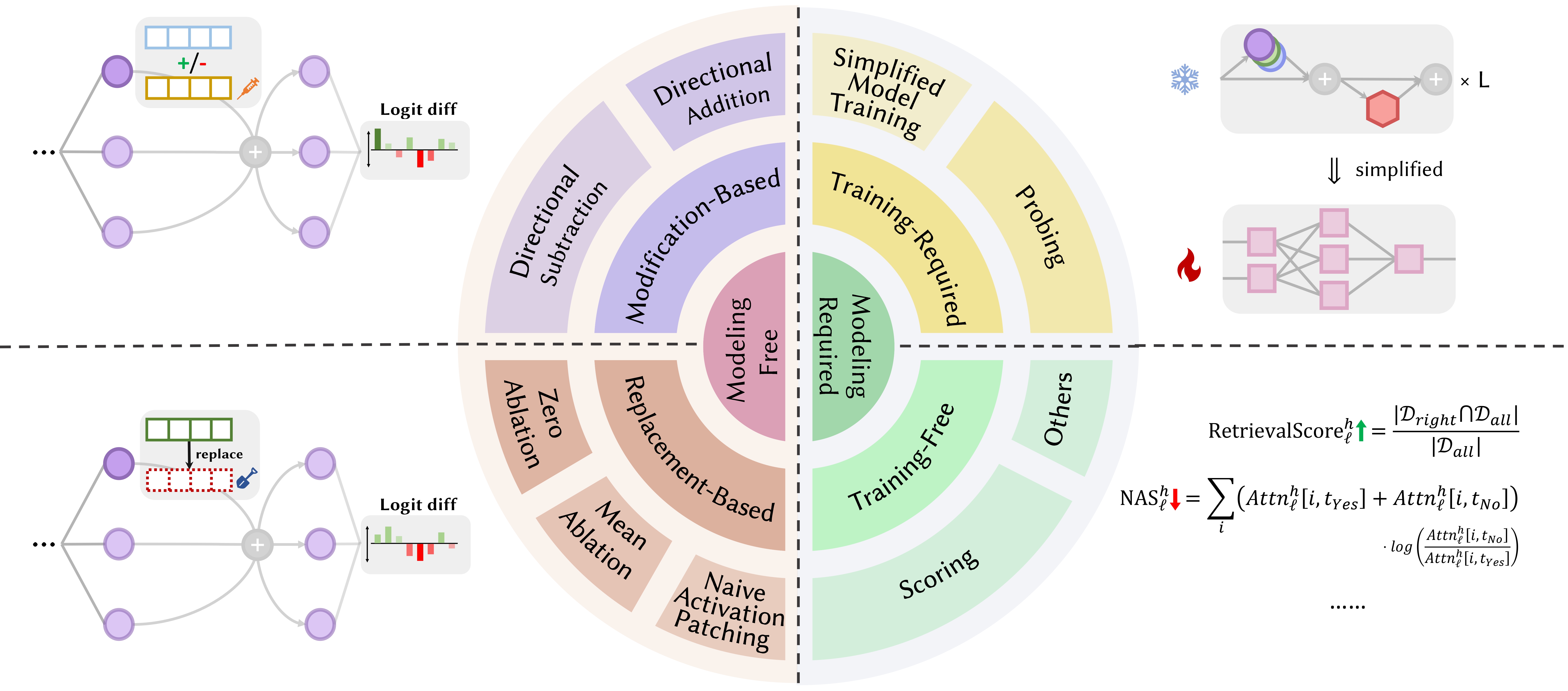
Com o desenvolvimento do Large Language Model (LLMs), sua estrutura de rede subjacente, o Transformer, está sendo extensivamente estudada. Pesquisar a estrutura do Transformer nos ajuda a aprimorar nossa compreensão dessa "caixa preta" e a melhorar a interpretabilidade do modelo. Recentemente, tem havido um conjunto crescente de trabalhos sugerindo que o modelo contém duas partições distintas: mecanismos de atenção usados para comportamento, inferência e análise, e Redes Feed-Forward (FFN) para armazenamento de conhecimento. O primeiro é crucial para revelar as capacidades funcionais do modelo, levando a uma série de estudos que exploram diversas funções dentro dos mecanismos de atenção, que denominamos Attention Head Mining .
Nesta pesquisa, investigamos os mecanismos potenciais de como as cabeças de atenção nos LLMs contribuem para o processo de raciocínio.
Destaques:
Os artigos abaixo estão ordenados por data de publicação :
Ano 2024
| Data | Artigo e Resumo | Etiquetas | Ligações |
| 15/11/2024 | SEEKR: Retenção seletiva de conhecimento guiada pela atenção para aprendizagem contínua de grandes modelos de linguagem | ||
| • Propõe o SEEKR, um método seletivo de retenção de conhecimento guiado pela atenção para aprendizagem contínua em LLMs, com foco em focos de atenção chave para uma destilação eficiente. • Avaliado em benchmarks de aprendizagem contínua TRACE e SuperNI. • SEEKR obteve desempenho comparável ou melhor com apenas 1% dos dados de repetição em comparação com outros métodos. | |||
| 06/11/2024 | Como os transformadores resolvem problemas de lógica proposicional: uma análise mecanicista | ||
| • Identifica circuitos de atenção específicos em transformadores que resolvem problemas de lógica proposicional, com foco em mecanismos de “planejamento” e “raciocínio”. • Analisei pequenos transformadores e Mistral-7B, usando patches de ativação para descobrir caminhos de raciocínio. • Encontrou chefes de atenção distintos, especializados em localização de regras, processamento de fatos e tomada de decisões em raciocínio lógico. | |||
| 01-11-2024 | Rastreador de atenção: detectando ataques de injeção imediata em LLMs | ||
| • Proposto o Attention Tracker, um guarda simples, mas eficaz, sem treinamento, que detecta ataques de injeção imediatos com base em Cabeças Importantes identificadas. • Identificou as cabeças importantes usando apenas um pequeno conjunto de frases aleatórias geradas pelo LLM combinadas com um ataque ingênuo de ignorar. • O Attention Tracker é eficaz em LMs pequenos e grandes, abordando uma limitação significativa dos métodos de detecção anteriores sem treinamento. | |||
| 28/10/2024 | Aritmética sem algoritmos: modelos de linguagem resolvem matemática com um pacote de heurísticas | ||
| • Identificou um subconjunto do modelo (um circuito) que explica a maior parte do comportamento do modelo para lógica aritmética básica e examinou sua funcionalidade. • Analisou padrões de atenção usando prompts aritméticos de dois operandos com algarismos arábicos e os quatro operadores básicos (+, −, ×, ÷). • Para adição, subtração e divisão, 6 cabeças de atenção produzem alta fidelidade (97% em média), enquanto a multiplicação exige 20 cabeças para exceder 90% de fidelidade. | |||
| 2024-10-21 | Uma avaliação psicolinguística da sensibilidade dos modelos de linguagem aos papéis argumentativos | ||
| • Cabeça do sujeito observado em um cenário mais generalizado. • Analisou padrões de atenção sob a condição de argumentos de troca e argumento de substituição. • Apesar de serem capazes de distinguir papéis, os modelos podem ter dificuldade em utilizar correctamente a informação do papel do argumento, uma vez que o problema reside na forma como esta informação é codificada em representações verbais, resultando numa sensibilidade de papel mais fraca. | |||
| 17/10/2024 | Cabeças de atenção ativas-dormentes: desmistificando mecanisticamente fenômenos de token extremo em LLMs | ||
| • Demonstrou que fenômenos de token extremo surgem de um mecanismo ativo-dormente nas cabeças de atenção, juntamente com um mecanismo de reforço mútuo durante o pré-treinamento. • Utilização de transformadores simples treinados na tarefa Bigram-Backcopy (BB) para analisar fenômenos extremos de tokens e estendê-los para LLMs pré-treinados. • Muitas das propriedades estáticas e dinâmicas dos fenômenos de token extremo previstos pela tarefa BB se alinham com as observações em LLMs pré-treinados. | |||
| 17/10/2024 | Sobre o papel dos chefes de atenção na segurança dos modelos de linguagem grande | ||
| • Propôs uma nova métrica adaptada à atenção de vários chefes, o Safety Head ImPortant Score (Navios), para avaliar as contribuições individuais dos chefes para a segurança do modelo. • Realizei análises sobre a funcionalidade destes cabeçotes de atenção de segurança, explorando suas características e mecanismos. • Certas cabeças de atenção são cruciais para a segurança, as cabeças de segurança se sobrepõem em modelos ajustados e a remoção dessas cabeças causa um impacto mínimo na utilidade. | |||
| 14/10/2024 | DuoAttention: Inferência LLM eficiente de longo contexto com cabeças de recuperação e streaming | ||
| • Introduziu o DuoAttention, uma estrutura que reduz a decodificação e o pré-preenchimento de memória e latência do LLM sem comprometer suas capacidades de contexto longo, com base na descoberta de Retrieval Heads e Streaming Heads dentro do LLM. • Testar o impacto da estrutura no desempenho do LLM em tarefas de contexto curto e de contexto longo, bem como a sua eficiência de inferência. • Ao aplicar um cache KV completo somente aos cabeçotes de recuperação, o DuoAttention reduz significativamente o uso de memória e a latência para decodificação e pré-preenchimento em aplicativos de contexto longo. | |||
| 14/10/2024 | Bloqueando a segurança dos LLMs ajustados | ||
| • Introduziu o SafetyLock, um método novo e eficiente para manter a segurança de grandes modelos de linguagem ajustados em vários níveis de risco e cenários de ataque, com base na descoberta de Safety Heads no LLM. • Avaliar a eficácia do SafetyLock no aumento da segurança do modelo e na eficiência da inferência. • Ao aplicar vetores de intervenção às cabeças de segurança, o SafetyLock pode modificar as ativações internas do modelo no sentido de inocuidade durante a inferência, alcançando um alinhamento de segurança preciso com impacto mínimo na resposta. | |||
| 11/10/2024 | O mesmo, mas diferente: semelhanças e diferenças estruturais na modelagem de linguagem multilíngue | ||
| • Conduziu um estudo aprofundado dos componentes específicos dos quais os modelos multilíngues dependem ao executar tarefas que exigem processos morfológicos específicos do idioma. • Investigar as diferenças funcionais dos componentes internos do modelo ao executar tarefas em inglês e chinês. • O cabeçote de cópia tem uma frequência de ativação igualmente alta em ambos os idiomas, enquanto o cabeçote de pretérito só é ativado com frequência em inglês. | |||
| 08/10/2024 | Voltas e voltas nós vamos! O que torna as codificações posicionais rotativas úteis? | ||
| • Forneci uma análise aprofundada dos componentes internos de um modelo Gemma 7B treinado para entender como o RoPE está sendo usado em nível mecânico. • Compreendeu o uso de diferentes frequências nas consultas e chaves. • Descobriu que as frequências mais altas em RoPE são habilmente usadas pelo Gemma 7B para construir cabeças de atenção 'posicionais' especiais (cabeças diagonais, cabeça de token anterior), enquanto as frequências baixas são usadas pela cabeça de apóstrofo. | |||
| 06/10/2024 | Revisitando o circuito de inferência de aprendizagem no contexto em grandes modelos de linguagem | ||
| • Propôs um circuito de inferência abrangente de 3 etapas para caracterizar o processo de inferência da ICL. • Divida a ICL em três estágios: Resumir, Mesclar Semântica e Recuperação e Cópia de Recursos, analisando o papel que cada estágio desempenha na ICL e seu mecanismo operacional. • Descobriu que antes dos cabeçalhos de indução, os tokens Forerunner Heads primeiro mesclam as representações de texto de demonstração do token precursor em seus tokens de rótulo correspondentes, seletivamente com base na compatibilidade entre a demonstração e a semântica do rótulo. | |||
| 01/10/2024 | Decomposição de atenção esparsa aplicada ao rastreamento de circuitos | ||
| • Introduz a decomposição de atenção esparsa, usando SVD em matrizes de cabeça de atenção para rastrear caminhos de comunicação em modelos GPT-2. • Aplicado ao rastreamento de circuitos no GPT-2 pequeno para a tarefa de Identificação Indireta de Objetos (IOI). • Identificou sinais de comunicação esparsos e funcionalmente significativos entre cabeças de atenção, melhorando a interpretabilidade. | |||
| 09/09/2024 | Revelando cabeças de indução: dinâmicas de treinamento comprováveis e aprendizado de recursos em transformadores | ||
| • O artigo apresenta um mecanismo generalizado de cabeça de indução, explicando como os componentes do transformador colaboram para realizar a aprendizagem no contexto (ICL) em cadeias de Markov de n-gramas. • Analisa um transformador de duas camadas de atenção com fluxo gradiente para prever tokens em cadeias de Markov. • O fluxo gradiente converge, permitindo ICL através de um mecanismo de cabeça de indução baseado em recursos aprendidos. | |||
| 16/08/2024 | Uma interpretação mecanicista do raciocínio silogístico em modelos de linguagem auto-regressivos | ||
| • O estudo introduz uma interpretação mecanicista do raciocínio silogístico em LMs, identificando circuitos de raciocínio independentes de conteúdo. • Descoberta de circuitos para raciocínio e investigação de contaminação por preconceitos de crenças em cabeças de atenção. • Identificou um circuito de raciocínio necessário, transferível através de esquemas silogísticos, mas suscetível à contaminação por conhecimento de mundo pré-treinado. | |||
| 01/08/2024 | Melhorando a consistência semântica de grandes modelos de linguagem por meio da edição de modelos: uma abordagem orientada para a interpretabilidade | ||
| • Introduz uma abordagem econômica de edição de modelos com foco em focos de atenção para melhorar a consistência semântica em LLMs sem grandes alterações de parâmetros. • Analisou cabeças de atenção, injetou vieses e testou em conjuntos de dados NLU e NLG. • Obtive melhorias notáveis na consistência semântica e no desempenho de tarefas, com forte generalização em tarefas adicionais. | |||
| 31/07/2024 | Correção de preconceito negativo em modelos de linguagem grande por meio do alinhamento de pontuação de atenção negativa | ||
| • Introduziu Pontuação de Atenção Negativa (NAS) para quantificar e corrigir preconceitos negativos em modelos de linguagem. • Identificamos cabeças de atenção negativamente tendenciosas e propusemos o Alinhamento da Pontuação de Atenção Negativa (NASA) para ajuste fino. • A NASA reduziu efetivamente a lacuna na recuperação de precisão, preservando ao mesmo tempo a generalização em tarefas de decisão binária. | |||
| 29/07/2024 | Detectando e compreendendo vulnerabilidades em modelos de linguagem por meio de interpretabilidade mecanística | ||
| • Introduz um método que utiliza Interpretabilidade Mecanística (MI) para detectar e compreender vulnerabilidades em LLMs, particularmente ataques adversários. • Analisa vulnerabilidades do GPT-2 Small na previsão de siglas de três letras. • Identifica e explica com sucesso vulnerabilidades específicas no modelo relacionado à tarefa. | |||
| 2024-07-22 | RazorAttention: Compressão de cache KV eficiente por meio de cabeçotes de recuperação | ||
| • Lançamento do RazorAttention, uma técnica de compactação de cache KV sem treinamento que utiliza cabeçotes de recuperação e tokens de compensação para preservar informações críticas de token. • Avaliamos a eficiência do RazorAttention em modelos de linguagem grande (LLMs). • Obtenção de mais de 70% de redução no tamanho do cache KV sem impacto perceptível no desempenho. | |||
| 2024-07-21 | Responda, monte, craque: entendendo como os transformadores respondem a perguntas de múltipla escolha | ||
| • O artigo apresenta projeção de vocabulário e correção de ativação para localizar estados ocultos que predizem as respostas corretas do MCQA. • Identificação de principais focos de atenção e camadas responsáveis pela seleção de respostas em transformadores. • Os cabeçotes de atenção da camada intermediária são cruciais para uma previsão precisa das respostas, com um conjunto esparso de cabeçotes desempenhando papéis únicos. | |||
| 09/07/2024 | Cabeças de indução como um mecanismo essencial para correspondência de padrões na aprendizagem in-context | ||
| • O artigo identifica cabeças de indução como cruciais para a correspondência de padrões na aprendizagem em contexto (ICL). • Avaliei Llama-3-8B e InternLM2-20B em reconhecimento de padrões abstratos e tarefas de PNL. • A ablação das cabeças de indução reduz o desempenho do ICL em até aproximadamente 32%, aproximando-o do aleatório para reconhecimento de padrões. | |||
| 02/07/2024 | Interpretando o Mecanismo Aritmético em Grandes Modelos de Linguagem por meio de Análise Comparativa de Neurônios | ||
| • Introduz Análise Comparativa de Neurônios (CNA) para mapear mecanismos aritméticos em cabeças de atenção de grandes modelos de linguagem. • Analisou a habilidade aritmética, poda de modelos para tarefas aritméticas e edição de modelos para reduzir preconceitos de gênero. • Identificou neurônios específicos responsáveis pela aritmética, permitindo melhorias de desempenho e mitigação de vieses por meio da manipulação direcionada de neurônios. | |||
| 01/07/2024 | Direcionando grandes modelos de linguagem para recuperação de informações multilíngues | ||
| • Introduz a Recuperação Multilíngue Orientada por Ativação (ASMR), usando ativações de direção para orientar LLMs para melhorar a recuperação de informações multilíngues. • Identificamos focos de atenção em LLMs que afetam a precisão e a coerência da linguagem, e aplicamos ativações de direção. • ASMR alcançou desempenho de última geração em benchmarks CLIR como XOR-TyDi QA e MKQA. | |||
| 2024-06-25 | Como os transformadores aprendem a estrutura causal com gradiente descendente | ||
| • Forneceu uma explicação de como os transformadores aprendem estruturas causais através de algoritmos de treinamento baseados em gradiente. • Analisei o desempenho de transformadores de duas camadas em uma tarefa chamada sequências aleatórias com estrutura causal. • O gradiente descendente em um transformador simplificado de duas camadas aprende a resolver essa tarefa codificando o gráfico causal latente na primeira camada de atenção. Como um caso especial, quando sequências são geradas a partir de cadeias de Markov no contexto, os transformadores aprendem a desenvolver uma cabeça de indução. | |||
| 2024-06-21 | MoA: mistura de atenção esparsa para compactação automática de modelo de linguagem grande | ||
| • O artigo apresenta Mixture of Attention (MoA), que adapta configurações distintas de atenção esparsa para diferentes cabeçotes e camadas, otimizando memória, rendimento e compensações entre precisão e latência. • MoA cria perfis de modelos, explora configurações de atenção e melhora a compactação LLM. • MoA aumenta o comprimento efetivo do contexto em 3,9×, enquanto reduz o uso de memória da GPU em 1,2-1,4×. | |||
| 19/06/2024 | Sobre a dificuldade do raciocínio fiel à cadeia de pensamento em grandes modelos de linguagem | ||
| • Introduziu novas estratégias para aprendizagem em contexto, ajuste fino e edição de ativação para melhorar a fidelidade do raciocínio da Cadeia de Pensamento (CoT) em LLMs. • Testamos essas estratégias em vários benchmarks para avaliar sua eficácia. • Encontrou apenas sucesso limitado no aumento da fidelidade do CoT, destacando o desafio em alcançar um raciocínio verdadeiramente fiel nos LLMs. | |||
| 04/06/2024 | Cabeça de Iteração: Um Estudo Mecanístico da Cadeia de Pensamento | ||
| • Introduz "cabeças de iteração", cabeças de atenção especializadas que permitem o raciocínio iterativo em transformadores para tarefas de Cadeia de Pensamento (CoT). • Análise dos mecanismos de atenção, rastreando a emergência do CoT e testando a transferibilidade das habilidades do CoT entre tarefas. • Os cabeçotes de iteração apoiam efetivamente o raciocínio CoT, melhorando a interpretabilidade do modelo e o desempenho da tarefa. | |||
| 03/06/2024 | LoFiT: ajuste fino localizado em representações LLM | ||
| • Introduz o ajuste fino localizado em representações LLM (LoFiT), uma estrutura de duas etapas para identificar pontos de atenção importantes de uma determinada tarefa e aprender vetores de deslocamento específicos da tarefa para intervir nas representações dos pontos identificados. • Identificamos conjuntos esparsos de pontos de atenção importantes para melhorar a precisão posterior em termos de veracidade e raciocínio. • LoFiT superou outros métodos de intervenção de representação e alcançou desempenho comparável aos métodos PEFT em TruthfulQA, CLUTRR e MQuAKE, apesar de intervir apenas em 10% do total de cabeças de atenção em LLMs. | |||
| 28/05/2024 | Circuitos de conhecimento em transformadores pré-treinados | ||
| • Introduziu “circuitos de conhecimento” em transformadores, revelando como o conhecimento específico é codificado através da interação entre cabeças de atenção, cabeças de relacionamento e MLPs. • Análise de GPT-2 e TinyLLAMA para identificação de circuitos de conhecimento; avaliaram técnicas de edição de conhecimento. • Demonstrou como os circuitos de conhecimento contribuem para modelar comportamentos como alucinações e aprendizagem em contexto. | |||
| 23/05/2024 | Vinculando a aprendizagem contextual em transformadores à memória episódica humana | ||
| • Vincula a aprendizagem contextual em modelos Transformer à memória episódica humana, destacando semelhanças entre cabeças de indução e o modelo de manutenção e recuperação contextual (CMR). • Análise de LLMs baseados em Transformer para demonstrar comportamento semelhante ao CMR em cabeças de atenção. • Cabeças semelhantes a CMR emergem em camadas intermediárias, refletindo distorções da memória humana. | |||
| 07/05/2024 | Como o GPT-2 prevê siglas? Extraindo e compreendendo um circuito por meio de interpretabilidade mecanística | ||
| • Primeiro estudo mecanístico de interpretabilidade em GPT-2 para previsão de acrônimos multitoken usando cabeças de atenção. • Identifiquei e interpretei um circuito de 8 cabeças de atenção responsáveis pela previsão de acrônimos. • Demonstrou que estas 8 cabeças (~5% do total) concentram a funcionalidade de previsão do acrônimo. | |||
| 02/05/2024 | Interpretando e melhorando grandes modelos de linguagem em cálculo aritmético | ||
| • Introduz uma investigação detalhada dos mecanismos internos dos LLMs através de tarefas matemáticas, seguindo o pipeline de 'identificar-analisar-ajustar'. • Analisei a capacidade do modelo de realizar tarefas aritméticas envolvendo dois operandos, como adição, subtração, multiplicação e divisão. • Descobriu que os LLMs frequentemente envolvem uma pequena fração (< 5%) de cabeças de atenção, que desempenham um papel fundamental no foco em operandos e operadores durante os processos de cálculo. | |||
| 02/05/2024 | O que precisa dar certo para um cabeçote de indução? Um estudo mecanicista de circuitos de aprendizagem em contexto e sua formação | ||
| • Introduziu uma estrutura causal inspirada na optogenética para estudar a formação de cabeças de indução (IH) em transformadores. • Analisou a emergência de IH em transformadores usando dados sintéticos e identificou três subcircuitos subjacentes responsáveis pela formação de IH. • Descobriu que esses subcircuitos interagem para impulsionar a formação de IH, coincidindo com uma mudança de fase na perda do modelo. | |||
| 2024-04-24 | Cabeça de recuperação explica mecanisticamente a factualidade de longo contexto | ||
| • Identificação de “cabeças de recuperação” em modelos de transformadores responsáveis pela recuperação de informações em contextos longos. • Investigação sistemática de cabeças de recuperação em vários modelos, incluindo análise do seu papel no raciocínio da cadeia de pensamento. • A poda das cabeças de recuperação leva à alucinação, enquanto a poda das cabeças de recuperação não afeta a capacidade de recuperação. | |||
| 27/03/2024 | Intervenção de tempo de inferência não linear: melhorando a veracidade do LLM | ||
| • Introduziu a intervenção de tempo de inferência não linear (NL-ITI), melhorando a veracidade do LLM por meio de sondagem e intervenção multitoken sem ajuste fino. • Avaliei NL-ITI em conjuntos de dados de múltipla escolha, incluindo TruthfulQA. • Obtive uma melhoria relativa de 16% na precisão do MC1 no TruthfulQA em relação ao ITI inicial. | |||
| 28/02/2024 | Como pensar passo a passo: uma compreensão mecanicista do raciocínio em cadeia de pensamento | ||
| • Forneceu uma análise aprofundada do raciocínio mediado por CoT em LLMs em termos de componentes funcionais neurais. • Raciocínio baseado em CoT dissecado sobre raciocínio ficcional como uma composição de um número fixo de subtarefas que requerem tomada de decisão, cópia e raciocínio indutivo, analisando seu mecanismo separadamente. • Descobriu que os chefes de atenção realizam movimentos de informação entre tokens ontologicamente relacionados (ou negativamente relacionados), resultando em representações distintamente identificáveis para esses pares de tokens. | |||
| 28/02/2024 | Cortar a cabeça acaba com o conflito: um mecanismo para interpretar e mitigar conflitos de conhecimento em modelos de linguagem | ||
| • Introduz o método PH3 para eliminar focos de atenção conflitantes, mitigando conflitos de conhecimento em modelos de linguagem sem atualizações de parâmetros. • Aplicou o PH3 para controlar a dependência dos LMs na memória interna versus contexto externo e testou sua eficácia em tarefas de controle de qualidade de domínio aberto. • O PH3 melhorou o uso de memória interna em 44,0% e o uso de contexto externo em 38,5%. | |||
| 27/02/2024 | Rotas de fluxo de informações: interpretação automática de modelos de linguagem em escala | ||
| • Introduz "Rotas de fluxo de informações" usando atribuição para interpretação baseada em gráficos de modelos de linguagem, evitando patches de ativação. • Experimentos com o Llama 2, identificando principais focos de atenção e padrões de comportamento em diferentes domínios e tarefas. • Componentes de modelos especializados descobertos; identificou funções consistentes para chefes de atenção, como lidar com tokens da mesma parte do discurso. | |||
| 20/02/2024 | Identificando cabeças de indução semântica para compreender a aprendizagem no contexto | ||
| • Identifica e estuda “cabeças de indução semântica” em grandes modelos de linguagem (LLMs) que se correlacionam com habilidades de aprendizagem em contexto. • Análise de cabeças de atenção para codificação de dependências sintáticas e relações de gráficos de conhecimento. • Certas cabeças de atenção melhoram os logits de produção ao recordar tokens relevantes, cruciais para a compreensão da aprendizagem em contexto em LLMs. | |||
| 16/02/2024 | A evolução das cabeças de indução estatística: aprendizagem em contexto de cadeias de Markov | ||
| • Introduz uma tarefa de modelagem de sequência de cadeia de Markov para analisar como as capacidades de aprendizagem no contexto (ICL) emergem em transformadores, formando "cabeças de indução estatística". • Investigação empírica e teórica do treinamento multifásico em transformadores em tarefas de Cadeia de Markov. • Demonstra transições de fase de previsões unigramas para bigramas, influenciadas pelas interações da camada do transformador. | |||
| 11/02/2024 | Resumindo os fatos: mecanismos aditivos por trás da recuperação factual em LLMs | ||
| • Identifica e explica o "motivo aditivo" na recordação factual, onde os LLMs utilizam múltiplos mecanismos independentes que interferem construtivamente na recordação de factos. • Atribuição logit direta estendida para analisar cabeças de atenção e descompactar o comportamento de cabeças mistas. • Demonstrou que a recordação factual em LLMs resulta da soma de contribuições múltiplas e independentemente insuficientes. | |||
| 05/02/2024 | Como os grandes modelos de linguagem aprendem no contexto? Consulta e matrizes principais de cabeçalhos no contexto são duas torres para aprendizado de métricas | ||
| • Introduz o conceito de que matrizes de consulta e de chave em cabeçalhos no contexto operam como "duas torres" para aprendizado de métricas, facilitando o cálculo de similaridade entre recursos de rótulo. • Analisou mecanismos de aprendizagem em contexto; identificou cabeças de atenção específicas cruciais para ICL. • Redução da precisão do ICL de 87,6% para 24,4% intervindo em apenas 1% desses cabeçotes. | |||
| 23/01/2024 | Aprendizagem de línguas em contexto: arquiteturas e algoritmos | ||
| • Introdução de "cabeças de n-gramas", cabeças de atenção Transformer especializadas, melhorando o aprendizado de linguagem em contexto (ICLL) por meio de previsão de token condicional de entrada. • Avaliação de modelos neurais em linguagens regulares a partir de autômatos finitos aleatórios. • Cabeças de n-gramas conectadas melhoraram a perplexidade em 6,7% no conjunto de dados SlimPajama. | |||
| 16/01/2024 | A base mecanicista da dependência de dados e aprendizagem abrupta em uma tarefa de classificação em contexto | ||
| • O artigo modela a base mecanicista da aprendizagem in-context (ICL) através da formação abrupta de cabeças de indução em redes somente de atenção. • Tarefas ICL simuladas usando dados de entrada simplificados e uma rede baseada em atenção de duas camadas. • A formação de cabeças de indução impulsiona a transição abrupta para ICL, traçada através de não-linearidades aninhadas. | |||
| 16/01/2024 | Reutilização de componentes de circuito em tarefas em modelos de linguagem de transformadores | ||
| • O artigo demonstra que circuitos específicos no GPT-2 podem ser generalizados para diferentes tarefas, desafiando a noção de que tais circuitos são específicos para cada tarefa. • Examina a reutilização de circuitos da tarefa Indirect Object Identification (IOI) na tarefa Colored Objects. • O ajuste de quatro cabeças de atenção aumenta a precisão de 49,6% para 93,7% na tarefa de Objetos Coloridos. | |||
| 16/01/2024 | Cabeças sucessoras: cabeças de atenção recorrentes e interpretáveis na natureza | ||
| • O artigo apresenta "Cabeças Sucessoras", cabeças de atenção em LLMs que incrementam tokens com ordenações naturais, como dias ou números. • Analisa a formação de cabeças sucessoras em vários tamanhos de modelos e arquiteturas, como GPT-2 e Llama-2. • Cabeças sucessoras são encontradas em modelos que variam de parâmetros 31M a 12B, revelando representações numéricas abstratas e recorrentes. | |||
| 16/01/2024 | Vetores de função em modelos de linguagem grande | ||
| • O artigo apresenta "Vetores de Função (FVs)", representações causais e compactas de tarefas em modelos de transformadores autorregressivos. • Os FVs foram testados em diversas tarefas, modelos e camadas de aprendizagem em contexto (ICL). • Os VF podem ser somados para criar vetores que desencadeiam tarefas novas e complexas, demonstrando a composição interna do vetor. | |||
| Data | Artigo e Resumo | Etiquetas | Ligações |
| 23/12/2023 | Descoberta de fatos: tentativa de engenharia reversa de recordação factual no nível do neurônio | ||
| • Investigou como as primeiras camadas MLP no Pythia 2.8B codificam a recuperação factual usando circuitos distribuídos, com foco em superposição e incorporações de vários tokens. • Explorou pesquisa factual em camadas MLP, testou hipóteses sobre mecanismos de destokenização e hashing. • A recordação factual funciona como uma tabela de consulta distribuída sem mecanismos internos facilmente interpretáveis. | |||
| 07-11-2023 | Rumo à continuação de sequência interpretável: analisando circuitos compartilhados em grandes modelos de linguagem | ||
| • Demonstração da existência de circuitos compartilhados para tarefas similares de continuação de sequência. • Circuitos analisados e comparados para tarefas semelhantes de continuação de sequência, que incluem sequências crescentes de algarismos arábicos, palavras numéricas e meses. • Sequências semanticamente relacionadas dependem de subgráficos de circuitos compartilhados com funções análogas e da descoberta de subcircuitos semelhantes em modelos com funcionalidade análoga. | |||
| 23/10/2023 | Representações Lineares de Sentimento em Grandes Modelos de Linguagem | ||
| • O artigo identifica uma direção linear no espaço de ativação que captura a representação do sentimento em Large Language Models (LLMs). • Eles isolaram essa direção de sentimento e a testaram em tarefas como o Stanford Sentiment Treebank. • Eliminar esta direção de sentimento leva a uma redução de 76% na precisão da classificação, destacando a sua importância. | |||
| 06/10/2023 | Supressão de cópia: Compreendendo de forma abrangente uma cabeça de atenção | ||
| • O artigo introduz o conceito de supressão de cópia em um cabeçote de atenção pequeno GPT-2 (L10H7), que reduz a cópia ingênua de tokens, melhorando a calibração do modelo. • O artigo investiga e explica o mecanismo de supressão de cópia e seu papel no auto-reparo . • 76,9% do impacto do L10H7 no GPT-2 Small é explicado, tornando-o a descrição mais abrangente da função de um chefe de atenção. | |||
| 2023-09-22 | Intervenção no tempo de inferência: extraindo respostas verdadeiras de um modelo de linguagem | ||
| • Introduziu a Intervenção no Tempo de Inferência (ITI) para melhorar a veracidade do LLM, ajustando as ativações do modelo em cabeças de atenção selecionadas. • Melhor desempenho do modelo LLaMA no benchmark TruthfulQA. • O ITI aumentou a veracidade do modelo Alpaca de 32,5% para 65,1%. | |||
| 2023-09-22 | Nascimento de um transformador: um ponto de vista da memória | ||
| • O artigo apresenta uma perspectiva baseada em memória sobre transformadores, destacando memórias associativas em matrizes de peso e seu aprendizado baseado em gradiente. • Análise empírica da dinâmica de treinamento em um modelo simplificado de transformador com dados sintéticos. • Descoberta de um rápido aprendizado global de bigramas e o surgimento mais lento de uma “cabeça de indução” para bigramas contextualizados. | |||
| 13/09/2023 | Quedas repentinas na perda: aquisição de sintaxe, transições de fase e viés de simplicidade em MLMs | ||
| • Identifica a Estrutura de Atenção Sintática (SAS) como uma propriedade emergente naturalmente em modelos de linguagem mascarados (MLMs) e seu papel na aquisição de sintaxe. • Analisa o SAS durante o treinamento e o manipula para estudar seu efeito causal nas capacidades gramaticais. • O SAS é necessário para o desenvolvimento da gramática, mas suprimi-lo brevemente melhora o desempenho do modelo. | |||
| 18/07/2023 | A interpretabilidade da análise de circuitos escala? Evidências de Capacidades de Múltipla Escolha em Chinchila | ||
| • Análise de circuito escalável aplicada a um modelo de linguagem Chinchilla 70B para compreensão de respostas a perguntas de múltipla escolha. • Atribuição de logit, visualização de padrões de atenção e patches de ativação para identificar e categorizar os principais focos de atenção. • Identificado o recurso "Enésimo item em uma enumeração" nos cabeçalhos de atenção, embora seja apenas uma explicação parcial. | |||
| 02/02/2023 | Interpretabilidade em estado selvagem: um circuito para identificação indireta de objetos em GPT-2 pequeno | ||
| • O artigo apresenta uma explicação detalhada de como o GPT-2 small realiza a identificação indireta de objetos (IOI) usando um circuito grande envolvendo 28 cabeças de atenção agrupadas em 7 classes. • Eles fizeram engenharia reversa da tarefa IOI no GPT-2 small usando intervenções e projeções causais. • O estudo demonstra que a interpretabilidade mecanicista de grandes modelos de linguagem é viável. | |||
| Data | Artigo e Resumo | Etiquetas | Ligações |
| 08/03/2022 | Cabeças de aprendizagem e indução em contexto | ||
| • O artigo identifica “cabeças de indução” em modelos Transformer, que permitem a aprendizagem no contexto, reconhecendo e copiando padrões em sequências. • Analisa padrões de atenção e cabeças de indução em diversas camadas em diferentes modelos de Transformer. • Descobriu que os cabeçotes de indução são cruciais para permitir que os Transformers generalizem e executem tarefas de aprendizagem no contexto de forma eficaz. | |||
| 2021-12-22 | Uma estrutura matemática para circuitos transformadores | ||
| • Introduz uma estrutura matemática para fazer engenharia reversa de pequenos transformadores somente de atenção, com foco na compreensão das cabeças de atenção como componentes independentes e aditivos. • Analisei transformadores de zero, uma e duas camadas para identificar o papel das cabeças de atenção no movimento e composição da informação. • Descobertas “cabeças de indução”, cruciais para aprendizagem contextual em transformadores de duas camadas. | |||
| 2021-05-18 | A hipótese das cabeças: uma abordagem estatística unificadora para a compreensão da atenção multifacetada no BERT | ||
| • O artigo propõe um novo método chamado "Atenção Esparsa" que reduz a complexidade computacional dos mecanismos de atenção ao focar seletivamente em tokens importantes. • O método foi avaliado em tarefas de tradução automática e classificação de textos. • O modelo de atenção esparsa atinge precisão comparável à atenção densa, ao mesmo tempo que reduz significativamente o custo computacional. | |||
| 01/04/2021 | Os chefes de atenção no BERT aprenderam a gramática do grupo constituinte? | ||
| • O estudo introduz um método de distância sintática para analisar a gramática constituinte em cabeçalhos de atenção BERT e RoBERTa. • A gramática do grupo constituinte foi extraída e analisada antes e depois do ajuste fino nas tarefas de SMS e NLI. • As tarefas NLI aumentam a capacidade de indução gramatical do grupo constituinte, enquanto as tarefas SMS a diminuem nas camadas superiores. | |||
| 27/11/2019 | Os cabeçalhos de atenção no BERT rastreiam dependências sintáticas? | ||
| • O artigo investiga se as cabeças de atenção individuais em Bert capturam dependências sintáticas, usando pesos de atenção para extrair as relações de dependência. • Analisou as cabeças de atenção de Bert usando o máximo de pesos de atenção e as árvores máximas de abrangência, comparando -as com árvores de dependência universais. • Algumas cabeças de atenção rastreiam dependências sintáticas específicas melhor do que as linhas de base, mas nenhuma cabeça executa a análise holística significativamente melhor. | |||
| 2019-11-01 | Transformadores esparsos adaptativamente | ||
| • Introduziu o transformador adaptativamente esparso usando alfa-entrmax para permitir a esparsidade flexível e dependente do contexto em cabeças de atenção. • Aplicado aos conjuntos de dados de tradução da máquina para avaliar a interpretabilidade e a diversidade da cabeça. • alcançaram diversas distribuições de atenção e melhor interpretabilidade sem comprometer a precisão. | |||
| 2019-08-01 | O que Bert olha? Uma análise da atenção de Bert | ||
| • O artigo apresenta métodos para analisar os mecanismos de atenção de Bert, revelando padrões que se alinham com estruturas linguísticas como sintaxe e núcleo. • Análise de cabeças de atenção, identificação de padrões sintáticos e coreferenciais e desenvolvimento de um classificador de investigação baseado em atenção. • Atenção de Bert Os chefes de atenção capturam informações sintáticas substanciais, particularmente em tarefas como identificar objetos diretos e núcleo. | |||
| 2019-07-01 | Analisando a auto-ataque de várias cabeças: cabeças especializadas fazem o trabalho pesado, o restante pode ser podado | ||
| • O artigo apresenta um novo método de poda para auto-atimento de várias cabeças que remove seletivamente cabeças menos importantes sem grande perda de desempenho. • Análise de cabeças de atenção individuais, identificação de seus papéis especializados e aplicação de um método de poda no modelo de transformador. • A poda 38 das 48 cabeças no codificador levou a apenas uma queda de pontuação de 0,15 bleu. | |||
| 2018-11-01 | Uma análise das representações do codificador na tradução de máquina baseada em transformador | ||
| • Este artigo analisa as representações internas das camadas do codificador de transformador, com foco em informações sintáticas e semânticas aprendidas pelas cabeças de auto-atendimento. • Tarefas de investigação, extração da relação de dependência e um cenário de aprendizado de transferência. • As camadas mais baixas capturam a sintaxe, enquanto camadas mais altas codificam mais informações semânticas. | |||
| 2016-03-21 | Incorporando o mecanismo de cópia no aprendizado de sequência a sequência | ||
| • Introduz um mecanismo de cópia nos modelos de sequência a sequência para permitir a cópia direta dos tokens de entrada, melhorando o manuseio de palavras raras. • Aplicado às tarefas de tradução e resumo da máquina. • alcançou melhorias substanciais na precisão da tradução, especialmente na tradução rara de palavras, em comparação com os modelos padrão de sequência-sequência. | |||
Modelo de edição:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


